Introduction: Filter vs Smoother
Consider the problem of estimating a hidden state from time-series data. A Kalman filter processes data sequentially, estimating the state at each time step using only observations up to that point. A smoother, on the other hand, estimates the state at each time step using all available observations.
- Filtering: estimation using observations up to time \(t\) → \(p(x_t | y_{1:t})\)
- Smoothing: estimation using all observations → \(p(x_t | y_{1:T})\)
Because a smoother exploits future observations as well, it always achieves estimation accuracy equal to or better than a filter. However, since it requires the entire dataset before processing, it cannot be applied in real time. Smoothing is particularly useful in batch processing and post-hoc analysis, such as trajectory re-estimation and preprocessing for parameter estimation.
This article derives the theory of the Rauch-Tung-Striebel (RTS) smoother, the most widely used fixed-interval smoother, and implements it in Python.
Related articles: Exponential Moving Average (EMA) Filter, Cubature Kalman Filter (CKF): Theory and Python Implementation, Fundamentals of Filtering Methods in Signal Processing
Kalman Filter Review
The RTS smoother takes the output of the Kalman filter forward pass as its input. We first define the linear Gaussian state-space model and briefly review the Kalman filter equations.
State-Space Model
\[ x_k = F x_{k-1} + w_{k-1}, \quad w_{k-1} \sim \mathcal{N}(0, Q) \tag{1} \]\[ y_k = H x_k + v_k, \quad v_k \sim \mathcal{N}(0, R) \tag{2} \]where \(F\) is the state transition matrix, \(H\) is the observation matrix, \(Q\) is the process noise covariance, and \(R\) is the observation noise covariance.
Prediction Step
\[ \hat{x}_{k|k-1} = F \hat{x}_{k-1|k-1} \tag{3} \]\[ P_{k|k-1} = F P_{k-1|k-1} F^T + Q \tag{4} \]Update Step
\[ K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1} \tag{5} \]\[ \hat{x}_{k|k} = \hat{x}_{k|k-1} + K_k (y_k - H \hat{x}_{k|k-1}) \tag{6} \]\[ P_{k|k} = (I - K_k H) P_{k|k-1} \tag{7} \]To run the RTS smoother, all intermediate quantities \(\hat{x}_{k|k}\), \(P_{k|k}\), \(\hat{x}_{k|k-1}\), and \(P_{k|k-1}\) from the forward pass must be stored.
RTS Smoother Derivation
The RTS smoother uses the results of the Kalman filter forward pass to perform backward recursion from time \(T\) to \(0\).
Smoother Gain
The smoother gain \(G_k\) determines the correction applied to the filter estimate \(\hat{x}_{k|k}\) to obtain the smoothed estimate \(\hat{x}_{k|T}\):
\[ G_k = P_{k|k} F^T P_{k+1|k}^{-1} \tag{8} \]This matrix is derived from the relationship between the filter covariance \(P_{k|k}\) at time \(k\) and the predicted covariance \(P_{k+1|k}\) at time \(k+1\).
Smoothed State Estimate
The smoothed state estimate is obtained by adding a correction term to the filter estimate. This correction is the difference between the future smoothed estimate and the prediction, weighted by the smoother gain:
\[ \hat{x}_{k|T} = \hat{x}_{k|k} + G_k (\hat{x}_{k+1|T} - \hat{x}_{k+1|k}) \tag{9} \]Intuitively, this propagates information about how much the future observations corrected the filter prediction \(\hat{x}_{k+1|k}\) back to time \(k\).
Smoothed Covariance
The smoothed covariance is computed as:
\[ P_{k|T} = P_{k|k} + G_k (P_{k+1|T} - P_{k+1|k}) G_k^T \tag{10} \]Since \(P_{k+1|T} - P_{k+1|k} \leq 0\) (smoothing reduces the covariance below the predicted covariance), we always have \(P_{k|T} \leq P_{k|k}\). In other words, the smoother estimate has lower uncertainty than the filter estimate.
Backward Pass Algorithm
The initial conditions are \(\hat{x}_{T|T}\) and \(P_{T|T}\) (the final results of the forward pass). Equations \((8)\)–\((10)\) are then applied in reverse order for \(k = T-1, T-2, \ldots, 0\).
Python Implementation
We implement the Kalman filter and RTS smoother using a 1D position-velocity tracking problem as an example.
State-Space Model Definition
We use a constant-velocity model with state vector \(x = [\text{position}, \text{velocity}]^T\).
import numpy as np
import matplotlib.pyplot as plt
# ---- State-space model definition ----
dt = 1.0 # sampling interval
# State transition matrix (constant velocity model)
F = np.array([[1, dt],
[0, 1]])
# Observation matrix (position only)
H = np.array([[1, 0]])
# Process noise covariance
q = 0.1
Q = q * np.array([[dt**3/3, dt**2/2],
[dt**2/2, dt]])
# Observation noise covariance
R = np.array([[1.0]])
n = 2 # state dimension
m = 1 # observation dimension
Kalman Filter (Forward Pass)
def kalman_filter(y_obs, F, H, Q, R, x0, P0):
"""Kalman filter forward pass (stores all intermediate results)"""
T = len(y_obs)
n = len(x0)
# Filtered estimates
x_filt = np.zeros((T + 1, n)) # x_{k|k}
P_filt = np.zeros((T + 1, n, n)) # P_{k|k}
# Predicted values (used by smoother)
x_pred = np.zeros((T, n)) # x_{k|k-1}
P_pred = np.zeros((T, n, n)) # P_{k|k-1}
# Initialization
x_filt[0] = x0
P_filt[0] = P0
for k in range(T):
# Prediction step (Eq. 3, 4)
x_pred[k] = F @ x_filt[k]
P_pred[k] = F @ P_filt[k] @ F.T + Q
# Update step (Eq. 5, 6, 7)
S = H @ P_pred[k] @ H.T + R
K = P_pred[k] @ H.T @ np.linalg.inv(S)
innovation = y_obs[k] - H @ x_pred[k]
x_filt[k + 1] = x_pred[k] + K @ innovation
P_filt[k + 1] = (np.eye(n) - K @ H) @ P_pred[k]
return x_filt, P_filt, x_pred, P_pred
RTS Smoother (Backward Pass)
def rts_smoother(x_filt, P_filt, x_pred, P_pred, F):
"""RTS smoother backward pass"""
T = len(x_pred)
n = x_filt.shape[1]
# Smoothed estimates
x_smooth = np.zeros((T + 1, n))
P_smooth = np.zeros((T + 1, n, n))
# Initial condition: final filter estimate
x_smooth[T] = x_filt[T]
P_smooth[T] = P_filt[T]
# Backward recursion
for k in range(T - 1, -1, -1):
# Smoother gain (Eq. 8)
G = P_filt[k] @ F.T @ np.linalg.inv(P_pred[k])
# Smoothed state estimate (Eq. 9)
x_smooth[k] = x_filt[k] + G @ (x_smooth[k + 1] - x_pred[k])
# Smoothed covariance (Eq. 10)
P_smooth[k] = P_filt[k] + G @ (P_smooth[k + 1] - P_pred[k]) @ G.T
return x_smooth, P_smooth
Simulation
np.random.seed(42)
T = 50 # number of time steps
# True initial state
x_true_init = np.array([0.0, 1.0]) # position 0, velocity 1
# Generate true states
true_states = np.zeros((T + 1, n))
true_states[0] = x_true_init
for k in range(T):
true_states[k + 1] = F @ true_states[k] + \
np.random.multivariate_normal(np.zeros(n), Q)
# Generate observations
y_obs = np.zeros((T, m))
for k in range(T):
y_obs[k] = H @ true_states[k + 1] + \
np.random.multivariate_normal(np.zeros(m), R)
# Filter initial estimate
x0 = np.array([0.0, 0.0])
P0 = np.diag([1.0, 1.0])
# Run Kalman filter
x_filt, P_filt, x_pred, P_pred = kalman_filter(y_obs, F, H, Q, R, x0, P0)
# Run RTS smoother
x_smooth, P_smooth = rts_smoother(x_filt, P_filt, x_pred, P_pred, F)
Filter vs Smoother Comparison
time = np.arange(T + 1)
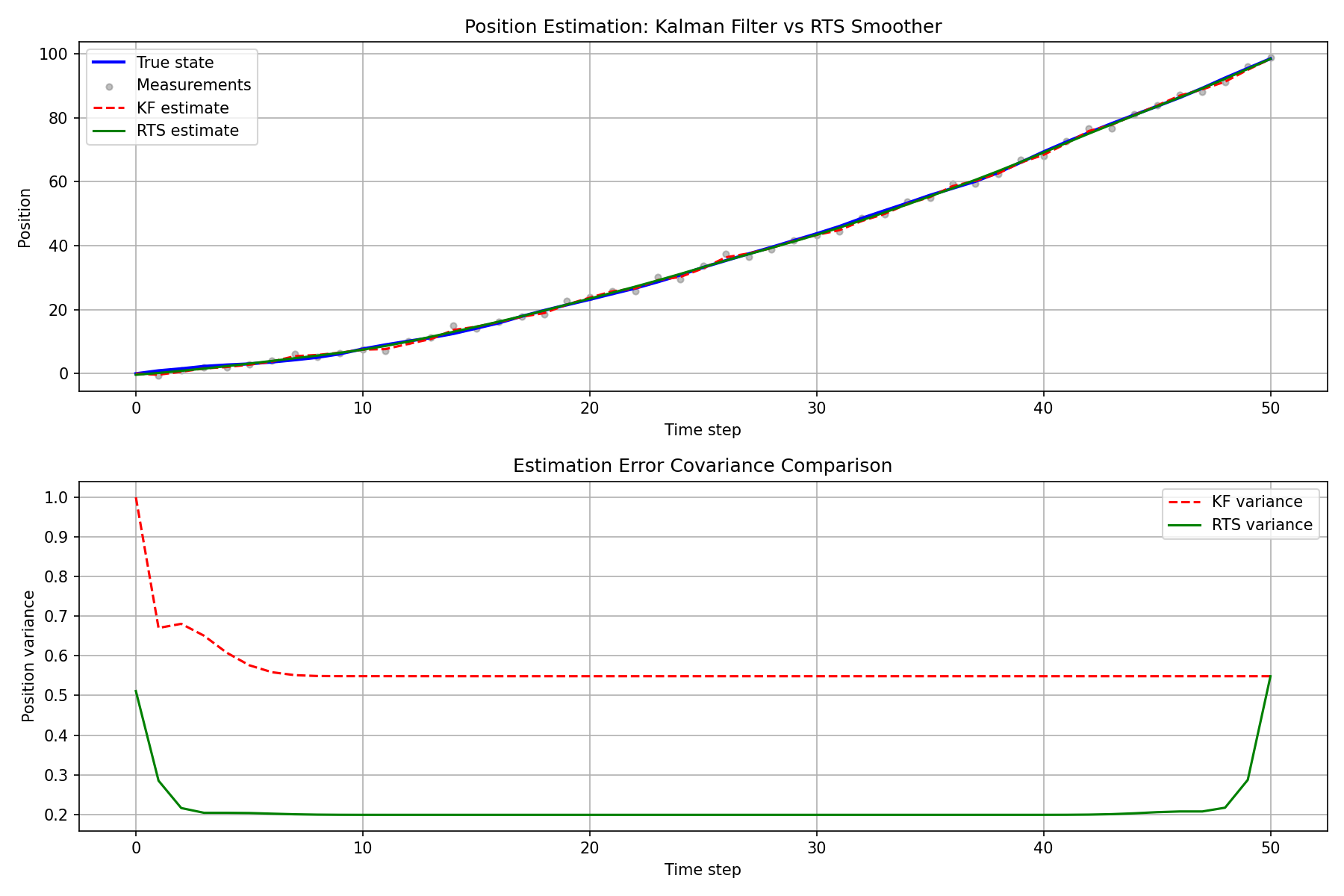
# ---- Position estimation results ----
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
plt.plot(time, true_states[:, 0], "b-", linewidth=2, label="True state")
plt.scatter(np.arange(1, T + 1), y_obs[:, 0],
c="gray", s=15, alpha=0.5, label="Measurements")
plt.plot(time, x_filt[:, 0], "r--", linewidth=1.5, label="KF estimate")
plt.plot(time, x_smooth[:, 0], "g-", linewidth=1.5, label="RTS estimate")
plt.xlabel("Time step")
plt.ylabel("Position")
plt.title("Position Estimation: Kalman Filter vs RTS Smoother")
plt.legend()
plt.grid(True)
# ---- Position estimation error covariance ----
plt.subplot(2, 1, 2)
kf_pos_var = np.array([P_filt[k, 0, 0] for k in range(T + 1)])
rts_pos_var = np.array([P_smooth[k, 0, 0] for k in range(T + 1)])
plt.plot(time, kf_pos_var, "r--", linewidth=1.5, label="KF variance")
plt.plot(time, rts_pos_var, "g-", linewidth=1.5, label="RTS variance")
plt.xlabel("Time step")
plt.ylabel("Position variance")
plt.title("Estimation Error Covariance Comparison")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("rts_smoother_result.png", dpi=150)
plt.show()
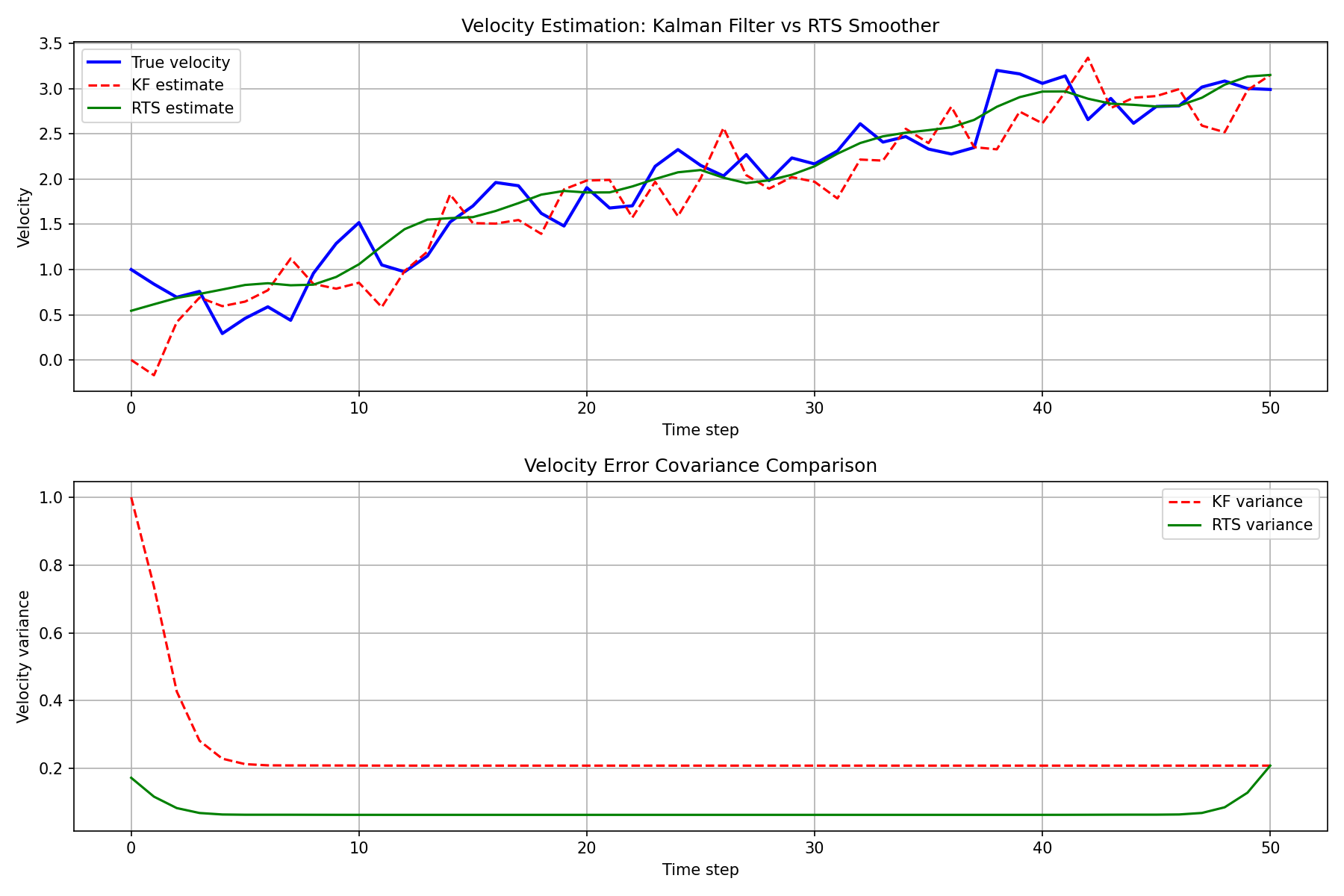
The velocity estimation (an unobserved state component) is shown below. The smoother achieves even more dramatic improvement for unobserved states.
RMSE Comparison
# Position RMSE
rmse_kf = np.sqrt(np.mean((true_states[1:, 0] - x_filt[1:, 0])**2))
rmse_rts = np.sqrt(np.mean((true_states[1:, 0] - x_smooth[1:, 0])**2))
# Velocity RMSE
rmse_kf_vel = np.sqrt(np.mean((true_states[1:, 1] - x_filt[1:, 1])**2))
rmse_rts_vel = np.sqrt(np.mean((true_states[1:, 1] - x_smooth[1:, 1])**2))
print(f"Position RMSE - KF: {rmse_kf:.4f}, RTS: {rmse_rts:.4f}")
print(f"Velocity RMSE - KF: {rmse_kf_vel:.4f}, RTS: {rmse_rts_vel:.4f}")
print(f"Position improvement: {(1 - rmse_rts / rmse_kf) * 100:.1f}%")
print(f"Velocity improvement: {(1 - rmse_rts_vel / rmse_kf_vel) * 100:.1f}%")
| Metric | Kalman Filter | RTS Smoother | Improvement |
|---|---|---|---|
| Position RMSE | 0.6540 | 0.3638 | 44.4% |
| Velocity RMSE | 0.3884 | 0.2358 | 39.3% |
The RTS smoother estimate is consistently closer to the true state than the Kalman filter estimate, with significant accuracy improvements especially away from the data endpoints. The error covariance plot also confirms that the smoother uncertainty is always less than or equal to that of the filter.
Summary
The RTS smoother achieves significant accuracy improvements over the Kalman filter by simply adding a backward pass to the forward pass, with minimal implementation overhead. For any batch-processing scenario where real-time estimation is not required, applying the RTS smoother should be the first consideration.
Note that this article focused on linear models. For nonlinear models, extensions such as the Extended Kalman Smoother, Unscented Kalman Smoother, and CKF-based smoothers are available.
Related Articles
- Kalman Filter: Theory and Python Implementation - The foundational Kalman filter that the RTS smoother extends.
- Extended Kalman Filter (EKF): Theory and Python Implementation - EKF for nonlinear models, which also serves as a basis for nonlinear smoothers.
- Unscented Kalman Filter (UKF): Nonlinear State Estimation Theory and Python Implementation - UKF, the foundation for UKF-based smoothers.
- Particle Filter Python Implementation: Comparing Resampling Methods - The particle filter that serves as the basis for particle smoothers.
- Time-Series Anomaly Detection: From Statistical Methods to Kalman Filter in Python - RTS smoother is useful as a preprocessing step for offline anomaly detection.
References
- Rauch, H. E., Tung, F., & Striebel, C. T. (1965). “Maximum likelihood estimates of linear dynamic systems.” AIAA Journal, 3(8), 1445-1450.
- Särkkä, S. (2013). Bayesian Filtering and Smoothing. Cambridge University Press.