The Cocktail Party Problem: Motivation
Picture a crowded party. Several people are talking at once, and microphones placed at different positions in the room record a blend of all the voices. No microphone picks up just one speaker — each captures a superposition of every sound source in the room.
The question is: given only the microphone recordings, can we recover the individual voices? At first glance this seems impossible, but with the right statistical assumptions about the sources it turns out to be solvable. This is the Cocktail Party Problem.
Its generalization is Blind Source Separation (BSS) — “blind” because we have no knowledge of the mixing process (microphone positions, room acoustics, etc.). The most powerful and widely used approach to BSS is Independent Component Analysis (ICA).
ICA applies far beyond audio. It is the standard tool for removing artifacts from EEG and fMRI recordings, extracting latent factors from financial time series, and separating sensor-array signals in communications.
Mathematical Formulation of Blind Source Separation
The Linear Mixing Model
Suppose there are \(n\) statistically independent source signals \(s_1(t), s_2(t), \ldots, s_n(t)\) , collected into a column vector \(\mathbf{s}(t) \in \mathbb{R}^n\) . A set of \(m\) sensors (microphones, electrodes, antennas) produces observed signals \(\mathbf{x}(t) \in \mathbb{R}^m\) via an instantaneous linear mixing model:
\[ \mathbf{x}(t) = \mathbf{A}\mathbf{s}(t) \tag{1} \]Here \(\mathbf{A} \in \mathbb{R}^{m \times n}\) is the unknown mixing matrix. Each column \(\mathbf{a}_j\) describes how source \(j\) propagates to all sensors.
The goal of ICA is to estimate an unmixing matrix \(\mathbf{W}\) from \(\mathbf{x}(t)\) alone, such that:
\[ \hat{\mathbf{s}}(t) = \mathbf{W}\mathbf{x}(t) \approx \mathbf{s}(t) \tag{2} \]When \(m = n\) (equal number of sources and sensors), ideally \(\mathbf{W} \approx \mathbf{A}^{-1}\) .
Inherent Indeterminacies
ICA cannot resolve two fundamental ambiguities:
- Scale indeterminacy: The amplitude of each recovered component cannot be determined. Scaling a column of \(\mathbf{A}\) by \(c\) and dividing the corresponding source by \(c\) leaves \(\mathbf{x}\) unchanged.
- Order indeterminacy: The ordering of the recovered components is arbitrary — any permutation of the rows of \(\mathbf{W}\) gives a valid solution.
These are intrinsic to BSS and must be handled at the interpretation stage.
Key Assumptions: Independence and Non-Gaussianity
Assumption 1: Statistical Independence
The sources \(s_i\) and \(s_j\) (\(i \neq j\) ) must be statistically independent. Independence is stronger than uncorrelatedness (zero second-order statistics); it requires that the joint density factors into the product of marginals for all orders:
\[ p(\mathbf{s}) = \prod_{i=1}^{n} p_i(s_i) \tag{3} \]Assumption 2: Non-Gaussianity
At most one source may follow a Gaussian distribution. The reason comes directly from the Central Limit Theorem.
The CLT tells us that the sum of independent random variables tends toward a Gaussian distribution. Since each observed signal \(x_i = \sum_j a_{ij} s_j\) is a weighted sum of independent sources, it is more Gaussian than any individual \(s_j\) . Conversely, directions that are less Gaussian are closer to the original sources.
ICA exploits this by searching for the directions of maximum non-Gaussianity — those directions correspond to the independent sources we want to recover.
Identifiability Theorem (Comon, 1994)
Assumptions 1 and 2 are not arbitrary conveniences — they are exactly the conditions under which Comon (1994) proved that ICA’s solution is essentially unique. Rather than positing the assumptions and hoping for the best, this theorem shows why they are necessary and sufficient.
Theorem: Let the source vector \(\mathbf{s} = (s_1, \ldots, s_n)\) have statistically independent components, at most one of which is Gaussian. Given the observation \(\mathbf{x} = \mathbf{A}\mathbf{s}\) , suppose some matrix \(\mathbf{B}\) makes the components of \(\mathbf{y} = \mathbf{B}\mathbf{x}\) mutually independent. Then
\[ \mathbf{B}\mathbf{A} = \mathbf{P}\mathbf{D} \]where \(\mathbf{P}\) is a permutation matrix and \(\mathbf{D}\) is a nonsingular diagonal matrix.
In other words, independence alone — with the non-Gaussianity caveat — pins down the mixing matrix up to permutation and scaling, which is precisely the indeterminacy described earlier.
The proof rests on the Darmois–Skitovitch theorem from classical statistics:
If two independent linear combinations of independent random variables,
\[ > Y_1 = \sum_{i} a_i X_i, \qquad Y_2 = \sum_{i} b_i X_i, > \]are themselves statistically independent, then every \(X_i\) for which both \(a_i \neq 0\) and \(b_i \neq 0\) must be Gaussian.
Applying the contrapositive: if a non-Gaussian source contributes to two different linear combinations of the observations, those two combinations cannot be independent. Hence, for every component of \(\mathbf{y} = \mathbf{B}\mathbf{A}\mathbf{s}\) to be independent, each \(y_i\) must depend on exactly one \(s_j\) (up to a scalar) — which is exactly what “\(\mathbf{B}\mathbf{A}\) is a permutation-and-scaling matrix” means.
This theorem is the rigorous justification for both the scale/order indeterminacy discussed above and the fact — covered later in “Limitations” — that two or more Gaussian sources cannot be separated at all.
Non-Gaussianity Measures: Kurtosis and Negentropy
Kurtosis
The simplest non-Gaussianity measure is the excess kurtosis:
\[ \text{kurt}(y) = E[y^4] - 3(E[y^2])^2 \tag{4} \]For a zero-mean, unit-variance (whitened) variable this simplifies to:
\[ \text{kurt}(y) = E[y^4] - 3 \tag{5} \]- Gaussian: \(\text{kurt}(y) = 0\)
- Super-Gaussian (leptokurtic, \(\text{kurt} > 0\) ): speech signals, sparse signals — sharp peak and heavy tails
- Sub-Gaussian (platykurtic, \(\text{kurt} < 0\) ): uniform distribution — flat top
Maximizing \(|\text{kurt}(y)|\) recovers the directions most different from Gaussian. However, kurtosis is highly sensitive to outliers, which is a significant practical drawback.
Negentropy
Negentropy provides a more robust non-Gaussianity measure grounded in information theory. Since the Gaussian distribution has the maximum differential entropy among all distributions with the same variance:
\[ J(y) = H(y_{\text{Gauss}}) - H(y) \geq 0 \tag{6} \]where \(H\) denotes differential entropy and \(y_{\text{Gauss}}\) has the same variance as \(y\) . \(J(y) = 0\) if and only if \(y\) is Gaussian.
Computing negentropy exactly is intractable, so Hyvärinen & Oja (2000) proposed the approximation:
\[ J(y) \approx \left[E\{G(y)\} - E\{G(\nu)\}\right]^2 \tag{7} \]where \(\nu \sim \mathcal{N}(0,1)\) and \(G\) is a non-quadratic nonlinear function. Common choices are:
\[ G_1(u) = \frac{1}{a}\log\cosh(au), \quad g_1(u) = \tanh(au) \tag{8} \] \[ G_2(u) = -\exp\!\left(-\frac{u^2}{2}\right), \quad g_2(u) = u\exp\!\left(-\frac{u^2}{2}\right) \tag{9} \]\(G_1\) with \(a \approx 1\) works well for general signals; \(G_2\) is better for super-Gaussian (sparse) sources.
FastICA Algorithm
FastICA (Hyvärinen & Oja, 1997, 2000) is a fixed-point iteration algorithm that efficiently maximizes negentropy.
Preprocessing: Whitening
Before running FastICA, the data must be whitened (sphered): transformed so that its covariance matrix equals the identity:
\[ E[\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T] = \mathbf{I} \tag{10} \]Using PCA (eigendecomposition \(\mathbf{C} = \mathbf{E}\mathbf{D}\mathbf{E}^T\) ):
\[ \tilde{\mathbf{x}} = \mathbf{D}^{-1/2}\mathbf{E}^T\mathbf{x} \tag{11} \]After whitening, the mixing matrix becomes orthogonal, reducing the search from an arbitrary \(n \times n\) matrix to a rotation matrix — a much smaller space.
Fixed-Point Iteration
To estimate a single weight vector \(\mathbf{w} \in \mathbb{R}^n\) (one ICA component):
Step 1 — Initialize: draw \(\mathbf{w}\) randomly; normalize \(\mathbf{w} \leftarrow \mathbf{w}/\|\mathbf{w}\|\) .
Step 2 — Update (equation 12):
\[ \mathbf{w} \leftarrow E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{w} \tag{12} \]where \(g = G'\) is the derivative of the chosen nonlinearity and \(g'\) its second derivative.
Step 3 — Re-normalize: \(\mathbf{w} \leftarrow \mathbf{w}/\|\mathbf{w}\|\) .
Step 4 — Convergence check: repeat until \(|\mathbf{w}_{\text{new}}^T\mathbf{w}_{\text{old}} - 1| < \epsilon\) .
This update is derived from the Newton method applied to the negentropy objective. It converges cubically in practice — far faster than gradient ascent.
Deriving Equation (12): A Newton-Method Fixed Point
Equation (12) is not handed down by fiat — it falls out of applying Newton’s method to a constrained optimization problem (Hyvärinen, 1999).
On whitened data \(\tilde{\mathbf{x}}\) (with \(E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\} = \mathbf{I}\) ), we want to maximize the negentropy approximation \(J(\mathbf{w}^T\tilde{\mathbf{x}}) \approx [E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{G(\nu)\}]^2\) . The second term is a constant independent of \(\mathbf{w}\) , and since we only care about maximizing the magnitude, the problem reduces to:
\[ \max_{\mathbf{w}} \; E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} \quad \text{s.t.} \quad E\{(\mathbf{w}^T\tilde{\mathbf{x}})^2\} = \|\mathbf{w}\|^2 = 1 \]Whitening turns the constraint \(E\{(\mathbf{w}^T\tilde{\mathbf{x}})^2\} = \mathbf{w}^T\mathbf{w}\) into the unit-sphere constraint \(\|\mathbf{w}\| = 1\) . Introduce the Lagrangian
\[ F(\mathbf{w}) = E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} - \beta(\|\mathbf{w}\|^2 - 1) \]Setting its gradient to zero gives the first-order optimality condition:
\[ \nabla_{\mathbf{w}} F(\mathbf{w}) = E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w} = \mathbf{0} \tag{12a} \]Treat this as a root-finding problem \(\mathbf{H}(\mathbf{w}) \equiv E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w} = \mathbf{0}\) and apply Newton’s method in \(\mathbf{w}\) . The Jacobian of \(\mathbf{H}\) is
\[ J_{\mathbf{H}}(\mathbf{w}) = E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\, g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{I} \]FastICA’s key simplification comes next: when \(\mathbf{w}^T\tilde{\mathbf{x}}\) is close to a true independent component, it is approximately uncorrelated with \(\tilde{\mathbf{x}}\) , so the expectation factorizes:
\[ E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\, g'(\mathbf{w}^T\tilde{\mathbf{x}})\} \approx E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\}\, E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} = E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{I} \]so the Jacobian collapses to a scalar multiple of the identity, \(J_{\mathbf{H}}(\mathbf{w}) \approx [E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta]\mathbf{I}\) , which is trivial to invert. Substituting into the Newton update
\[ \mathbf{w}_{\text{new}} = \mathbf{w} - J_{\mathbf{H}}(\mathbf{w})^{-1}\mathbf{H}(\mathbf{w}) \]gives
\[ \mathbf{w}_{\text{new}} = \mathbf{w} - \frac{E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w}}{E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta} \]Multiplying through by the denominator \([E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta]\) (harmless, since we re-normalize \(\mathbf{w}\) afterward anyway) leaves
\[ \mathbf{w}_{\text{new}} \; \propto \; E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{w} \]which is exactly equation (12). Because it is a Newton step, FastICA converges locally at a cubic-to-quadratic rate, far outpacing ordinary gradient ascent. In the cocktail-party example below, this fixed-point iteration converges in 5 iterations under the tol=1e-4 stopping criterion.
Deflation vs. Symmetric Decorrelation
When extracting multiple components, we must prevent them from converging to the same direction.
Deflation (sequential extraction): estimate components one by one. After finding \(\mathbf{w}_p\) , apply Gram–Schmidt orthogonalization:
\[ \mathbf{w}_p \leftarrow \mathbf{w}_p - \sum_{j=1}^{p-1} (\mathbf{w}_p^T \mathbf{w}_j)\mathbf{w}_j \tag{13} \]Deflation is simple but errors in early components propagate to later ones.
Symmetric decorrelation (parallel extraction): update all weight vectors simultaneously, then orthogonalize the entire weight matrix at once:
\[ \mathbf{W} \leftarrow (\mathbf{W}\mathbf{W}^T)^{-1/2}\mathbf{W} \tag{14} \]where \((\cdot)^{-1/2}\)
is the symmetric inverse square root (computed via eigendecomposition). All components are treated equally, yielding more stable estimates. This is the default in sklearn.decomposition.FastICA.
Complete Algorithm Flow
1. Center data (subtract mean); whiten to unit covariance
2. Initialize weight matrix W randomly
3. For each component (deflation) or all at once (symmetric):
a. Apply fixed-point update (eq. 12)
b. Re-normalize
c. Repeat until convergence
4. Decorrelate W (eq. 13 or eq. 14)
5. Compute estimated sources: ŝ = W x̃
PCA vs. ICA: A Clear Comparison
PCA Recap
PCA finds the directions of maximum variance by eigendecomposing the covariance matrix. The resulting principal components are uncorrelated (zero covariance) but not necessarily independent. PCA uses only second-order statistics.
The Essential Distinction
| Property | PCA | ICA |
|---|---|---|
| Statistics used | 2nd-order (covariance) | Higher-order (independence) |
| Output property | Uncorrelated | Independent |
| Gaussian sources | Works fine | Cannot separate |
| Scale / order | Sorted by variance | Indeterminate |
| Geometric meaning | Rotation to max-variance axes | Rotation to max non-Gaussian axes |
| Typical use | Dimensionality reduction, visualization | Source separation, feature extraction |
| Whitening | Output of PCA | Preprocessing for ICA |
The key insight: whitening (PCA) removes second-order dependencies; ICA removes higher-order dependencies. PCA finds axes that decorrelate the data; ICA rotates among those decorrelated axes to find the most non-Gaussian directions.
In a 2D example: PCA maps an elliptical cloud to a circle (whitening). Among all rotations of that circle, ICA chooses the one that makes the resulting marginals most non-Gaussian — which recovers the original independent sources.
Geometric Verification: PCA Stops at Whitening, ICA Rotates Further
Let’s verify the claim above with actual data rather than just words. Take two independent uniform sources \(s_1, s_2 \sim \text{Uniform}(-1, 1)\) and mix them with a non-orthogonal matrix; the observed scatter plot forms a parallelogram. Whitening this parallelogram with PCA turns it into a square — but a square still tilted relative to the axes. ICA then rotates that square further, aligning it with the coordinate axes.
import numpy as np
from sklearn.decomposition import FastICA, PCA
from itertools import permutations
np.random.seed(7)
# ---- 1. Independent uniform (non-Gaussian) sources ----
n = 3000
s1 = np.random.uniform(-1, 1, n)
s2 = np.random.uniform(-1, 1, n)
S = np.c_[s1, s2]
# ---- 2. Mix with a non-orthogonal matrix (observed data is a parallelogram) ----
A = np.array([[2.0, 1.0],
[0.5, 1.5]])
X = S @ A.T
# ---- 3. Whiten with PCA (unit variance, but axes not aligned) ----
pca = PCA(n_components=2, whiten=True)
X_white = pca.fit_transform(X)
# ---- 4. ICA rotates further to align the axes ----
ica = FastICA(n_components=2, whiten="unit-variance", random_state=7, max_iter=1000)
S_ica = ica.fit_transform(X)
# ---- Quantitative check: correlation with the true sources ----
def best_correlation(S_true, S_est):
n_comp = S_true.shape[1]
best_corr = 0.0
for perm in permutations(range(n_comp)):
corrs = [abs(np.corrcoef(S_true[:, i], S_est[:, j])[0, 1])
for i, j in enumerate(perm)]
avg = np.mean(corrs)
best_corr = max(best_corr, avg)
return best_corr
print(f"Variance of each component after PCA whitening: {X_white.var(axis=0)}")
print(f"Mean abs. correlation, PCA-whitened output vs. true sources: {best_correlation(S, X_white):.4f}")
print(f"Mean abs. correlation, ICA output vs. true sources: {best_correlation(S, S_ica):.4f}")
# ---- Plot: observed / PCA-whitened / ICA scatter plots ----
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].scatter(X[:, 0], X[:, 1], s=6, alpha=0.35, color="steelblue")
axes[0].set_title("Observed mixture x = As")
axes[0].set_xlabel("$x_1$"); axes[0].set_ylabel("$x_2$")
axes[0].set_aspect("equal"); axes[0].grid(True, alpha=0.3)
axes[1].scatter(X_white[:, 0], X_white[:, 1], s=6, alpha=0.35, color="steelblue")
axes[1].set_title("After PCA whitening\n(square, but axes not aligned)")
axes[1].set_xlabel("whitened $x_1$"); axes[1].set_ylabel("whitened $x_2$")
axes[1].set_aspect("equal"); axes[1].grid(True, alpha=0.3)
axes[2].scatter(S_ica[:, 0], S_ica[:, 1], s=6, alpha=0.35, color="crimson")
axes[2].set_title("After ICA\n(axes aligned with independent sources)")
axes[2].set_xlabel(r"$\hat{s}_1$"); axes[2].set_ylabel(r"$\hat{s}_2$")
axes[2].set_aspect("equal"); axes[2].grid(True, alpha=0.3)
plt.suptitle("PCA stops at whitening; ICA rotates further to align with independent sources")
plt.tight_layout()
plt.savefig("ica_geometry_pca_vs_ica.png", dpi=150, bbox_inches="tight")
plt.show()
Running this code produces the following actual output:
Variance of each component after PCA whitening: [0.99966667 0.99966667]
Mean abs. correlation, PCA-whitened output vs. true sources: 0.7650
Mean abs. correlation, ICA output vs. true sources: 1.0000
The variance after PCA whitening is essentially 1 (as designed), but the correlation with the true sources is only 0.7650 — variance is normalized, but the axis orientation still does not match the sources. ICA, by contrast, achieves a correlation of 1.0000 — essentially perfect recovery. In this run, ICA applied an additional rotation of about 50.4° on top of the whitened data. The figure below makes this concrete.
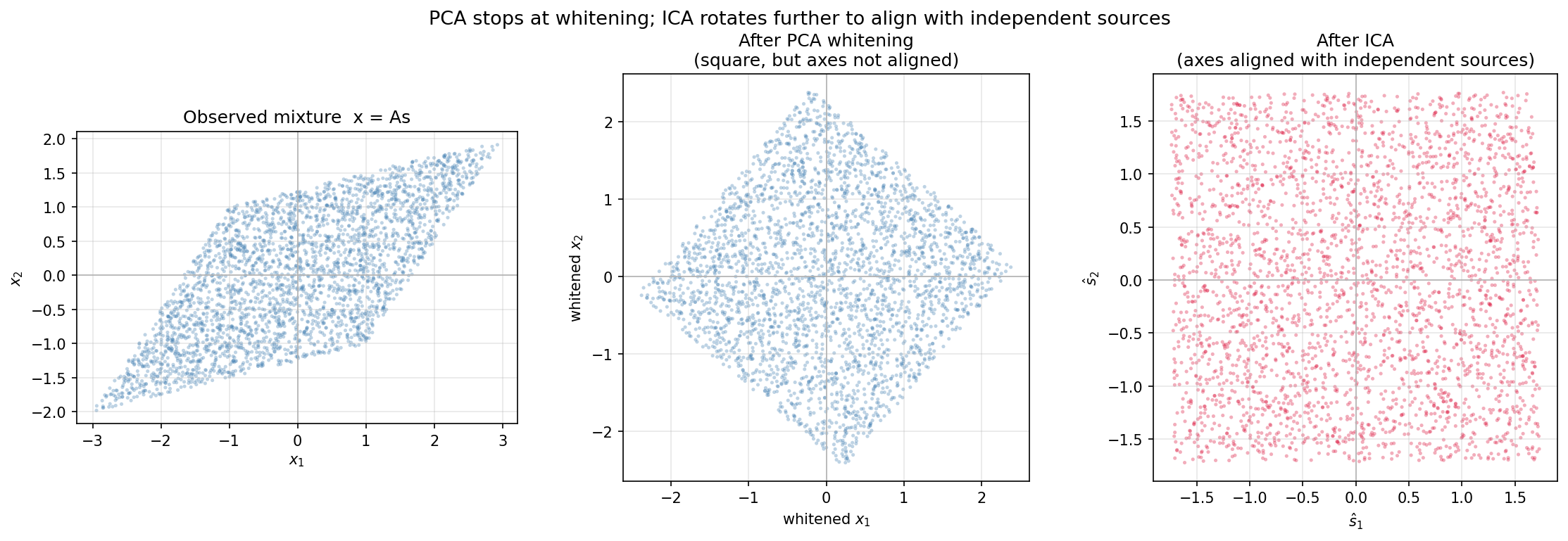
The left panel shows the observed data \(\mathbf{x} = \mathbf{A}\mathbf{s}\) as a parallelogram. The center panel shows the data after PCA whitening: the covariance is now the identity matrix and the shape is a square, but it remains tilted relative to the axes (uncorrelated, but not independent). The right panel shows the result after ICA: the square is aligned with the coordinate axes, and \(\hat{s}_1\) , \(\hat{s}_2\) are recovered as fully independent uniform variables.
Python Implementation
Cocktail Party Problem Simulation
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import FastICA, PCA
np.random.seed(42)
# ---- 1. Generate independent source signals ----
n_samples = 2000
t = np.linspace(0, 8 * np.pi, n_samples)
s1 = np.sin(t) # Sine wave
s2 = (t % (2 * np.pi) / np.pi - 1.0) # Sawtooth wave
s3 = np.sign(np.sin(2.5 * t)) # Square wave
S = np.c_[s1, s2, s3]
S /= S.std(axis=0) # Normalize to unit standard deviation
# ---- 2. Mix with a random mixing matrix ----
A = np.array([[1.0, 1.0, 1.0],
[0.5, 2.0, 1.0],
[1.5, 1.0, 2.0]])
X = S @ A.T # Observed signals: shape = (n_samples, 3)
# ---- 3. Apply FastICA ----
ica = FastICA(n_components=3, max_iter=500, tol=1e-4, random_state=42)
S_ica = ica.fit_transform(X)
# ---- 4. Apply PCA for comparison ----
pca = PCA(n_components=3)
S_pca = pca.fit_transform(X)
# ---- 5. Plot results ----
fig, axes = plt.subplots(3, 3, figsize=(15, 9))
labels = ["Sine", "Sawtooth", "Square"]
colors = ["steelblue", "darkorange", "seagreen"]
for i in range(3):
axes[0, i].plot(t[:300], S[:300, i], color=colors[i], linewidth=1.2)
axes[0, i].set_title(f"Source: {labels[i]}")
axes[0, i].set_xlim(0, t[299])
axes[0, i].grid(True, alpha=0.4)
for i in range(3):
axes[1, i].plot(t[:300], X[:300, i], color="gray", linewidth=1.2)
axes[1, i].set_title(f"Mixed signal {i + 1}")
axes[1, i].set_xlim(0, t[299])
axes[1, i].grid(True, alpha=0.4)
for i in range(3):
comp = S_ica[:300, i]
comp = comp / np.abs(comp).max() # Normalize amplitude for display
axes[2, i].plot(t[:300], comp, color="crimson", linewidth=1.2)
axes[2, i].set_title(f"ICA component {i + 1}")
axes[2, i].set_xlim(0, t[299])
axes[2, i].grid(True, alpha=0.4)
axes[0, 0].set_ylabel("Original Sources", fontsize=11)
axes[1, 0].set_ylabel("Mixed Signals", fontsize=11)
axes[2, 0].set_ylabel("ICA Recovery", fontsize=11)
plt.suptitle("Cocktail Party Problem: FastICA Source Separation", fontsize=14)
plt.tight_layout()
plt.savefig("ica_cocktail_party.png", dpi=150, bbox_inches="tight")
plt.show()
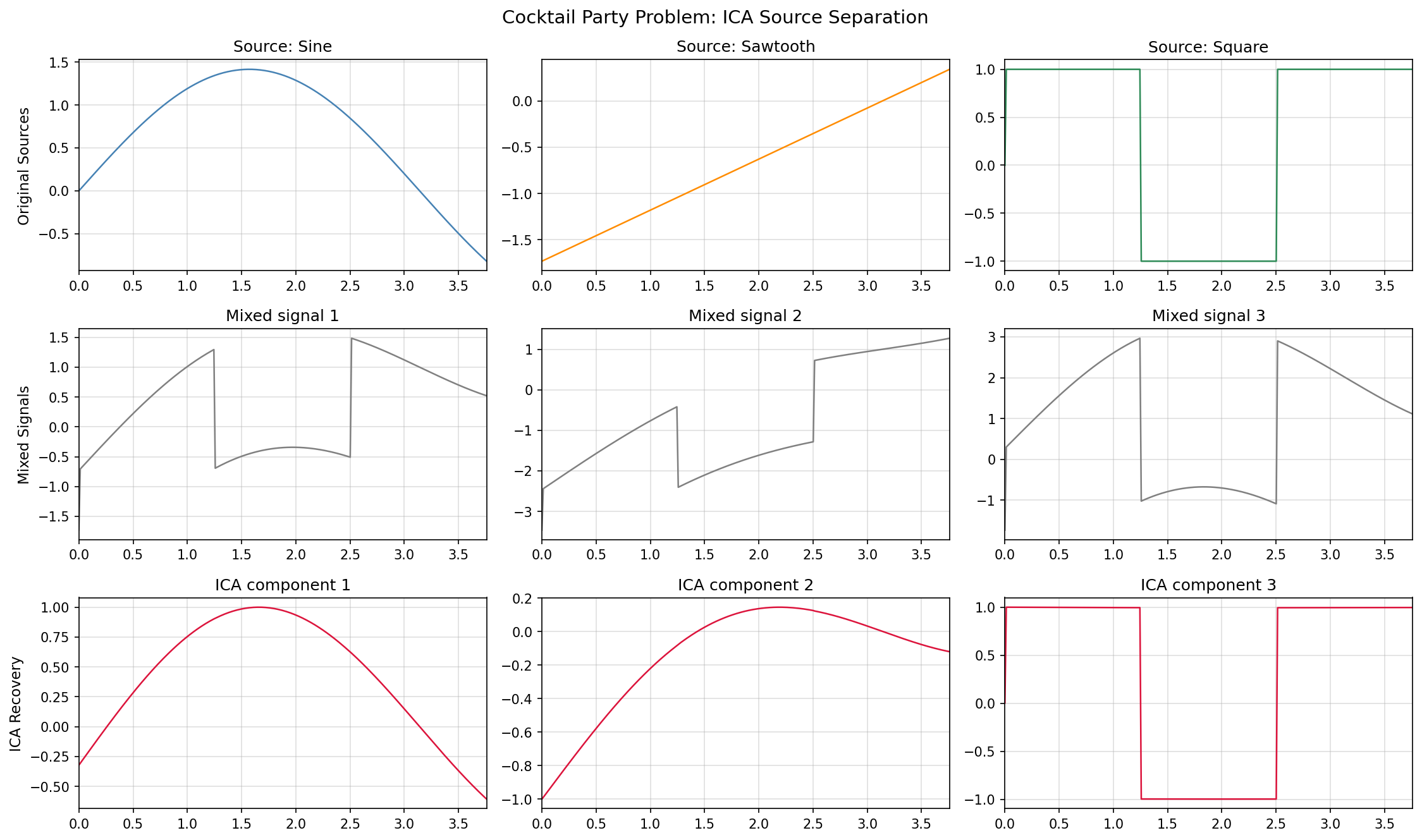
The recovered ICA components have indeterminate scale and sign, but the waveform shapes (sine, sawtooth, square) are reconstructed accurately.
Quantitative Comparison: ICA vs. PCA Recovery
from itertools import permutations
def best_correlation(S_true, S_est):
"""Average absolute correlation over the best component permutation."""
n = S_true.shape[1]
best_corr = 0.0
for perm in permutations(range(n)):
corrs = [abs(np.corrcoef(S_true[:, i], S_est[:, j])[0, 1])
for i, j in enumerate(perm)]
avg = np.mean(corrs)
if avg > best_corr:
best_corr = avg
return best_corr
corr_ica = best_correlation(S, S_ica)
corr_pca = best_correlation(S, S_pca)
print(f"ICA mean absolute correlation: {corr_ica:.4f}")
print(f"PCA mean absolute correlation: {corr_pca:.4f}")
Running the code above (reproducible via np.random.seed(42) and random_state=42) produces the following actual output:
ICA mean absolute correlation: 0.9120
PCA mean absolute correlation: 0.7708
ICA outperforms PCA, but note that even ICA’s correlation falls short of 1.0 at 0.9120 in this three-source, non-orthogonal-mixing setting. This is due to finite-sample estimation error (2,000 samples) combined with the fact that the sine source has a roughly symmetric distribution over its sampled range and therefore low kurtosis — a relatively hard source to separate. Compare this to the “Geometric Verification” example above (two independent uniform sources, correlation 1.0000): the strength of a source’s non-Gaussianity directly affects separation accuracy. PCA, which only maximizes variance, trails ICA’s recovery accuracy in both experiments.
EEG Artifact Removal
ICA is arguably the most widely used method for removing physiological artifacts from EEG data. Artifacts such as eye movements (EOG), heartbeat (ECG), and muscle activity (EMG) are statistically independent from neural signals, making ICA ideal for separating them.
np.random.seed(0)
# ---- Generate synthetic EEG-like data ----
n_samples = 3000
t = np.linspace(0, 6, n_samples) # 6 seconds
# Neural components: alpha (10 Hz) and theta (6 Hz) oscillations
alpha = np.sin(2 * np.pi * 10 * t) * 0.5
theta = np.sin(2 * np.pi * 6 * t) * 0.3
# Artifact components
eye_blink = np.zeros(n_samples)
blink_positions = [500, 1200, 2100, 2700]
for pos in blink_positions:
width = 80
idx = np.arange(max(0, pos - width), min(n_samples, pos + width))
eye_blink[idx] += np.exp(-0.5 * ((idx - pos) / 30) ** 2) * 3.0
rng = np.random.default_rng(42)
muscle = rng.standard_normal(n_samples) * 0.2 # High-frequency noise
# Mix 4 sources into 4 channels
sources = np.c_[alpha, theta, eye_blink, muscle]
A_eeg = np.array([
[1.0, 0.8, 2.0, 0.5],
[0.7, 1.0, 1.5, 0.8],
[0.5, 0.6, 1.0, 0.3],
[0.9, 0.4, 0.8, 1.0],
])
X_eeg = sources @ A_eeg.T
# ---- Decompose with FastICA ----
ica_eeg = FastICA(n_components=4, max_iter=1000, tol=1e-5, random_state=0)
components = ica_eeg.fit_transform(X_eeg)
# ---- Identify artifact component by kurtosis ----
# In practice this is done by visual inspection; here we automate it.
kurtosis_vals = []
for i in range(4):
c = components[:, i]
c_norm = (c - c.mean()) / c.std()
kurt = np.mean(c_norm**4) - 3
kurtosis_vals.append(abs(kurt))
artifact_idx = int(np.argmax(kurtosis_vals))
print(f"Artifact component: IC{artifact_idx} "
f"(|kurtosis| = {kurtosis_vals[artifact_idx]:.2f})")
# ---- Reconstruct without the artifact component ----
components_clean = components.copy()
components_clean[:, artifact_idx] = 0.0
X_clean = components_clean @ ica_eeg.mixing_.T + ica_eeg.mean_
# ---- Plot ----
fig, axes = plt.subplots(3, 1, figsize=(14, 10))
time_range = slice(0, 1000) # First 2 seconds
for ch in range(4):
offset = ch * 4
axes[0].plot(t[time_range], X_eeg[time_range, ch] + offset,
linewidth=0.8, label=f"ch {ch + 1}")
axes[0].set_title("EEG: Mixed signals (4 channels)")
axes[0].set_ylabel("Amplitude (a.u.)")
axes[0].legend(loc="upper right", fontsize=9)
axes[0].grid(True, alpha=0.3)
for i in range(4):
c = components[time_range, i]
c = c / (np.abs(c).max() + 1e-10)
label = (f"IC{i} (|kurt|={kurtosis_vals[i]:.1f})" +
(" ← artifact" if i == artifact_idx else ""))
axes[1].plot(t[time_range], c + i * 2.5, linewidth=0.8, label=label)
axes[1].set_title("ICA independent components")
axes[1].set_ylabel("Amplitude (normalized)")
axes[1].legend(loc="upper right", fontsize=9)
axes[1].grid(True, alpha=0.3)
for ch in range(4):
offset = ch * 4
axes[2].plot(t[time_range], X_clean[time_range, ch] + offset,
linewidth=0.8, label=f"ch {ch + 1}")
axes[2].set_title("EEG after artifact removal")
axes[2].set_xlabel("Time (s)")
axes[2].set_ylabel("Amplitude (a.u.)")
axes[2].legend(loc="upper right", fontsize=9)
axes[2].grid(True, alpha=0.3)
plt.suptitle("ICA-Based EEG Artifact Removal", fontsize=14)
plt.tight_layout()
plt.savefig("ica_eeg_artifact.png", dpi=150, bbox_inches="tight")
plt.show()
Running the code above (reproducible via random_state=0 and np.random.default_rng(42)) produces the following actual output:
Artifact component: IC0 (|kurtosis| = 5.46)
The absolute kurtosis of the four independent components was 5.4568 for IC0 (eye blink), 1.4990 for IC1 (alpha), 1.4854 for IC2 (theta), and 0.0141 for IC3 (muscle noise). Notice how the eye-blink component stands out with a much larger kurtosis, while the muscle noise — being close to Gaussian white noise — has kurtosis near zero. This is the flip side of the “Gaussian sources cannot be separated” limitation discussed later: because the muscle noise is nearly Gaussian, ICA cannot cleanly isolate it from the other neural components even though it isolates the eye-blink artifact easily.
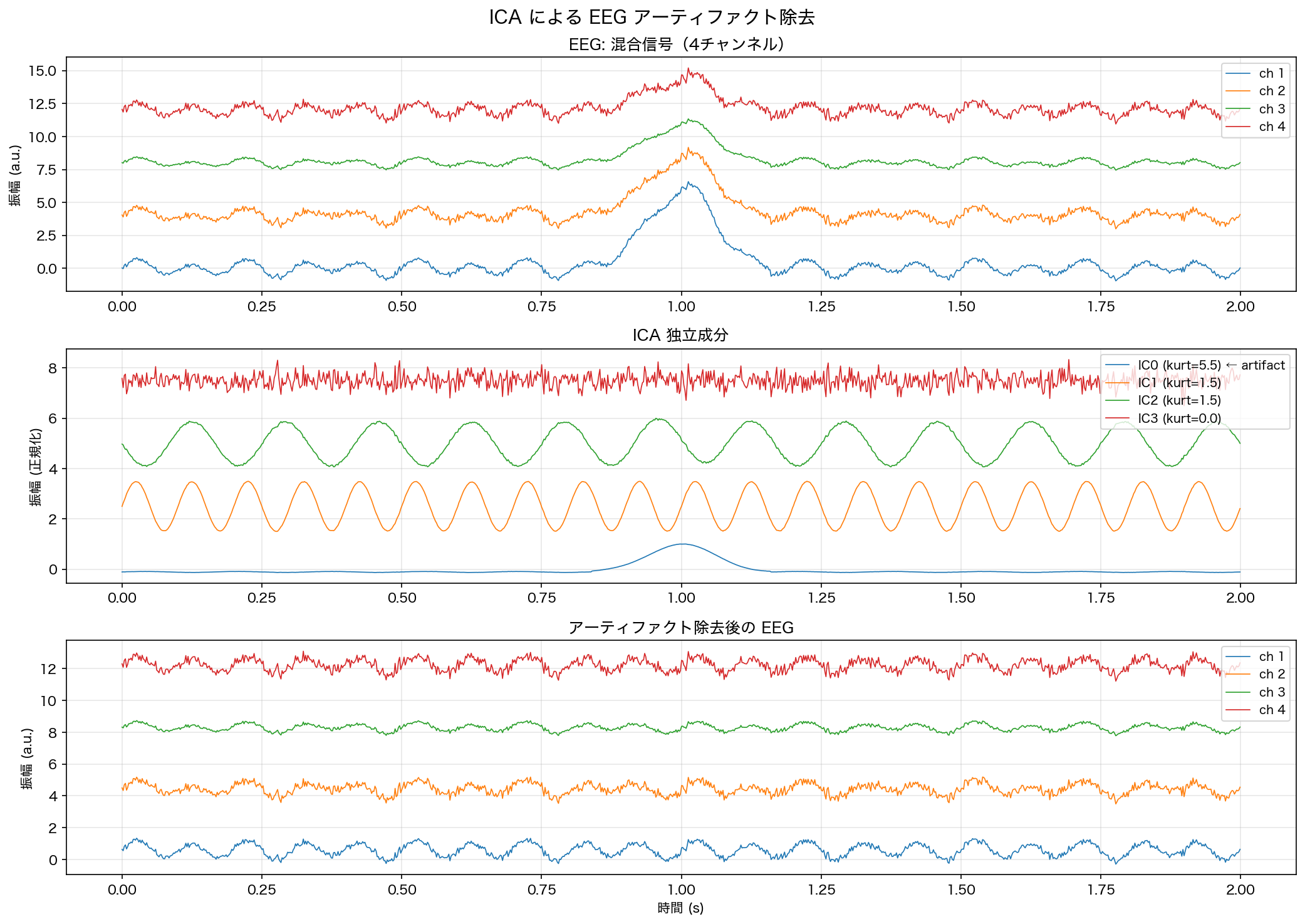
The eye-blink component (IC0) produces large-amplitude, low-frequency pulses with high kurtosis — it stands out clearly among the ICA components. Setting that component to zero and back-projecting with mixing_.T removes the artifact while preserving the neural signals. Comparing the top and bottom panels, the pulse-like bump around the 1-second mark disappears after artifact removal, while the other channels’ waveforms are largely preserved.
Limitations and When ICA Fails
ICA is powerful, but it has well-defined boundaries. Understanding them prevents misuse.
Limitation 1: Scale and Order Indeterminacy
As shown in equations (1)–(2), the recovered components have indeterminate amplitude and ordering. In practice, amplitudes are normalized and components are labeled post-hoc based on waveform shape, power spectrum, or domain knowledge.
Limitation 2: Gaussian Sources Cannot Be Separated
If all sources are Gaussian, ICA fails completely. Gaussian distributions are fully characterized by their second-order statistics. Any orthogonal rotation of a set of independent Gaussian variables yields another set of independent Gaussian variables with an identical joint distribution. There is no higher-order information to distinguish them.
Limitation 3: More Sources Than Sensors
Standard ICA requires \(n \leq m\) (number of sources \(\leq\) number of sensors). If the system is underdetermined, the problem is ill-posed. Overcomplete ICA and sparse component analysis address this at additional complexity.
Limitation 4: Linear Mixing Assumption
The model \(\mathbf{x} = \mathbf{A}\mathbf{s}\) assumes instantaneous linear mixing. Real environments involve convolutive mixing (room acoustics with reverb), nonlinear sensor responses, or propagation delays. For these cases, frequency-domain ICA, convolutive BSS, or nonlinear ICA extensions are needed.
Limitation 5: No Temporal Structure Exploited
Basic ICA treats each time step as an i.i.d. sample and ignores temporal dependencies such as autocorrelation . Algorithms like SOBI (Second-Order Blind Identification) exploit the autocorrelation structure and can even separate Gaussian sources if they have distinct temporal correlations.
Summary: When to Use ICA
| Condition | ICA applicable? |
|---|---|
| Sources are non-Gaussian | Yes |
| Sources are statistically independent | Yes |
| Mixing is linear and instantaneous | Yes |
| All sources are Gaussian | No |
| Sources > sensors (underdetermined) | Extension needed |
| Mixing is convolutive / nonlinear | Alternative needed |
Applications in Signal Processing
Neuroscience: EEG and fMRI
EEG artifact removal (as demonstrated above) is the canonical application. The ICA decomposition is standard practice in tools like EEGLAB and MNE-Python. In fMRI, spatial ICA decomposes 4D brain images into spatiotemporal components that correspond to functional networks (default mode network, visual cortex, etc.) without requiring a task-based model.
Recent research has explored deep-learning methods that replace or complement ICA for this task. Kalita, Deb, & Das (2024, Scientific Reports) proposed AnEEG, an LSTM-based GAN (generative adversarial network) for EEG artifact removal, reporting that it outperformed traditional methods — including ICA and discrete wavelet transform — on NMSE and RMSE metrics. Their work also flags a practical downside of ICA: it typically requires manually selecting which independent components are artifacts, which is time-consuming. The automatic kurtosis-based selection used in the EEG example above is exactly a lightweight response to that same problem. That said, ICA’s key advantage over deep-learning alternatives remains: it needs no labeled training data and works as a fully blind, unsupervised method.
Audio Source Separation
The original cocktail party application: separate \(n\) simultaneous speakers using \(n\) microphones. ICA also enables musical source separation (isolating instruments) and hearing aid noise suppression.
Financial Data Analysis
Applying ICA to a portfolio of asset returns extracts independent market factors — e.g., broad market moves, sector-specific risk, and idiosyncratic shocks. Unlike PCA factors (which are uncorrelated but not independent), ICA factors better capture the non-Gaussian tail behavior typical of financial returns.
Communications and Sensor Arrays
In CDMA / MIMO systems, ICA separates signals from multiple users that share the same frequency band. In seismology, ICA separates seismic wave types (P-waves, S-waves) recorded by a sensor array. Meteorological data analysis uses ICA to identify independent atmospheric circulation patterns.
Relation to Other Signal Processing Methods
Compared to adaptive filters (LMS/RLS) : adaptive filters require a reference signal (supervised), whereas ICA is fully blind (unsupervised). Wavelet transforms provide time-frequency decomposition, while ICA provides a statistical source decomposition — the two are complementary and often combined in EEG analysis.
Summary
Independent Component Analysis (ICA) is the go-to method for blind source separation when the sources are non-Gaussian and statistically independent. Here are the key takeaways:
Problem setup: Recover independent sources \(\mathbf{s}\) from observed mixtures \(\mathbf{x} = \mathbf{A}\mathbf{s}\) without knowing \(\mathbf{A}\) .
Core principle: Mixtures are more Gaussian than their sources (CLT). Finding the least Gaussian directions recovers the original sources.
Non-Gaussianity measures: Kurtosis (\(E[y^4] - 3\) ) is simple but outlier-sensitive. Negentropy is robust; FastICA maximizes its approximation using \(\tanh\) or similar nonlinearities.
FastICA: Whiten the data, then use fixed-point iteration (equation 12) to find each ICA direction. Symmetric decorrelation ensures all components are orthogonal.
ICA vs. PCA: PCA removes second-order (covariance) dependencies; ICA removes higher-order dependencies. Source separation requires ICA.
Limitations: Cannot separate Gaussian sources; scale and order are indeterminate; assumes linear mixing.
sklearn.decomposition.FastICA provides a production-ready implementation that handles EEG artifact removal and audio separation with just a few lines of code.
Related Articles
- Adaptive Filters (LMS/RLS): Theory and Python Implementation — Supervised signal separation using a reference signal; contrast with ICA’s blind approach.
- Wavelet Transform: Fundamentals and Applications — Time-frequency analysis tool frequently combined with ICA in EEG pipelines.
- Autocorrelation and Power Spectral Density — Temporal structure that ICA ignores but SOBI exploits.
- Time Series Anomaly Detection Methods — ICA-extracted independent components can serve as features for anomaly detection.
References
- Hyvärinen, A., & Oja, E. (2000). Independent component analysis: algorithms and applications. Neural Networks, 13(4–5), 411–430.
- Hyvärinen, A. (1999). Fast and robust fixed-point algorithms for independent component analysis. IEEE Transactions on Neural Networks, 10(3), 626–634.
- Bell, A. J., & Sejnowski, T. J. (1995). An information-maximization approach to blind separation and blind deconvolution. Neural Computation, 7(6), 1129–1159.
- Comon, P. (1994). Independent component analysis, a new concept? Signal Processing, 36(3), 287–314.
- Hyvärinen, A., Karhunen, J., & Oja, E. (2001). Independent Component Analysis. John Wiley & Sons.
- Makeig, S., Bell, A. J., Jung, T. P., & Sejnowski, T. J. (1996). Independent component analysis of electroencephalographic data. Advances in Neural Information Processing Systems, 8, 145–151.
- Kalita, B., Deb, N., & Das, D. (2024). AnEEG: leveraging deep learning for effective artifact removal in EEG data. Scientific Reports, 14, 24234.