情報理論は、情報の定量化、圧縮、通信に関する数学的な理論です。機械学習では、モデルの性能評価や正則化など、様々な場面でその概念が応用されます。
情報量
ある事象 \(x\) が起きたことを知ったときに得られる「情報量」 \(h(x)\) は、その事象がどれだけ「珍しい」か、つまり、その事象の起こる確率 \(p(x)\) がどれだけ低いかによって定義されます。
情報量は、以下の性質を満たすように定義するのが自然です。
- 加法性: 独立な2つの事象 \(x, y\) を観測したときの情報量は、それぞれを個別に観測したときの情報量の和に等しい。
\(h(x, y) = h(x) + h(y)\) - 独立性: 独立な事象の同時確率は、それぞれの確率の積で表される。 \(p(x, y) = p(x)p(y)\)
この2つの性質から、情報量は確率の対数を用いて定義するのが合理的であることがわかります。確率 \(p(x)\) は1以下の値をとるため、情報量が非負になるように負号をつけます。
\[ h(x) = -\log_2 p(x) \]情報の単位は、対数の底として2を用いた場合、ビット (bit) となります。
エントロピー
エントロピーは、ある確率変数 \(X\) が生成する情報の平均情報量を表します。これは、情報量 \(h(x)\) を確率分布 \(p(x)\) で期待値をとることで計算されます。
\[ H[X] = \mathbb{E}\_{p(x)}[h(x)] = -\sum_x p(x) \log_2 p(x) \]エントロピーは、確率変数の「不確実性」や「予測の難しさ」の度合いと解釈できます。
- エントロピーが低い: 分布が特定の少数の値に集中している(ピークが鋭い)状態。結果が予測しやすいため、不確実性は低い。
- エントロピーが高い: 分布が多くの値にわたって広がっている(一様に近い)状態。結果が予測しにくいため、不確実性は高い。
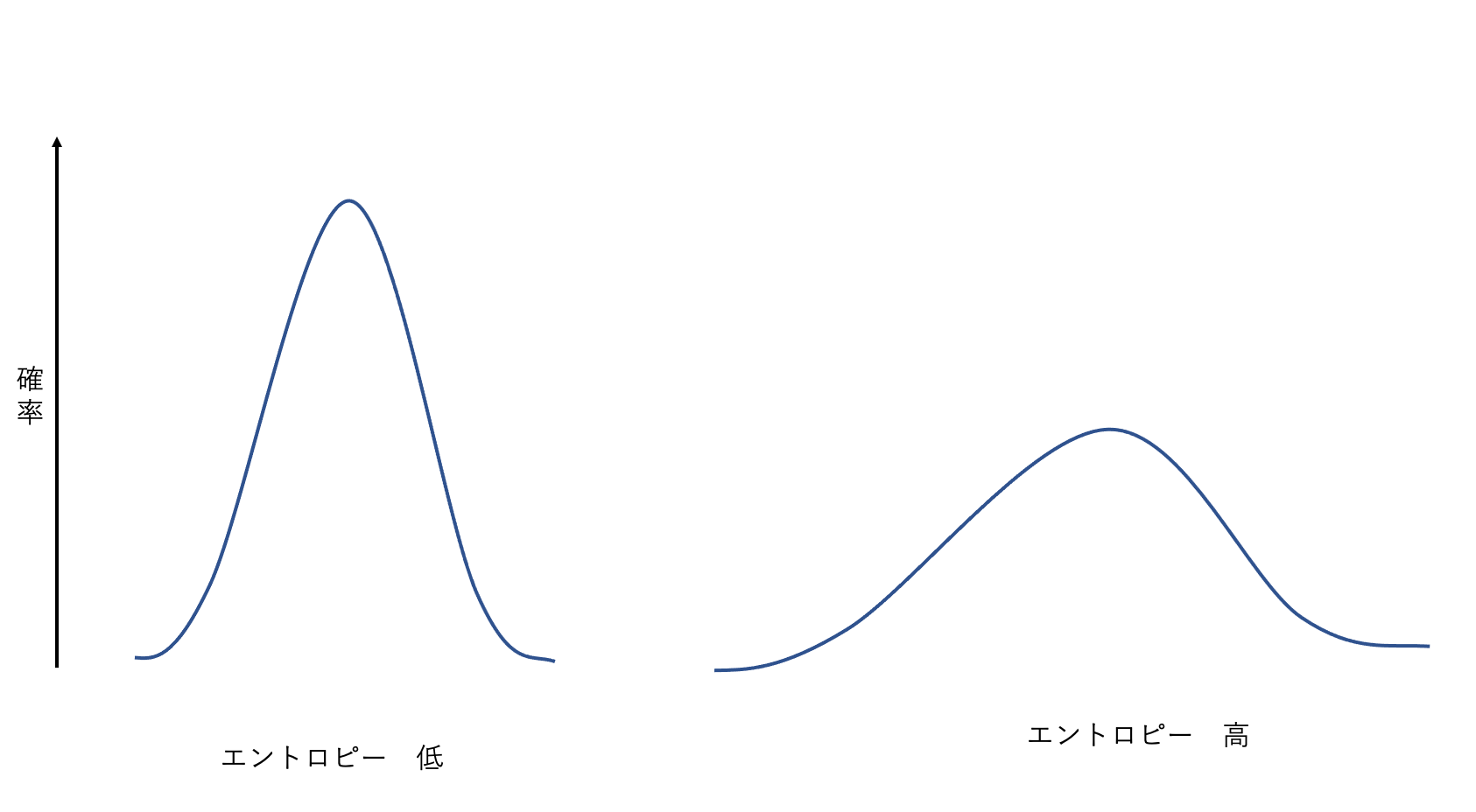
ノイズなし符号化定理によれば、エントロピーは、ある確率変数の値を誤りなく送信するために必要なビット数の下限を与えます。例えば、出現確率が不均一な文字を符号化する場合、よく出現する文字には短い符号を、稀にしか出現しない文字には長い符号を割り当てることで、平均符号長をエントロピーに近づけることができます。
微分エントロピー
連続確率変数に対してエントロピーを拡張したものが微分エントロピーです。
\[ H[X] = -\int p(x) \ln p(x) dx \]注意: 微分エントロピーは、離散の場合とは異なり、負の値をとることがあり、情報の絶対量を表すものではありません。
微分エントロピーの最大化
ある制約の下で微分エントロピーを最大化する分布を考えると、その確率変数の性質がわかります。例えば、平均 \(\mu\) と分散 \(\sigma^2\) が固定されているという制約の下で微分エントロピーを最大化する分布は、ガウス分布になります。
\[ p(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\lbrace-\frac{(x-\mu)^2}{2\sigma^2}\rbrace \]ガウス分布の微分エントロピーは次式で与えられます。
\[ H[X] = \frac{1}{2} \{1 + \ln(2\pi\sigma^2)\} \]この式から、エントロピーは分散 \(\sigma^2\) が大きいほど(分布の広がりが大きいほど)高くなることがわかります。
条件付きエントロピーと相互情報量
条件付きエントロピー
2つの確率変数 \(X, Y\) の同時分布 \(p(x, y)\) を考えます。\(X=x\) であることがわかった上で、\(Y\) の不確実性がどれだけ残っているかを表すのが条件付きエントロピーです。
\[ H[Y|X] = -\iint p(x, y) \ln p(y|x) dy dx \]これらは、エントロピーの連鎖律として知られる以下の関係を満たします。
\[ H[X, Y] = H[Y|X] + H[X] \]これは、「\(X\)と\(Y\)を特定するための情報量は、\(X\)を特定するための情報量と、\(X\)が与えられた下で\(Y\)を特定するために必要な追加の情報量の和に等しい」と解釈できます。
相対エントロピー(カルバック・ライブラー・ダイバージェンス)
ある未知の真の分布 \(p(x)\) を、モデル \(q(x)\) で近似することを考えます。このとき、2つの分布の「隔たり」を測る尺度として相対エントロピー、またはKLダイバージェンスが用いられます。
\[ KL(p||q) = -\int p(x) \ln \lbrace \frac{q(x)}{p(x)} \rbrace dx \]KLダイバージェンスには以下の重要な性質があります。
- \(KL(p||q) \ge 0\)
- \(p(x) = q(x)\) のとき、またそのときに限り \(KL(p||q) = 0\)
この性質から、KLダイバージェンスは2つの分布間の「距離」のような尺度として解釈できます(ただし、対称性 \(KL(p||q) \neq KL(q||p)\) を満たさないため、数学的な距離ではありません)。
KLダイバージェンス最小化と最尤推定
データが未知の分布 \(p(x)\) から生成されているとき、それをパラメータ \(\theta\) を持つモデル \(q(x|\theta)\) で近似する場合、両者のKLダイバージェンスを最小化する \(\theta\) を見つけることが目標となります。
\(KL(p||q)\) の式を展開すると、
\[ KL(p||q) = -\int p(x) \ln q(x|\theta) dx + \int p(x) \ln p(x) dx \]第2項は真の分布のエントロピーであり、\(\theta\) には依存しません。したがって、\(KL(p||q)\) を最小化することは、第1項、すなわち対数尤度の期待値を最大化することと等価です。
データセット \({x_n}\) が与えられた場合、この期待値はデータの平均で近似できるため、結果的にKLダイバージェンスの最小化は、尤度の最大化(最尤推定)と等価になります。
相互情報量
2つの確率変数 \(X, Y\) がどれだけ強く依存しているか、一方を知ることで他方の不確実性がどれだけ減少するかを表す尺度が相互情報量です。
これは、同時分布 \(p(x, y)\) と、変数が独立だと仮定した場合の分布 \(p(x)p(y)\) との間のKLダイバージェンスとして定義されます。
\[ I[X, Y] \equiv KL(p(x, y) || p(x)p(y)) = \iint p(x, y) \ln ( \frac{p(x, y)}{p(x)p(y)} ) dx dy \]相互情報量は、エントロピーを用いて以下のように表現することもできます。
\[ I[X, Y] = H[X] - H[X|Y] = H[Y] - H[Y|X] \]これは、「\(Y\)を知ることで減少する\(X\)の不確実性の量」と解釈できます。
参考
- C.M. ビショップ, パターン認識と機械学習 上, 丸善出版 (2012)