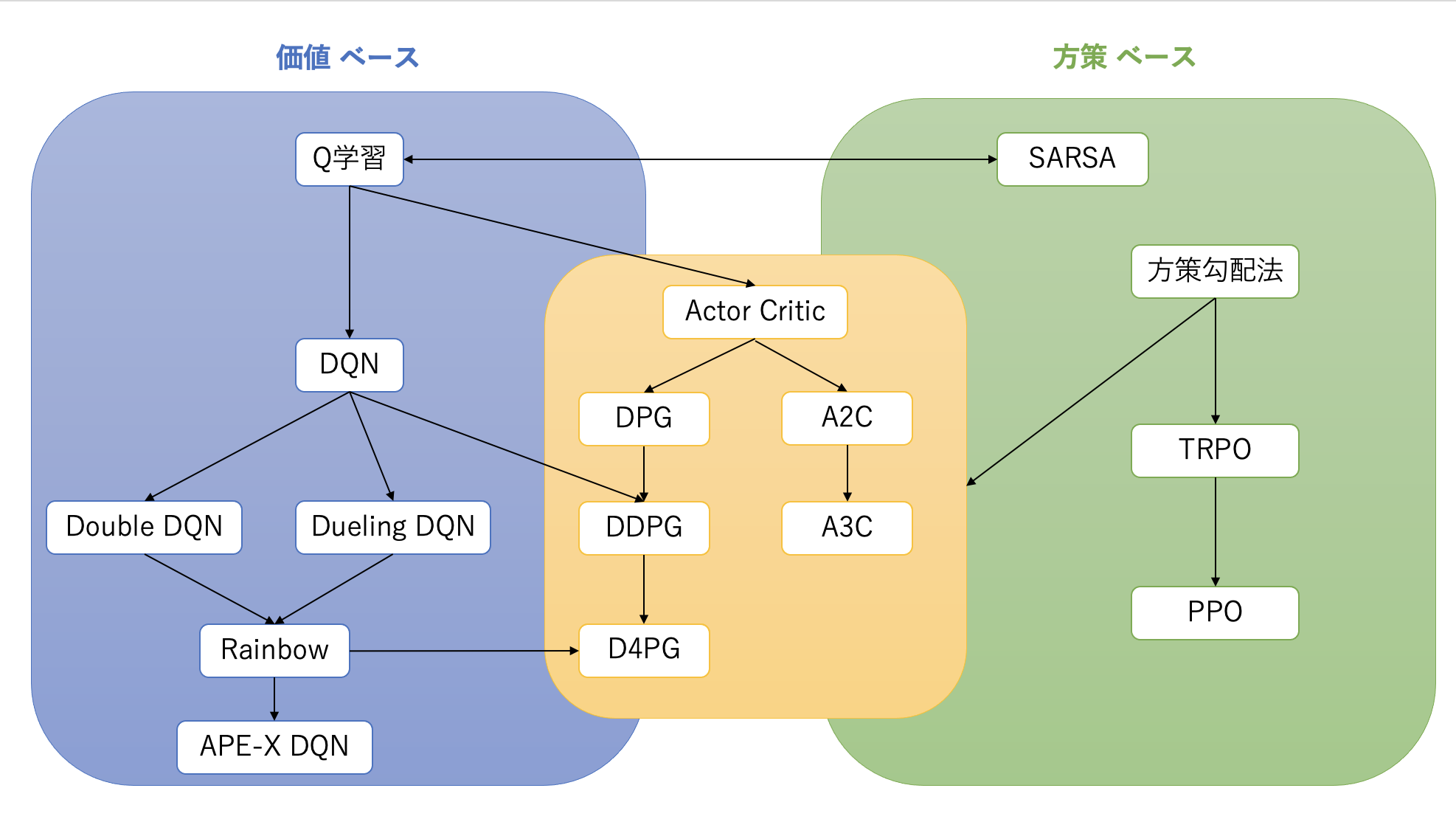
ニューラルネットワーク(DNN)を強化学習に適用した手法は、大きく分けて「価値ベース」、「方策ベース」、そしてその両方を組み合わせた「Actor-Critic」の3つの系統に分類されます。
Actor-Critic系アルゴリズム
Actor-Critic法は、方策(Actor)と価値関数(Critic)を同時に学習する手法です。
Asynchronous Advantage Actor-Critic (A3C)
A3Cは、A2C(Advantage Actor-Critic)を非同期的に拡張したものです。複数のエージェントがそれぞれ異なる環境で並行して経験を収集し、学習を行います。
- 非同期学習: 各エージェントは、中央のグローバルネットワークからパラメータをコピーし、自身の環境で経験を収集しながら勾配を計算します。その後、計算した勾配をグローバルネットワークに非同期的に適用して更新します。
- Experience Replayとの比較: Experience Replayが単一のエージェントが収集した経験をバッファに貯めて学習するのに対し、A3Cは複数のエージェントが異なる環境で同時に経験を収集することで、経験の多様性を確保します。これにより、経験間の相関が低減され、学習が安定します。
- A2Cの誕生: A3Cの発表後、非同期性が必ずしも性能向上に寄与しないことが示され、同期的に複数のエージェントから勾配を集めて更新するA2Cが提案されました。A2CはA3Cよりも実装がシンプルで、同等以上の性能を発揮することが多いです。
Deep Deterministic Policy Gradient (DDPG)
DDPGは、連続行動空間に対応したActor-Criticアルゴリズムです。DQNが離散行動空間に特化していたのに対し、DDPGは連続的な行動を出力できます。
- 決定論的方策: Actorが行動確率の分布を出力するのではなく、状態から直接、決定論的な行動を出力します。
- Experience Replayの利用: DQNと同様にExperience Replayを利用して学習の安定化を図ります。
- ターゲットネットワーク: DQNと同様に、学習の安定化のためにターゲットネットワーク(ActorとCriticの両方に)を使用します。
- TD誤差の利用: CriticはTD誤差を用いて価値関数を更新し、その情報がActorの方策更新に利用されます。
Deterministic Policy Gradient (DPG)
DPGはDDPGの基礎となるアルゴリズムで、決定論的方策の勾配を計算する手法です。DDPGは、このDPGに深層学習とDQNの安定化技術(Experience Replay, ターゲットネットワーク)を組み合わせたものです。
方策勾配系アルゴリズム
方策勾配法は、方策のパラメータを直接更新することで、期待報酬を最大化します。しかし、学習が不安定になりやすいという課題があります。
Trust Region Policy Optimization (TRPO)
TRPOは、方策勾配法の学習の安定性を向上させるための手法の一つです。方策を更新する際に、更新前の方策から大きく離れすぎないように**信頼領域(Trust Region)**という制約を設けます。
- 制約: 更新後の方策 \(\pi_\theta\) と更新前の方策 \(\pi_{\theta_{old}}\) の間のKLダイバージェンスが、ある閾値 \(\delta\) 以下になるように制約をかけます。 \[ \mathbb{E}_{s \sim d^{\pi_{\theta*{old}}}}[KL[\pi*{\theta*{old}}(\cdot|s),\pi*\theta(\cdot|s)]] ] \le \delta \]
- 目的関数: この制約の下で、アドバンテージ関数 \(A_t\) を用いた目的関数を最大化します。 \[ \max*\theta \mathbb{E}*{s*t, a_t \sim \pi*{\theta*{old}}}\left[\frac{\pi*\theta(a*t|s_t)}{\pi*{\theta*{old}}(a_t|s_t)} A_t\right] \] ここで \(\frac{\pi*\theta(a*t|s_t)}{\pi*{\theta\_{old}}(a_t|s_t)}\) は確率比と呼ばれ、更新前後の行動選択確率の比を表します。
TRPOは、理論的な保証がある一方で、実装が複雑であるという課題があります。
Proximal Policy Optimization (PPO)
PPOは、TRPOの性能を維持しつつ、実装をよりシンプルにしたアルゴリズムです。TRPOのような複雑な制約最適化問題を解く代わりに、目的関数に**クリッピング(Clipping)**という操作を導入します。
- クリッピング: 確率比 \(\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\) が、ある範囲(例: \([1-\epsilon, 1+\epsilon]\))に収まるように制限します。この範囲を超えた場合は、その値がクリップされます。 \[ L^{CLIP}(\theta) = \mathbb{E}_{s_t, a_t \sim \pi_{\theta*{old}}}\left[\min\left(\frac{\pi*\theta(a*t|s_t)}{\pi*{\theta*{old}}(a_t|s_t)} A_t, \text{clip}\left(\frac{\pi*\theta(a*t|s_t)}{\pi*{\theta\_{old}}(a_t|s_t)}, 1-\epsilon, 1+\epsilon\right) A_t\right)\right] \] この目的関数を最大化することで、方策の更新が安定し、TRPOと同等かそれ以上の性能を発揮することが示されています。PPOは、その実装の容易さと高い性能から、現在最も広く利用されている強化学習アルゴリズムの一つです。
参考
- 久保隆宏, Pythonで学ぶ強化学習 入門から実践まで, 翔泳社 (2019)