ベイズ最適化とは
ベイズ最適化(Bayesian Optimization)は、評価コストの高いブラックボックス関数の大域的最適化のための手法です。以下のような問題に適しています:
\[ \mathbf{x}^* = \arg\min_{\mathbf{x} \in \mathcal{X}} f(\mathbf{x}) \tag{1} \]ここで \(f\) は解析的な勾配が得られず、1回の評価に大きなコスト(時間・費用)がかかる関数です。典型的な応用例として、機械学習モデルのハイパーパラメータ最適化、実験計画、材料探索などがあります。
ベイズ最適化は以下の2つの要素で構成されます:
- 代理モデル(Surrogate Model): 目的関数を近似する確率モデル(通常はガウス過程)
- 獲得関数(Acquisition Function): 次に評価すべき点を決定する関数
少数の観測データから代理モデルを構築し、獲得関数を最大化する点を逐次的に選択することで、効率的に最適解を探索します。
ガウス過程回帰
カーネル関数
ガウス過程(Gaussian Process, GP)は、関数の事前分布を定義する確率モデルです。GPは平均関数 \(m(\mathbf{x})\) とカーネル関数 \(k(\mathbf{x}, \mathbf{x}')\) で特徴付けられます:
\[ f(\mathbf{x}) \sim \mathcal{GP}(m(\mathbf{x}), k(\mathbf{x}, \mathbf{x}')) \tag{2} \]最も広く使われるカーネルはRBF(Radial Basis Function)カーネル(二乗指数カーネルとも呼ばれる)です:
\[ k(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \exp\left(-\frac{\|\mathbf{x} - \mathbf{x}'\|^2}{2l^2}\right) \tag{3} \]ここで \(\sigma_f^2\) は出力の分散、\(l\) は長さスケールパラメータです。\(l\) が大きいほど関数は滑らかになります。
事後分布
\(n\) 個の観測データ \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) が与えられたとき、新しい入力 \(\mathbf{x}_*\) での予測分布は以下のようになります。観測ノイズ \(\sigma_n^2\) を仮定すると:
\[ \mu(\mathbf{x}_*) = \mathbf{k}_*^T (\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1} \mathbf{y} \tag{4} \]\[ \sigma^2(\mathbf{x}_*) = k(\mathbf{x}_*, \mathbf{x}_*) - \mathbf{k}_*^T (\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1} \mathbf{k}_* \tag{5} \]ここで:
- \(\mathbf{K}\) は \(n \times n\) のカーネル行列で \(K_{ij} = k(\mathbf{x}_i, \mathbf{x}_j)\)
- \(\mathbf{k}_* = [k(\mathbf{x}_1, \mathbf{x}_*), \ldots, k(\mathbf{x}_n, \mathbf{x}_*)]^T\)
- \(\mathbf{y} = [y_1, \ldots, y_n]^T\)
式(4)は予測平均、式(5)は予測の不確実性を表します。データが密な領域では \(\sigma^2\) が小さくなり、データが少ない領域では大きくなります。
獲得関数
獲得関数は「次にどこを評価すべきか」を決定します。予測平均(活用)と予測分散(探索)のバランスをとることが重要です。
Expected Improvement(EI)
現在の最良値 \(f(\mathbf{x}^+)\) からの改善量の期待値を最大化します:
\[ \text{EI}(\mathbf{x}) = \mathbb{E}[\max(f(\mathbf{x}^+) - f(\mathbf{x}), 0)] \tag{6} \]ガウス過程の予測分布を用いると、EIは解析的に計算できます:
\[ \text{EI}(\mathbf{x}) = (\mu(\mathbf{x}^+) - \mu(\mathbf{x}) - \xi) \Phi(Z) + \sigma(\mathbf{x}) \phi(Z) \tag{7} \]\[ Z = \frac{\mu(\mathbf{x}^+) - \mu(\mathbf{x}) - \xi}{\sigma(\mathbf{x})} \tag{8} \]ここで \(\Phi\) と \(\phi\) はそれぞれ標準正規分布の累積分布関数と確率密度関数、\(\xi \geq 0\) は探索を促進するパラメータです。最小化問題の場合、\(f(\mathbf{x}^+)\) は現在の最小観測値です。
Upper Confidence Bound(UCB)
予測平均から予測標準偏差のスケーリングを引いたものを最小化します(最小化問題の場合はLower Confidence Bound):
\[ \text{UCB}(\mathbf{x}) = \mu(\mathbf{x}) - \kappa \sigma(\mathbf{x}) \tag{9} \]\(\kappa > 0\) は探索と活用のトレードオフを制御します。\(\kappa\) が大きいほど探索的になります。
Probability of Improvement(PI)
現在の最良値を改善する確率を最大化します:
\[ \text{PI}(\mathbf{x}) = \Phi\left(\frac{\mu(\mathbf{x}^+) - \mu(\mathbf{x}) - \xi}{\sigma(\mathbf{x})}\right) \tag{10} \]PIは計算が簡単ですが、改善量の大きさを考慮しないため、局所解に収束しやすい欠点があります。
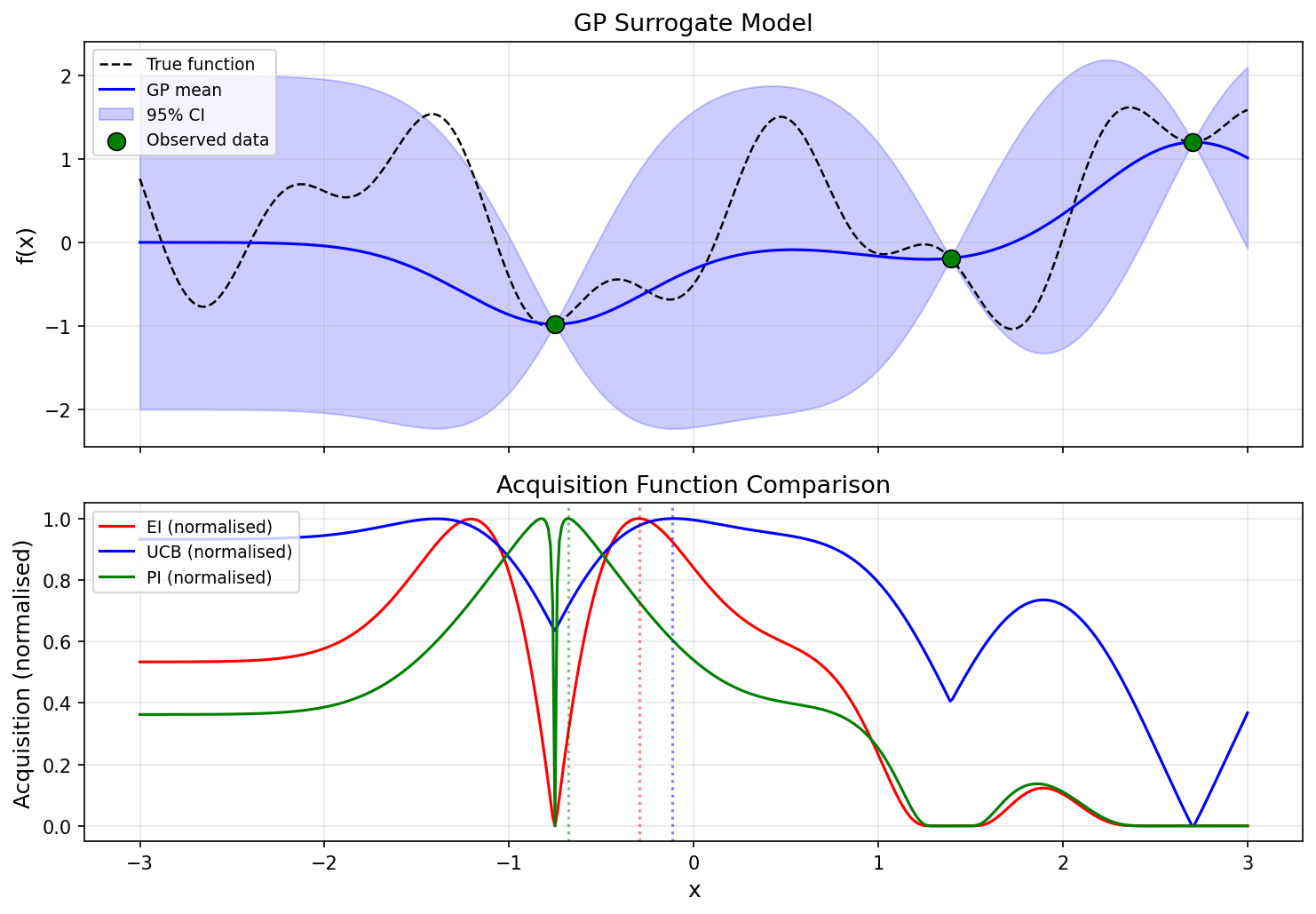
以下の図は、同じGPサロゲートモデルに対して3つの獲得関数がどのように異なる探索戦略を示すかを比較したものです。
Python実装
ガウス過程クラス
NumPyとSciPyを用いてガウス過程回帰をスクラッチで実装します。
import numpy as np
from scipy.stats import norm
class GaussianProcess:
def __init__(self, length_scale=1.0, signal_var=1.0, noise_var=1e-6):
self.l = length_scale
self.sf2 = signal_var
self.sn2 = noise_var
self.X_train = None
self.y_train = None
self.K_inv = None
def kernel(self, X1, X2):
"""RBFカーネル(式3)"""
dist_sq = np.sum(X1**2, axis=1, keepdims=True) \
- 2.0 * X1 @ X2.T \
+ np.sum(X2**2, axis=1)
return self.sf2 * np.exp(-0.5 * dist_sq / self.l**2)
def fit(self, X, y):
"""観測データでGPを学習"""
self.X_train = X.copy()
self.y_train = y.copy()
K = self.kernel(X, X) + self.sn2 * np.eye(len(X))
self.K_inv = np.linalg.inv(K)
def predict(self, X_new):
"""新しい点での予測平均と予測分散(式4, 5)"""
k_star = self.kernel(self.X_train, X_new)
mu = k_star.T @ self.K_inv @ self.y_train
var = self.sf2 - np.diag(k_star.T @ self.K_inv @ k_star)
var = np.maximum(var, 1e-10)
return mu, var
獲得関数の実装
def expected_improvement(mu, var, y_best, xi=0.01):
"""Expected Improvement(式7, 8)"""
sigma = np.sqrt(var)
with np.errstate(divide="ignore", invalid="ignore"):
Z = (y_best - mu - xi) / sigma
ei = (y_best - mu - xi) * norm.cdf(Z) + sigma * norm.pdf(Z)
ei[sigma < 1e-10] = 0.0
return ei
def upper_confidence_bound(mu, var, kappa=2.0):
"""UCB(最小化用:LCB)(式9)"""
sigma = np.sqrt(var)
return mu - kappa * sigma
def probability_of_improvement(mu, var, y_best, xi=0.01):
"""Probability of Improvement(式10)"""
sigma = np.sqrt(var)
with np.errstate(divide="ignore", invalid="ignore"):
Z = (y_best - mu - xi) / sigma
pi = norm.cdf(Z)
pi[sigma < 1e-10] = 0.0
return pi
ベイズ最適化ループ
def bayesian_optimization(f, bounds, n_init=3, n_iter=15,
acq_func="ei"):
"""ベイズ最適化のメインループ"""
# 初期点のランダムサンプリング
X_init = np.random.uniform(bounds[0], bounds[1],
size=(n_init, 1))
y_init = np.array([f(x) for x in X_init]).reshape(-1)
gp = GaussianProcess(length_scale=0.5, signal_var=1.0,
noise_var=1e-6)
X_sample = X_init.copy()
y_sample = y_init.copy()
# 最適化ループ
for i in range(n_iter):
gp.fit(X_sample, y_sample)
# 候補点での獲得関数の評価
X_cand = np.linspace(bounds[0], bounds[1], 500).reshape(-1, 1)
mu, var = gp.predict(X_cand)
y_best = np.min(y_sample)
if acq_func == "ei":
acq = expected_improvement(mu, var, y_best)
x_next = X_cand[np.argmax(acq)]
elif acq_func == "ucb":
acq = upper_confidence_bound(mu, var)
x_next = X_cand[np.argmin(acq)]
elif acq_func == "pi":
acq = probability_of_improvement(mu, var, y_best)
x_next = X_cand[np.argmax(acq)]
# 新しい点を評価して追加
y_next = f(x_next.reshape(1, -1))
X_sample = np.vstack([X_sample, x_next.reshape(1, -1)])
y_sample = np.append(y_sample, y_next)
return X_sample, y_sample, gp
1D最適化デモ
テスト関数としてノイズのない非凸関数を使い、ベイズ最適化の挙動を確認します。
import matplotlib.pyplot as plt
def test_function(x):
"""複数の極小値を持つテスト関数"""
return np.sin(3 * x) + x**2 * 0.1 - 0.5 * np.cos(7 * x)
np.random.seed(42)
bounds = (-3.0, 3.0)
X_sample, y_sample, gp = bayesian_optimization(
test_function, bounds, n_init=3, n_iter=12, acq_func="ei"
)
# 最適化結果のプロット
X_plot = np.linspace(bounds[0], bounds[1], 300).reshape(-1, 1)
y_true = np.array([test_function(x) for x in X_plot])
mu, var = gp.predict(X_plot)
sigma = np.sqrt(var)
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
# GP代理モデル
axes[0].plot(X_plot, y_true, "k--", label="True function")
axes[0].plot(X_plot, mu, "b-", label="GP mean")
axes[0].fill_between(X_plot.ravel(), mu - 2*sigma, mu + 2*sigma,
alpha=0.2, color="blue", label="95% CI")
axes[0].scatter(X_sample[:3], y_sample[:3],
c="green", s=80, zorder=5, label="Initial points")
axes[0].scatter(X_sample[3:], y_sample[3:],
c="red", s=80, zorder=5, label="BO samples")
axes[0].set_xlabel("x")
axes[0].set_ylabel("f(x)")
axes[0].set_title("Bayesian Optimization with GP Surrogate")
axes[0].legend()
axes[0].grid(True)
# EI獲得関数
acq_ei = expected_improvement(mu, var, np.min(y_sample))
axes[1].plot(X_plot, acq_ei, "r-", label="EI")
axes[1].set_xlabel("x")
axes[1].set_ylabel("EI(x)")
axes[1].set_title("Expected Improvement")
axes[1].legend()
axes[1].grid(True)
plt.tight_layout()
plt.savefig("bayesian_optimization_result.png", dpi=150)
plt.show()
best_idx = np.argmin(y_sample)
print(f"Best x: {X_sample[best_idx].item():.4f}")
print(f"Best f(x): {y_sample[best_idx]:.4f}")
print(f"Total evaluations: {len(y_sample)}")
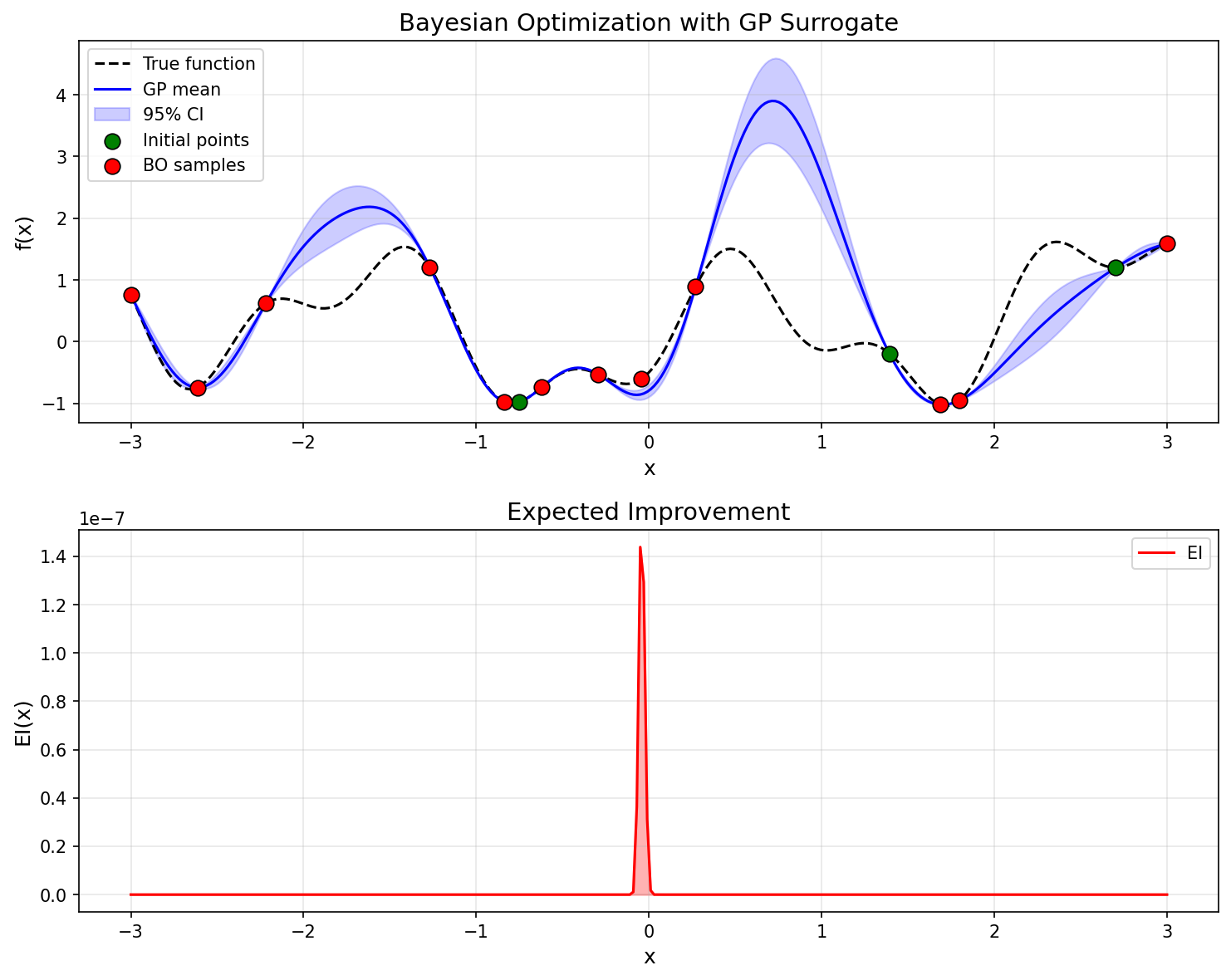
GPの予測平均(青線)が真の関数(黒点線)に近づいていく様子と、信頼区間(青い帯)がデータ付近で狭くなる様子が確認できます。EIは不確実性が高く改善が期待される領域で大きな値をとり、探索と活用のバランスを自動的に調整します。
CEM・MPPIとの比較
ベイズ最適化はクロスエントロピー法(CEM)やMPPIとは異なるアプローチの最適化手法です。以下に比較をまとめます。
| ベイズ最適化 | CEM | MPPI | |
|---|---|---|---|
| 評価バジェット | 非常に少数(数十回) | 中程度(数百〜数千回) | 中程度(数百〜数千回) |
| 並列化 | 逐次的(バッチ拡張可) | 高い | 高い |
| 勾配不要 | はい | はい | はい |
| 代理モデル | あり(GP) | なし | なし |
| 探索戦略 | 獲得関数による | エリートサンプル選択 | 指数関数的重み付け |
| 主な用途 | ハイパーパラメータ最適化 | 組合せ最適化、計画 | リアルタイム制御 |
| スケーラビリティ | 低次元(〜20次元) | 高次元も可能 | 高次元も可能 |
- ベイズ最適化は1回の評価が高コストな場合に最適です。代理モデルにより少ない評価回数で効率的に探索しますが、ガウス過程の計算コストにより高次元への適用が難しくなります。
- CEMはサンプルベースの手法で、多数の評価が可能な場合に有効です。エリートサンプルのハードな選択により分布を更新します。
- MPPIはCEMと同様にサンプルベースですが、ソフトな重み付けにより全サンプルの情報を活用します。リアルタイムの制御問題に適しています。
関連記事
- 焼きなまし法(Simulated Annealing)の理論とPython実装 - 温度パラメータによる確率的探索を行うメタヒューリスティクスを解説しています。
- 遺伝的アルゴリズム(GA)の理論とPython実装 - 進化的計算に基づくブラックボックス最適化手法を解説しています。
- 確率的勾配降下法からAdamまで - 勾配ベースの最適化手法。ベイズ最適化はハイパーパラメータチューニングに使われます。
- MCMC入門:メトロポリス・ヘイスティングス法とギブスサンプリング - ベイズ最適化の背景にあるベイズ推論の計算手法を解説しています。
参考文献
- Rasmussen, C. E., & Williams, C. K. I. (2006). Gaussian Processes for Machine Learning. MIT Press.
- Shahriari, B., et al. (2016). “Taking the Human Out of the Loop: A Review of Bayesian Optimization.” Proceedings of the IEEE, 104(1), 148-175.
- Snoek, J., Larochelle, H., & Adams, R. P. (2012). “Practical Bayesian Optimization of Machine Learning Algorithms.” NeurIPS 2012.
- Brochu, E., Cora, V. M., & de Freitas, N. (2010). “A Tutorial on Bayesian Optimization of Expensive Cost Functions.” arXiv:1012.2599.