粒子フィルタとは
粒子フィルタ(パーティクルフィルタ)は、逐次モンテカルロ法(Sequential Monte Carlo, SMC)に基づく非線形フィルタリング手法です。状態の事後分布を多数の重み付きサンプル(粒子)で近似することで、ガウス分布の仮定を必要とせず、任意の非線形・非ガウスシステムに適用できます。
Cubature Kalman Filter(CKF)や、Unscented変換(U変換)に基づく Unscented Kalman Filter(UKF)はガウス近似に基づくため、事後分布が多峰性を持つ場合や強い非線形性がある場合には推定精度が低下します。粒子フィルタはこのような場合にも有効な手段です。
粒子フィルタはクロスエントロピー法(CEM)と同じくモンテカルロサンプリングを基盤とする手法ですが、CEMが最適化問題を対象とするのに対し、粒子フィルタは時系列の状態推定を対象とします。
アルゴリズムの概要
状態空間モデル
以下の非線形状態空間モデルを考えます:
\[ x_k = f(x_{k-1}) + w_{k-1}, \quad w_{k-1} \sim p_w \]\[ y_k = h(x_k) + v_k, \quad v_k \sim p_v \]ここで \(f\) は状態遷移関数、\(h\) は観測関数、\(w_{k-1}\) と \(v_k\) はそれぞれプロセスノイズと観測ノイズです。ノイズ分布 \(p_w, p_v\) はガウス分布である必要はありません。
逐次モンテカルロの枠組み
粒子フィルタは \(N\) 個の粒子 \(\{x_k^{(i)}, w_k^{(i)}\}_{i=1}^{N}\) で事後分布 \(p(x_k | y_{1:k})\) を近似します。各ステップは以下の3つのフェーズからなります。
1. 予測(Prediction): 各粒子を状態遷移モデルに従って伝播させます:
\[ x_k^{(i)} \sim p(x_k | x_{k-1}^{(i)}) \]実装上は、\(x_k^{(i)} = f(x_{k-1}^{(i)}) + w_{k-1}^{(i)}\) としてプロセスノイズを加えます。
2. 重み更新(Weight Update): 新しい観測 \(y_k\) に基づき、各粒子の尤度を計算して重みを更新します:
\[ w_k^{(i)} \propto p(y_k | x_k^{(i)}) \]3. 正規化(Normalization): 重みの総和が1になるように正規化します:
\[ \tilde{w}_k^{(i)} = \frac{w_k^{(i)}}{\sum_{j=1}^{N} w_k^{(j)}} \]正規化された重みを用いて、状態の推定値は以下で計算されます:
\[ \hat{x}_k = \sum_{i=1}^{N} \tilde{w}_k^{(i)} x_k^{(i)} \]有効サンプルサイズと縮退
粒子フィルタの大きな課題は**重みの縮退(weight degeneracy)**です。時間が経過するにつれて、ほとんどの粒子の重みが0に近づき、少数の粒子だけが大きな重みを持つようになります。
この縮退の度合いを定量化するのが**有効サンプルサイズ(Effective Sample Size, ESS)**です:
\[ N_{\text{eff}} = \frac{1}{\sum_{i=1}^{N} (\tilde{w}_k^{(i)})^2} \]\(N_{\text{eff}}\) は1から \(N\) の値をとり、すべての重みが等しい場合(縮退なし)に \(N\) となります。\(N_{\text{eff}}\) が閾値(例えば \(N/2\))を下回ったときにリサンプリングを実行することで、縮退を緩和します。
def effective_sample_size(weights):
"""有効サンプルサイズの計算"""
return 1.0 / np.sum(weights ** 2)
リサンプリング手法
リサンプリングでは、重みの大きい粒子を複製し、重みの小さい粒子を除去することで、粒子集合を再構成します。以下に3つの代表的な手法を紹介します。
系統的リサンプリング(Systematic Resampling)
系統的リサンプリングは、一つの乱数 \(u_0\) を生成し、等間隔に配置された点で累積分布関数(CDF)をサンプリングします。計算量が \(O(N)\) で、分散が小さいため実用上最もよく使われます。
def systematic_resampling(weights):
"""系統的リサンプリング"""
N = len(weights)
positions = (np.random.random() + np.arange(N)) / N
cumsum = np.cumsum(weights)
indices = np.zeros(N, dtype=int)
i, j = 0, 0
while i < N:
if positions[i] < cumsum[j]:
indices[i] = j
i += 1
else:
j += 1
return indices
残差リサンプリング(Residual Resampling)
残差リサンプリングは、まず各粒子を \(\lfloor N \tilde{w}^{(i)} \rfloor\) 回確定的に複製し、残りの粒子数を残差重みに基づいて確率的にサンプリングします。確定的な複製が含まれるため、純粋にランダムなサンプリングよりも分散が小さくなります。
def residual_resampling(weights):
"""残差リサンプリング"""
N = len(weights)
indices = []
# 確定的な複製
num_copies = (N * weights).astype(int)
for i in range(N):
indices.extend([i] * num_copies[i])
# 残差の処理
residual_weights = N * weights - num_copies
residual_weights /= residual_weights.sum()
num_remaining = N - len(indices)
if num_remaining > 0:
cumsum = np.cumsum(residual_weights)
# 残差部分に系統的リサンプリングを適用
positions = (np.random.random() + np.arange(num_remaining)) / num_remaining
i, j = 0, 0
while i < num_remaining:
if positions[i] < cumsum[j]:
indices.append(j)
i += 1
else:
j += 1
return np.array(indices)
層化リサンプリング(Stratified Resampling)
層化リサンプリングは、\([0, 1)\) 区間を \(N\) 等分し、各区間内で独立に一様乱数を生成してCDFをサンプリングします。系統的リサンプリングと似ていますが、各区間で独立な乱数を使う点が異なります。
def stratified_resampling(weights):
"""層化リサンプリング"""
N = len(weights)
positions = (np.random.random(N) + np.arange(N)) / N
cumsum = np.cumsum(weights)
indices = np.zeros(N, dtype=int)
i, j = 0, 0
while i < N:
if positions[i] < cumsum[j]:
indices[i] = j
i += 1
else:
j += 1
return indices
| 特性 | 系統的 | 残差 | 層化 |
|---|---|---|---|
| 計算量 | O(N) | O(N) | O(N) |
| 分散 | 低 | 最低 | 低 |
| 乱数生成回数 | 1 | 残余分のみ | N |
| 決定的成分 | なし | あり(整数コピー) | なし |
非線形システムでのデモ
ベンチマークモデル
粒子フィルタの性能を評価するために、広く使われている一変量非定常成長モデル(Univariate Nonstationary Growth Model)を使用します。このモデルは強い非線形性を持ち、ガウス近似に基づくフィルタでは対応が困難です。
状態遷移モデル:
\[ x_k = \frac{x_{k-1}}{2} + \frac{25 x_{k-1}}{1 + x_{k-1}^2} + 8\cos(1.2k) + w_k, \quad w_k \sim \mathcal{N}(0, \sigma_w^2) \]観測モデル:
\[ y_k = \frac{x_k^2}{20} + v_k, \quad v_k \sim \mathcal{N}(0, \sigma_v^2) \]このモデルの特徴は、観測関数 \(h(x) = x^2/20\) が偶関数であるため、正と負の状態値を区別できず、事後分布が双峰性を持つことがある点です。
粒子フィルタの実装
import numpy as np
import matplotlib.pyplot as plt
# ---- モデルの定義 ----
sigma_w = np.sqrt(10.0) # プロセスノイズの標準偏差
sigma_v = np.sqrt(1.0) # 観測ノイズの標準偏差
def state_transition(x, k):
"""状態遷移関数"""
return x / 2.0 + 25.0 * x / (1.0 + x ** 2) + 8.0 * np.cos(1.2 * k)
def observation(x):
"""観測関数"""
return x ** 2 / 20.0
def log_likelihood(y, x):
"""対数尤度 log p(y|x)"""
diff = y - observation(x)
return -0.5 * (diff ** 2) / (sigma_v ** 2)
# ---- 粒子フィルタ本体 ----
def particle_filter(y_obs, N_particles, resample_fn, resample_threshold=0.5):
"""
粒子フィルタの実行
Parameters
----------
y_obs : array, 観測値の系列
N_particles : int, 粒子数
resample_fn : callable, リサンプリング関数
resample_threshold : float, ESS閾値(N_particlesに対する比率)
Returns
-------
x_est : array, 状態推定値の系列
ess_history : array, ESSの履歴
"""
T = len(y_obs)
threshold = resample_threshold * N_particles
# 初期化:事前分布からサンプリング
particles = np.random.normal(0, np.sqrt(5.0), N_particles)
weights = np.ones(N_particles) / N_particles
x_est = np.zeros(T)
ess_history = np.zeros(T)
for k in range(T):
# 予測:状態遷移 + プロセスノイズ
particles = state_transition(particles, k + 1) \
+ sigma_w * np.random.randn(N_particles)
# 重み更新:対数尤度で計算し、オーバーフローを防ぐ
log_w = log_likelihood(y_obs[k], particles)
log_w -= np.max(log_w) # 数値安定化
weights = np.exp(log_w)
weights /= np.sum(weights)
# 状態推定
x_est[k] = np.sum(weights * particles)
# ESS計算
ess = effective_sample_size(weights)
ess_history[k] = ess
# リサンプリング(ESS閾値ベース)
if ess < threshold:
indices = resample_fn(weights)
particles = particles[indices]
weights = np.ones(N_particles) / N_particles
return x_est, ess_history
シミュレーションの実行
np.random.seed(42)
T = 100 # タイムステップ数
N_particles = 500 # 粒子数
# 真の状態と観測の生成
x_true = np.zeros(T)
y_obs = np.zeros(T)
x_true[0] = 0.1 # 初期状態
for k in range(1, T):
x_true[k] = state_transition(x_true[k - 1], k) \
+ sigma_w * np.random.randn()
for k in range(T):
y_obs[k] = observation(x_true[k]) + sigma_v * np.random.randn()
# 3種類のリサンプリング手法で粒子フィルタを実行
resamplers = {
"Systematic": systematic_resampling,
"Residual": residual_resampling,
"Stratified": stratified_resampling,
}
results = {}
for name, fn in resamplers.items():
np.random.seed(42) # 公平な比較のため乱数シードを統一
x_est, ess_hist = particle_filter(y_obs, N_particles, fn)
rmse = np.sqrt(np.mean((x_true - x_est) ** 2))
results[name] = {"estimate": x_est, "ess": ess_hist, "rmse": rmse}
print(f"{name}: RMSE = {rmse:.4f}")
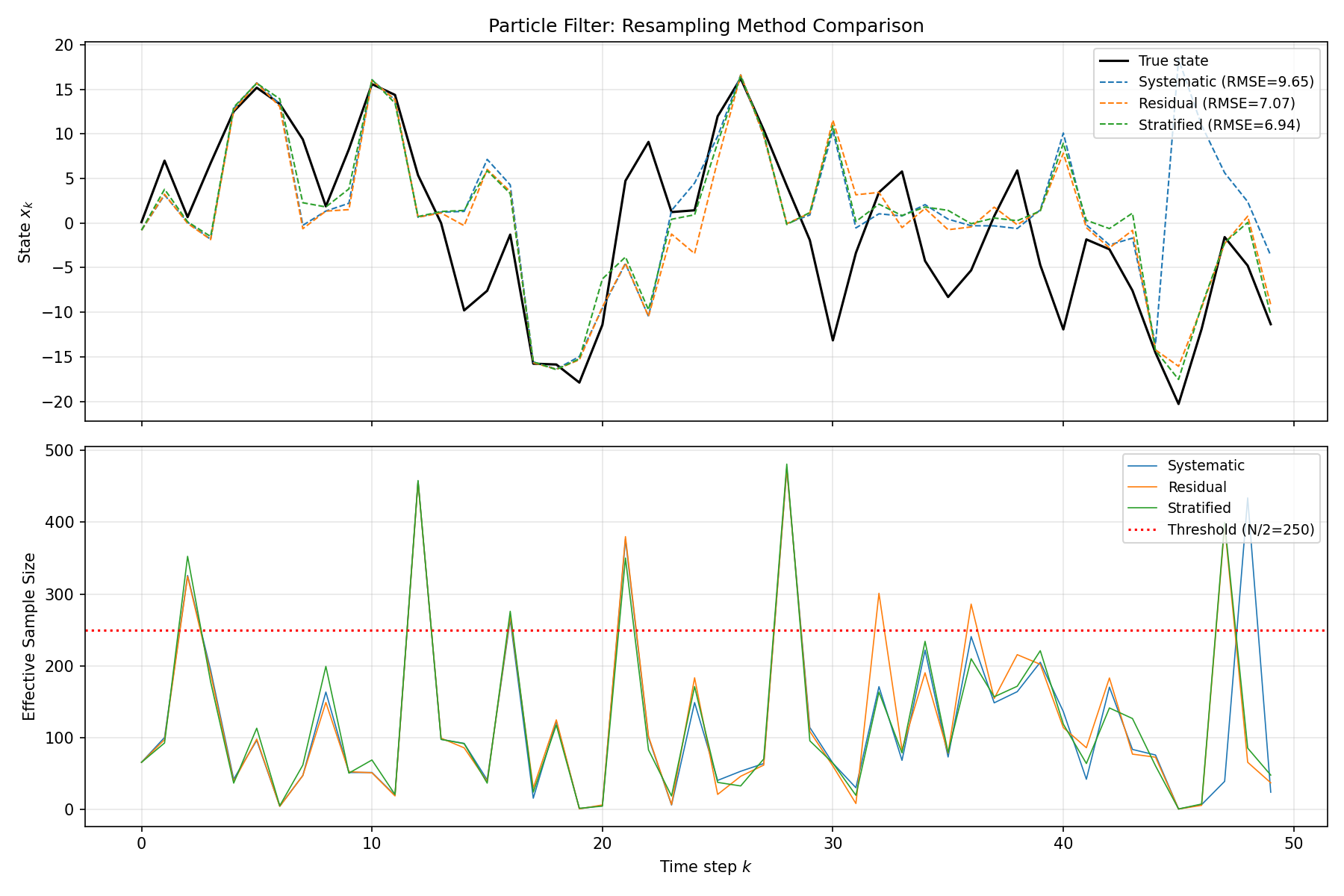
結果の可視化
fig, axes = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
# 状態推定の比較
axes[0].plot(x_true, "k-", linewidth=1.5, label="True state")
colors = {"Systematic": "tab:blue", "Residual": "tab:orange",
"Stratified": "tab:green"}
for name, res in results.items():
axes[0].plot(res["estimate"], "--", color=colors[name],
linewidth=1, label=f"{name} (RMSE={res['rmse']:.2f})")
axes[0].set_ylabel("State $x_k$")
axes[0].set_title("Particle Filter: Resampling Method Comparison")
axes[0].legend(loc="upper right", fontsize=9)
axes[0].grid(True, alpha=0.3)
# ESSの推移
for name, res in results.items():
axes[1].plot(res["ess"], color=colors[name], linewidth=0.8, label=name)
axes[1].axhline(y=N_particles / 2, color="red", linestyle=":",
label=f"Threshold (N/2={N_particles // 2})")
axes[1].set_xlabel("Time step $k$")
axes[1].set_ylabel("Effective Sample Size")
axes[1].legend(loc="upper right", fontsize=9)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("particle_filter_comparison.png", dpi=150)
plt.show()
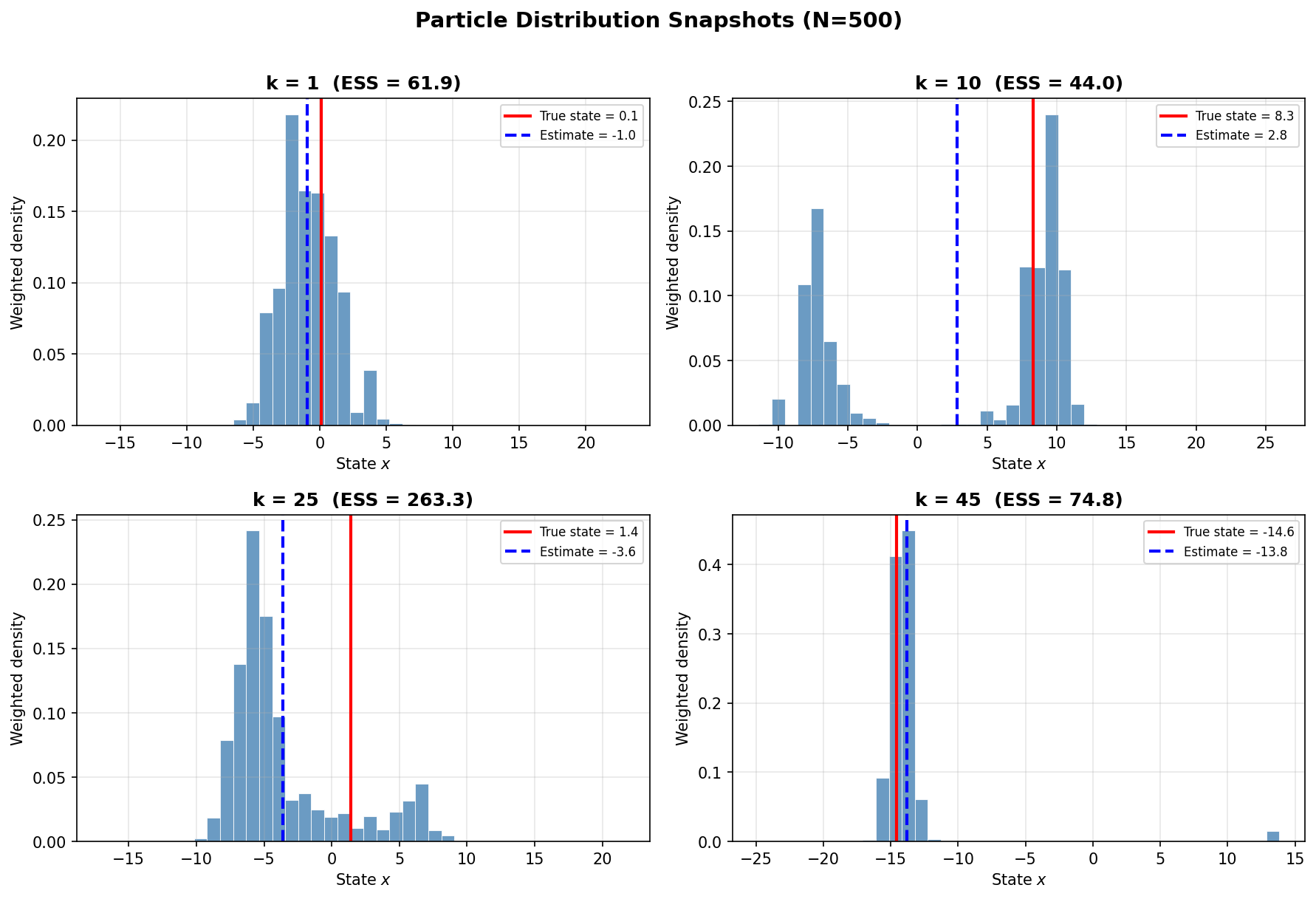
粒子分布のスナップショット
以下の図は、特定の時刻における粒子の分布(重み付きヒストグラム)を示しています。赤線が真の状態、青線が推定値です。
フィルタ手法の比較
粒子フィルタと、ガウス近似に基づくフィルタ手法との比較を以下にまとめます。
| 特性 | 粒子フィルタ | UKF | CKF |
|---|---|---|---|
| 分布の仮定 | なし(任意の分布) | ガウス | ガウス |
| 計算量 | \(O(N)\)(粒子数依存) | \(O(n^3)\) | \(O(n^3)\) |
| パラメータ | 粒子数 \(N\), ESS閾値 | \(\alpha, \beta, \kappa\) | なし |
| 多峰性への対応 | 可能 | 不可 | 不可 |
| 高次元への適用 | 困難(次元の呪い) | 良好 | 良好 |
| 実装の複雑さ | 中程度 | 中程度 | 低い |
粒子フィルタは分布の仮定を必要としない汎用性が強みですが、高次元問題では粒子数が指数的に増加する「次元の呪い」に直面します。低次元で強い非線形性や非ガウス性がある問題では粒子フィルタが有効で、高次元の穏やかな非線形問題ではCKFやUKFが適しています。
関連記事
- カルマンフィルタの理論とPython実装 - 線形ガウスの場合の最適フィルタであるカルマンフィルタを解説しています。
- 拡張カルマンフィルタ(EKF)の理論とPython実装 - 非線形システムへの線形化ベースのアプローチを解説しています。
- Unscented Kalman Filter(UKF)の理論とPython実装 - シグマポイントベースの非線形フィルタを解説しています。
- カルマンスムーザ(RTS Smoother)の理論とPython実装 - 全時刻の観測データを使った平滑化手法を解説しています。
- MCMC入門:メトロポリス・ヘイスティングス法とギブスサンプリング - 粒子フィルタと同じくモンテカルロサンプリングを基盤とする手法です。
参考文献
- Arulampalam, M. S., Maskell, S., Gordon, N., & Clapp, T. (2002). “A Tutorial on Particle Filters for Online Nonlinear/Non-Gaussian Bayesian Tracking.” IEEE Transactions on Signal Processing, 50(2), 174-188.
- Doucet, A., & Johansen, A. M. (2009). “A Tutorial on Particle Filtering and Smoothing: Fifteen Years Later.” Handbook of Nonlinear Filtering, 12(656-704), 3.
- Douc, R., & Cappe, O. (2005). “Comparison of Resampling Schemes for Particle Filtering.” Proceedings of the 4th International Symposium on Image and Signal Processing and Analysis, 64-69.