はじめに:フィルタとスムーザの違い
時系列データから隠れた状態を推定する問題を考えます。カルマンフィルタは逐次的にデータを処理し、各時刻で「現在までの観測」を用いて状態を推定します。一方、スムーザは「すべての観測データ」を用いて各時刻の状態を推定します。
- フィルタリング:時刻 \(t\) までの観測 \(y_{1:t}\) を用いた推定 → \(p(x_t | y_{1:t})\)
- スムージング:全時刻の観測 \(y_{1:T}\) を用いた推定 → \(p(x_t | y_{1:T})\)
スムーザは未来の情報も活用できるため、フィルタよりも常に同等以上の推定精度を達成します。ただし、すべてのデータが揃ってから処理するため、リアルタイム処理には適用できません。バッチ処理や事後解析(軌道の再推定、パラメータ推定の前処理など)で威力を発揮します。
本記事では、最も代表的な固定区間スムーザである Rauch-Tung-Striebel(RTS)スムーザ の理論を導出し、Pythonで実装します。
関連記事:指数移動平均(EMA)フィルタの周波数特性、Cubature Kalman Filter(CKF)の理論とPython実装、信号処理におけるフィルタリング手法の基礎
カルマンフィルタの復習
RTSスムーザの入力はカルマンフィルタのフォワードパスの出力です。ここで線形ガウス状態空間モデルを定義し、カルマンフィルタの式を簡単に振り返ります。
状態空間モデル
\[ x_k = F x_{k-1} + w_{k-1}, \quad w_{k-1} \sim \mathcal{N}(0, Q) \tag{1} \]\[ y_k = H x_k + v_k, \quad v_k \sim \mathcal{N}(0, R) \tag{2} \]ここで \(F\) は状態遷移行列、\(H\) は観測行列、\(Q\) はプロセスノイズの共分散、\(R\) は観測ノイズの共分散です。
予測ステップ
\[ \hat{x}_{k|k-1} = F \hat{x}_{k-1|k-1} \tag{3} \]\[ P_{k|k-1} = F P_{k-1|k-1} F^T + Q \tag{4} \]更新ステップ
\[ K_k = P_{k|k-1} H^T (H P_{k|k-1} H^T + R)^{-1} \tag{5} \]\[ \hat{x}_{k|k} = \hat{x}_{k|k-1} + K_k (y_k - H \hat{x}_{k|k-1}) \tag{6} \]\[ P_{k|k} = (I - K_k H) P_{k|k-1} \tag{7} \]RTSスムーザを実行するためには、フォワードパスで各時刻の \(\hat{x}_{k|k}\)、\(P_{k|k}\)、\(\hat{x}_{k|k-1}\)、\(P_{k|k-1}\) をすべて保存しておく必要があります。
RTSスムーザの導出
RTSスムーザは、カルマンフィルタのフォワードパスの結果を用いて、時刻 \(T\) から \(0\) に向かって逆方向に再帰的に平滑化を行います。
スムーザゲイン
スムーザゲイン \(G_k\) は、フィルタ推定値 \(\hat{x}_{k|k}\) から平滑化推定値 \(\hat{x}_{k|T}\) への修正量を決める行列です:
\[ G_k = P_{k|k} F^T P_{k+1|k}^{-1} \tag{8} \]この行列は、時刻 \(k\) のフィルタ共分散 \(P_{k|k}\) と時刻 \(k+1\) の予測共分散 \(P_{k+1|k}\) の関係から導出されます。
平滑化状態推定
平滑化された状態推定値は、フィルタ推定値に対して「未来の平滑化推定と予測の差」をスムーザゲインで重み付けした修正項を加えることで得られます:
\[ \hat{x}_{k|T} = \hat{x}_{k|k} + G_k (\hat{x}_{k+1|T} - \hat{x}_{k+1|k}) \tag{9} \]直感的には、未来の情報によってフィルタの予測 \(\hat{x}_{k+1|k}\) がどれだけ修正されたかを、時刻 \(k\) に伝搬しています。
平滑化共分散
平滑化された共分散は以下で計算されます:
\[ P_{k|T} = P_{k|k} + G_k (P_{k+1|T} - P_{k+1|k}) G_k^T \tag{10} \]\(P_{k+1|T} - P_{k+1|k} \leq 0\)(平滑化により共分散が予測共分散より小さくなる)であるため、\(P_{k|T} \leq P_{k|k}\) が常に成り立ちます。つまり、スムーザの推定はフィルタの推定よりも不確実性が小さくなります。
バックワードパスのアルゴリズム
初期条件として \(\hat{x}_{T|T}\) と \(P_{T|T}\)(フォワードパスの最終結果)を設定し、\(k = T-1, T-2, \ldots, 0\) について式 \((8)\)〜\((10)\) を逆順に適用します。
Python実装
1次元の位置・速度追跡問題を例として、カルマンフィルタとRTSスムーザを実装します。
状態空間モデルの定義
等速直線運動モデルを使用します。状態ベクトルは \(x = [位置, 速度]^T\) です。
import numpy as np
import matplotlib.pyplot as plt
# ---- 状態空間モデルの定義 ----
dt = 1.0 # サンプリング間隔
# 状態遷移行列(等速直線運動モデル)
F = np.array([[1, dt],
[0, 1]])
# 観測行列(位置のみ観測)
H = np.array([[1, 0]])
# プロセスノイズ共分散
q = 0.1
Q = q * np.array([[dt**3/3, dt**2/2],
[dt**2/2, dt]])
# 観測ノイズ共分散
R = np.array([[1.0]])
n = 2 # 状態次元
m = 1 # 観測次元
カルマンフィルタ(フォワードパス)
def kalman_filter(y_obs, F, H, Q, R, x0, P0):
"""カルマンフィルタのフォワードパス(中間結果をすべて保存)"""
T = len(y_obs)
n = len(x0)
# フィルタ推定値の保存
x_filt = np.zeros((T + 1, n)) # x_{k|k}
P_filt = np.zeros((T + 1, n, n)) # P_{k|k}
# 予測値の保存(スムーザで使用)
x_pred = np.zeros((T, n)) # x_{k|k-1}
P_pred = np.zeros((T, n, n)) # P_{k|k-1}
# 初期化
x_filt[0] = x0
P_filt[0] = P0
for k in range(T):
# 予測ステップ(式3, 4)
x_pred[k] = F @ x_filt[k]
P_pred[k] = F @ P_filt[k] @ F.T + Q
# 更新ステップ(式5, 6, 7)
S = H @ P_pred[k] @ H.T + R
K = P_pred[k] @ H.T @ np.linalg.inv(S)
innovation = y_obs[k] - H @ x_pred[k]
x_filt[k + 1] = x_pred[k] + K @ innovation
P_filt[k + 1] = (np.eye(n) - K @ H) @ P_pred[k]
return x_filt, P_filt, x_pred, P_pred
RTSスムーザ(バックワードパス)
def rts_smoother(x_filt, P_filt, x_pred, P_pred, F):
"""RTSスムーザのバックワードパス"""
T = len(x_pred)
n = x_filt.shape[1]
# 平滑化推定値の保存
x_smooth = np.zeros((T + 1, n))
P_smooth = np.zeros((T + 1, n, n))
# 初期条件:最終時刻のフィルタ推定値
x_smooth[T] = x_filt[T]
P_smooth[T] = P_filt[T]
# バックワード再帰
for k in range(T - 1, -1, -1):
# スムーザゲイン(式8)
G = P_filt[k] @ F.T @ np.linalg.inv(P_pred[k])
# 平滑化状態推定(式9)
x_smooth[k] = x_filt[k] + G @ (x_smooth[k + 1] - x_pred[k])
# 平滑化共分散(式10)
P_smooth[k] = P_filt[k] + G @ (P_smooth[k + 1] - P_pred[k]) @ G.T
return x_smooth, P_smooth
シミュレーション
np.random.seed(42)
T = 50 # タイムステップ数
# 真の初期状態
x_true_init = np.array([0.0, 1.0]) # 位置0, 速度1
# 真の状態の生成
true_states = np.zeros((T + 1, n))
true_states[0] = x_true_init
for k in range(T):
true_states[k + 1] = F @ true_states[k] + \
np.random.multivariate_normal(np.zeros(n), Q)
# 観測の生成
y_obs = np.zeros((T, m))
for k in range(T):
y_obs[k] = H @ true_states[k + 1] + \
np.random.multivariate_normal(np.zeros(m), R)
# フィルタの初期推定
x0 = np.array([0.0, 0.0])
P0 = np.diag([1.0, 1.0])
# カルマンフィルタの実行
x_filt, P_filt, x_pred, P_pred = kalman_filter(y_obs, F, H, Q, R, x0, P0)
# RTSスムーザの実行
x_smooth, P_smooth = rts_smoother(x_filt, P_filt, x_pred, P_pred, F)
フィルタとスムーザの比較
time = np.arange(T + 1)
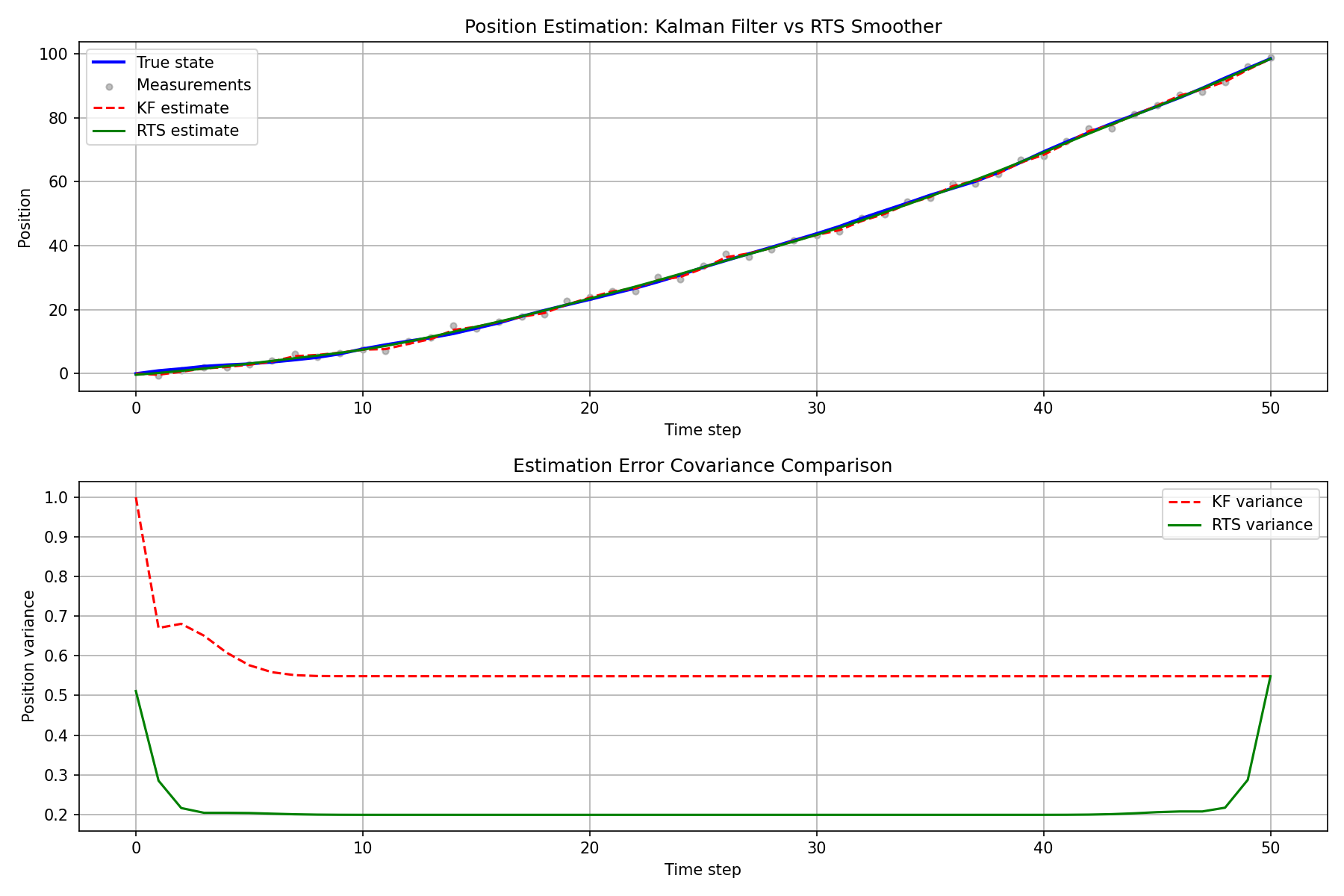
# ---- 位置の推定結果 ----
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
plt.plot(time, true_states[:, 0], "b-", linewidth=2, label="True state")
plt.scatter(np.arange(1, T + 1), y_obs[:, 0],
c="gray", s=15, alpha=0.5, label="Measurements")
plt.plot(time, x_filt[:, 0], "r--", linewidth=1.5, label="KF estimate")
plt.plot(time, x_smooth[:, 0], "g-", linewidth=1.5, label="RTS estimate")
plt.xlabel("Time step")
plt.ylabel("Position")
plt.title("Position Estimation: Kalman Filter vs RTS Smoother")
plt.legend()
plt.grid(True)
# ---- 位置推定の誤差共分散 ----
plt.subplot(2, 1, 2)
kf_pos_var = np.array([P_filt[k, 0, 0] for k in range(T + 1)])
rts_pos_var = np.array([P_smooth[k, 0, 0] for k in range(T + 1)])
plt.plot(time, kf_pos_var, "r--", linewidth=1.5, label="KF variance")
plt.plot(time, rts_pos_var, "g-", linewidth=1.5, label="RTS variance")
plt.xlabel("Time step")
plt.ylabel("Position variance")
plt.title("Estimation Error Covariance Comparison")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig("rts_smoother_result.png", dpi=150)
plt.show()
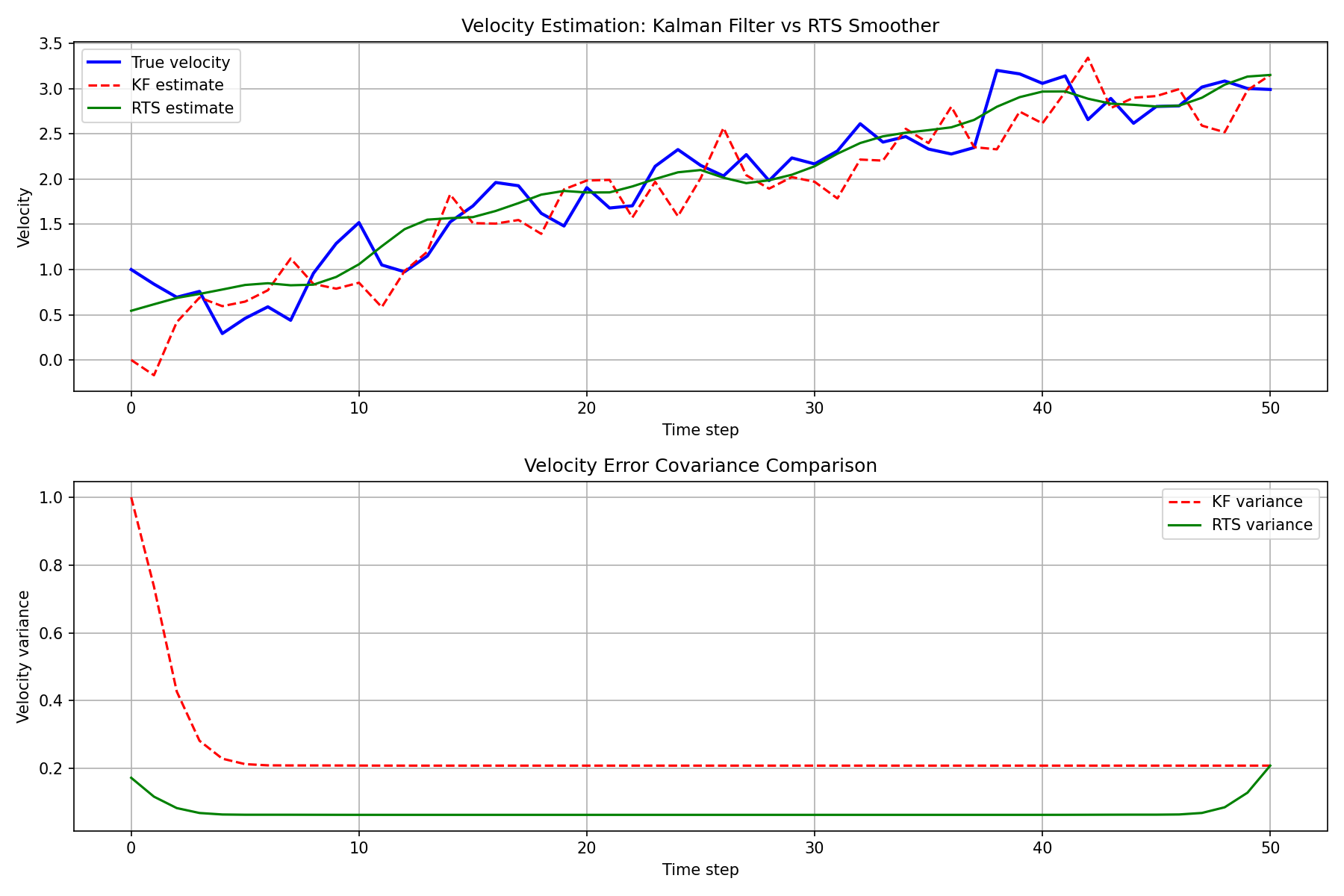
速度(直接観測されない状態)の推定結果を以下に示します。スムーザは観測されない状態成分に対しても大幅な精度改善を実現します。
RMSE比較
# 位置のRMSE
rmse_kf = np.sqrt(np.mean((true_states[1:, 0] - x_filt[1:, 0])**2))
rmse_rts = np.sqrt(np.mean((true_states[1:, 0] - x_smooth[1:, 0])**2))
# 速度のRMSE
rmse_kf_vel = np.sqrt(np.mean((true_states[1:, 1] - x_filt[1:, 1])**2))
rmse_rts_vel = np.sqrt(np.mean((true_states[1:, 1] - x_smooth[1:, 1])**2))
print(f"Position RMSE - KF: {rmse_kf:.4f}, RTS: {rmse_rts:.4f}")
print(f"Velocity RMSE - KF: {rmse_kf_vel:.4f}, RTS: {rmse_rts_vel:.4f}")
print(f"Position improvement: {(1 - rmse_rts / rmse_kf) * 100:.1f}%")
print(f"Velocity improvement: {(1 - rmse_rts_vel / rmse_kf_vel) * 100:.1f}%")
| 指標 | カルマンフィルタ | RTS スムーザ | 改善率 |
|---|---|---|---|
| 位置 RMSE | 0.6540 | 0.3638 | 44.4% |
| 速度 RMSE | 0.3884 | 0.2358 | 39.3% |
RTSスムーザの推定は、カルマンフィルタの推定よりも真の状態に近く、特にデータの端部以外では大幅な精度改善が確認できます。誤差共分散のプロットからも、スムーザの不確実性が常にフィルタ以下であることが分かります。
まとめ
RTSスムーザは、カルマンフィルタのフォワードパスに対してバックワードパスを追加するだけで実現でき、実装コストが低い割に推定精度を大きく向上させます。リアルタイム性が不要なバッチ処理のシナリオでは、まずRTSスムーザの適用を検討すべきです。
なお、本記事では線形モデルに限定しましたが、非線形モデルに対しては Extended Kalman Smoother や Unscented Kalman Smoother、CKFベースのスムーザなどの拡張も存在します。
関連記事
- カルマンフィルタの理論とPython実装 - RTSスムーザの基盤となるカルマンフィルタの理論と実装を解説しています。
- 拡張カルマンフィルタ(EKF)の理論とPython実装 - 非線形モデルに対応するEKFを解説しています。非線形スムーザの基盤にもなります。
- Unscented Kalman Filter(UKF)の理論とPython実装 - UKFベースのスムーザへの拡張の基盤となるUKFを解説しています。
- 粒子フィルタのPython実装:リサンプリング手法の比較 - 粒子スムーザの基盤となる粒子フィルタを解説しています。
- 時系列データの異常検知:統計的手法からカルマンフィルタまで - RTSスムーザはオフライン異常検知の前処理としても有用です。
参考文献
- Rauch, H. E., Tung, F., & Striebel, C. T. (1965). “Maximum likelihood estimates of linear dynamic systems.” AIAA Journal, 3(8), 1445-1450.
- Särkkä, S. (2013). Bayesian Filtering and Smoothing. Cambridge University Press.