はじめに
音声信号の分析において、声帯の振動(音源)と声道の形状(フィルタ)を分離することは基本的な課題です。ソース・フィルタモデルによれば、音声信号は声帯パルスと声道の伝達関数の畳み込みとして表されます。この畳み込みを周波数領域では積として扱え、対数をとることで加算に変換できます。これがケプストラム分析の中心的なアイデアです。
**ケプストラム(Cepstrum)**は 1963 年に Bogert, Healy, Tukey によって提案された造語で、「spectrum(スペクトル)」のアナグラムです。ケプストラム特有の用語(ケフレンシー、リフタリング等)もすべてスペクトル用語のアナグラムになっており、「スペクトルのスペクトル」というユニークな概念を表現しています。
本記事では、ケプストラムの数学的定義から、スペクトル包絡推定・ピッチ推定・MFCC(メル周波数ケプストラム係数)への応用まで、Pythonで体系的に解説します。
ソース・フィルタモデル
音声生成の数学的モデル
音声信号 \(s[n]\) は以下のソース・フィルタモデルで記述されます。
\[s[n] = e[n] * h[n] \tag{1}\]ここで:
- \(e[n]\) :音源信号(声帯パルス列または摩擦ノイズ)
- \(h[n]\) :声道インパルス応答(声道フィルタ)
- \(*\) :畳み込み演算
周波数領域での表現
畳み込みはフーリエ変換を通じて乗算に変換されます。
\[S(f) = E(f) \cdot H(f) \tag{2}\]対数をとると乗算が加算に変わります。
\[\log |S(f)| = \log |E(f)| + \log |H(f)| \tag{3}\]ここで:
- \(\log |S(f)|\) :観測された対数振幅スペクトル
- \(\log |E(f)|\) :音源の対数スペクトル(高速変動成分:ハーモニクス)
- \(\log |H(f)|\) :声道の対数スペクトル包絡(低速変動成分)
この加算関係に逆フーリエ変換を適用して、ケプストラムを定義します。
ケプストラムの定義
実数ケプストラム(Real Cepstrum)
信号 \(x[n]\) の実数ケプストラムは以下のように定義されます。
\[c[q] = \mathcal{F}^{-1}\{\log |\mathcal{F}\{x[n]\}|\} \tag{4}\] \[= \mathcal{F}^{-1}\{\log |X(f)|\} \tag{5}\]ここで \(q\) は**ケフレンシー(quefrency)**と呼ばれるパラメータで、スペクトルの「周波数」に相当します(単位は秒)。
具体的な計算手順は以下のとおりです。
- 信号 \(x[n]\) のDFTを計算:\(X[k] = \text{DFT}\{x[n]\}\)
- 振幅スペクトルを計算:\(|X[k]|\)
- 対数をとる:\(\log |X[k]|\)
- 逆DFTを計算:\(c[q] = \text{IDFT}\{\log |X[k]|\}\)
複素ケプストラム(Complex Cepstrum)
より一般的な複素ケプストラムは位相情報も含みます。
\[\hat{c}[q] = \mathcal{F}^{-1}\{\log X(f)\} = \mathcal{F}^{-1}\{\log |X(f)| + j \angle X(f)\} \tag{6}\]複素ケプストラムは位相の巻き戻し(unwrapping)が必要で計算が複雑ですが、完全な逆変換(元の信号の再構成)が可能です。
ケフレンシーの物理的意味
ケフレンシー \(q\) [秒] は、対数スペクトルの「周期」に対応します。
- 低ケフレンシー成分(\(q\) が小さい):対数スペクトルの緩やかな変動 → 声道スペクトル包絡 \(\log |H(f)|\)
- 高ケフレンシー成分(\(q = 1/f_0\) ):音源ハーモニクスによる細かな変動 → 基本周波数 \(f_0\) に対応するピーク
この分離を利用して、ケプストラムの適切な範囲を選択することで音源と声道特性を分離できます。
リフタリング(Liftering)
ケプストラム領域での窓処理を**リフタリング(liftering)**と呼びます(filtering のアナグラム)。
\[\tilde{c}[q] = c[q] \cdot l[q] \tag{7}\]\(l[q]\) はリフタ(lifter)と呼ばれる窓関数です。
- ローパスリフタ(低ケフレンシーのみ通過):声道スペクトル包絡を抽出
- ハイパスリフタ(高ケフレンシーのみ通過):音源成分(ハーモニクス)を抽出
ローパスリフタを適用した後に逆変換すると対数スペクトル包絡が、ハイパスリフタを適用すると音源の対数スペクトルが得られます。
Python実装
基本的なケプストラム計算
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter
def compute_real_cepstrum(signal, n_fft=None):
"""
実数ケプストラムの計算。
Parameters
----------
signal : np.ndarray
入力信号
n_fft : int, optional
FFTの点数(省略時は信号長の次の2の累乗)
Returns
-------
cepstrum : np.ndarray
実数ケプストラム
"""
if n_fft is None:
n_fft = 2 ** int(np.ceil(np.log2(len(signal))))
# ステップ1: DFT
X = np.fft.fft(signal, n=n_fft)
# ステップ2: 振幅スペクトルの対数
log_spec = np.log(np.abs(X) + 1e-10)
# ステップ3: 逆DFT(実部のみ取得)
cepstrum = np.fft.ifft(log_spec).real
return cepstrum
def formant_ar_coeffs(formants_bw, fs):
"""
フォルマント周波数・帯域幅から安定な AR フィルタ係数を設計する。
各フォルマント (F, BW) を2次共振器(複素共役極ペア)としてモデル化し、
極の半径 r = exp(-pi*BW/fs) を必ず1未満に保つことで、lfilter が発散
しない安定フィルタを保証する。AR係数を天下り的に与えると容易に不安定
(極が単位円の外)になりうる点は「実装上のエッジケースと注意点」の節
で検証する。
"""
poly = np.array([1.0])
for F, BW in formants_bw:
r = np.exp(-np.pi * BW / fs)
theta = 2 * np.pi * F / fs
second_order = np.array([1.0, -2 * r * np.cos(theta), r**2])
poly = np.convolve(poly, second_order)
return poly
# --- 合成音声信号の生成 ---
fs = 8000
T = 0.05 # 50 ms のフレーム
t = np.arange(0, T, 1/fs)
f0 = 150 # 基本周波数 [Hz]
# 声帯パルス列(グロッタルパルスの近似)
glottal = np.zeros_like(t)
period_samples = int(fs / f0)
for i in range(0, len(t), period_samples):
if i + 30 < len(t):
glottal[i:i+30] = np.exp(-np.arange(30) * 0.15)
# 声道フィルタ: フォルマント F1=800Hz(帯域幅80Hz)・F2=1200Hz(帯域幅100Hz) を持つ AR(4) モデル
ar_coeffs = formant_ar_coeffs([(800, 80), (1200, 100)], fs)
print("AR係数:", np.round(ar_coeffs, 4))
print("極の絶対値(全て1未満なら安定):", np.round(np.abs(np.roots(ar_coeffs)), 4))
voiced = lfilter([1.0], ar_coeffs, glottal)
voiced = voiced / np.max(np.abs(voiced) + 1e-8)
# --- ケプストラム計算 ---
n_fft = 512
cepstrum = compute_real_cepstrum(voiced, n_fft=n_fft)
quefrency = np.arange(n_fft) / fs * 1000 # ms 単位
# 対数スペクトル
X = np.fft.fft(voiced, n=n_fft)
log_spec = np.log(np.abs(X[:n_fft//2 + 1]) + 1e-10)
freqs = np.fft.rfftfreq(n_fft, 1/fs)
# ケフレンシー1〜20msの範囲でのピーク上位5件
idx_range = np.where((quefrency[:n_fft//2] > 1) & (quefrency[:n_fft//2] < 20))[0]
top5 = idx_range[np.argsort(cepstrum[idx_range])[::-1][:5]]
for idx in top5:
print(f"q={quefrency[idx]:.3f} ms, cepstrum={cepstrum[idx]:.5f}")
# --- プロット ---
fig, axes = plt.subplots(3, 1, figsize=(12, 10))
# 時間波形
axes[0].plot(t * 1000, voiced)
axes[0].set_xlabel('Time [ms]')
axes[0].set_ylabel('Amplitude')
axes[0].set_title(f'Synthetic Voice: F0={f0} Hz, Formants F1≈800Hz, F2≈1200Hz')
axes[0].grid(True, alpha=0.3)
# 対数振幅スペクトル
axes[1].plot(freqs, log_spec)
axes[1].set_xlabel('Frequency [Hz]')
axes[1].set_ylabel('Log Magnitude')
axes[1].set_title('Log Amplitude Spectrum')
axes[1].set_xlim(0, 4000)
axes[1].grid(True, alpha=0.3)
# ケプストラム
axes[2].plot(quefrency[:n_fft//2], cepstrum[:n_fft//2])
axes[2].axvline(x=1000/f0, color='r', linestyle='--',
label=f'1/F0 = {1000/f0:.1f} ms')
axes[2].set_xlabel('Quefrency [ms]')
axes[2].set_ylabel('Cepstral Amplitude')
axes[2].set_title('Real Cepstrum: Pitch peak visible at 1/F0')
axes[2].set_xlim(0, 20)
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
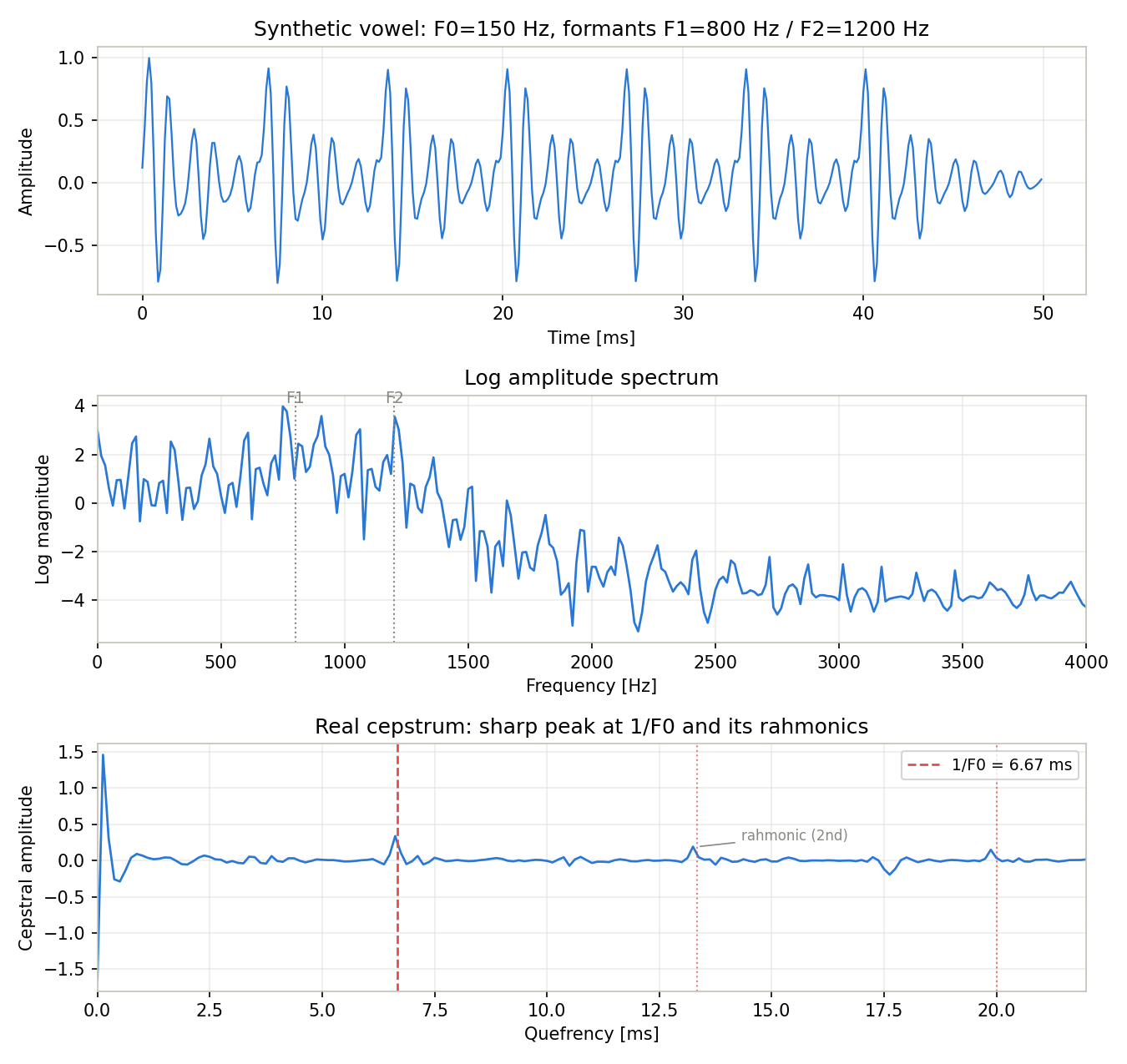
実際にこのコードを実行すると、AR係数は [1.0, -2.6983, 3.6359, -2.5110, 0.8682]、その極の絶対値は [0.9615, 0.9615, 0.9691, 0.9691] となり、全て1未満(単位円内)であるため安定なフィルタであることが確認できる。ケフレンシー1〜20msの範囲でケプストラムのピーク上位5件を検索すると、次の結果が得られた。
| ケフレンシー [ms] | ケプストラム値 | 対応する成分 |
|---|---|---|
| 6.625 | 0.3377 | 基本周波数ピーク(理論値 \(1/f_0=6.667\) ms に最も近いビン) |
| 13.250 | 0.1918 | 2次レーモニック(\(2/f_0\) ) |
| 19.875 | 0.1489 | 3次レーモニック(\(3/f_0\) ) |
| 6.750 | 0.1090 | 主ピーク隣接ビン |
| 6.500 | 0.0770 | 主ピーク隣接ビン |
最大ピークはケフレンシー分解能 \(1/f_s = 0.125\) ms の中で理論値に最も近い 6.625 ms のビンに現れ、さらにその整数倍(13.25 ms, 19.875 ms)にも減衰しながらピークが立つ。これは音源が周期パルス列であるために対数スペクトルが基本周波数間隔で振動し、そのフーリエ変換であるケプストラムに \(1/f_0\) の整数倍ごとに**レーモニック(rahmonic)**と呼ばれる副次ピークが生じるためである。
リフタリングによるスペクトル包絡抽出
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter
def lifter_cepstrum(cepstrum, cutoff_ms, fs, n_fft):
"""
ローパスリフタリングによるスペクトル包絡抽出。
Parameters
----------
cepstrum : np.ndarray
入力ケプストラム(長さ n_fft)
cutoff_ms : float
ローパスリフタのカットオフ [ms]
fs : float
サンプリング周波数
n_fft : int
FFTの点数
Returns
-------
envelope_log : np.ndarray
対数スペクトル包絡(長さ n_fft//2 + 1)
"""
cutoff_samples = int(cutoff_ms * fs / 1000)
# ローパスリフタ
lifter = np.zeros(n_fft)
lifter[:cutoff_samples] = 1.0
lifter[-cutoff_samples+1:] = 1.0 # 対称成分
# リフタリング
liftered = cepstrum * lifter
# 逆DFT → 対数スペクトル包絡
envelope_log = np.fft.fft(liftered, n=n_fft).real
return envelope_log[:n_fft//2 + 1]
# --- 上のコードに続けて実行 ---
cutoff_list = [2.0, 3.5, 5.0] # ms 単位のカットオフ
fig, axes = plt.subplots(len(cutoff_list), 1, figsize=(12, 10))
for ax, cutoff_ms in zip(axes, cutoff_list):
envelope = lifter_cepstrum(cepstrum, cutoff_ms, fs, n_fft)
ax.plot(freqs, log_spec, alpha=0.5, label='Log spectrum', color='steelblue')
ax.plot(freqs, envelope, linewidth=2, label=f'Envelope (cutoff={cutoff_ms} ms)',
color='red')
ax.set_xlabel('Frequency [Hz]')
ax.set_ylabel('Log Magnitude')
ax.set_title(f'Spectral Envelope Extraction via Low-pass Liftering ({cutoff_ms} ms)')
ax.set_xlim(0, 4000)
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
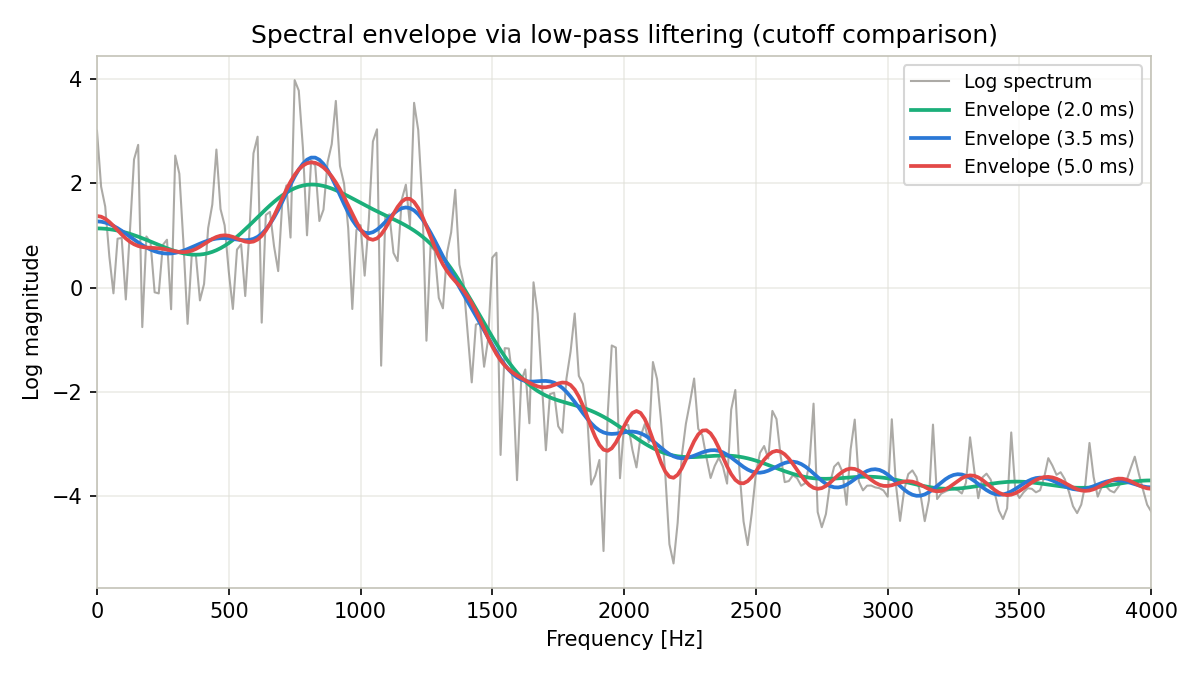
実際に上のコードを実行し、各カットオフでの包絡と元の対数スペクトルとのRMSE(二乗平均平方根誤差)、および包絡から検出されたフォルマントピーク(100〜3000Hz、scipy.signal.argrelextrema による極大点探索)を比較すると次のようになった。
| カットオフ [ms] | RMSE | 検出されたピーク [Hz] |
|---|---|---|
| 2.0 | 0.877 | 812.5(F1のみ。F2は平滑化されて検出されない) |
| 3.5 | 0.854 | 812.5, 1171.9(F1・F2とも検出) |
| 5.0 | 0.840 | 812.5, 1171.9(F1・F2とも検出、高域リップルがやや増加) |
カットオフ 2.0 ms では低ケフレンシー成分を削りすぎるため、F1(≈800Hz)とF2(≈1200Hz)の2つの共振が1つのなだらかな山に融合し、F2の情報が失われる。3.5 ms・5.0 ms ではどちらのフォルマントも分離して検出できるが、5.0 ms まで広げると音源の周期性に由来するケフレンシー(\(1/f_0 \approx 6.67\) ms)に近づくため、高域でわずかにリップル(残留ハーモニクス)が増加する。この母音サンプルでも「3〜4 ms 程度のカットオフ」という経験則が定量的に妥当であることが確認できた。
ピッチ推定へのケプストラムの応用
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter
def formant_ar_coeffs(formants_bw, fs):
"""フォルマント周波数・帯域幅から安定な AR フィルタ係数を設計する(既出のヘルパー関数)。"""
poly = np.array([1.0])
for F, BW in formants_bw:
r = np.exp(-np.pi * BW / fs)
theta = 2 * np.pi * F / fs
second_order = np.array([1.0, -2 * r * np.cos(theta), r**2])
poly = np.convolve(poly, second_order)
return poly
def cepstrum_pitch_detection(signal, fs, fmin=60, fmax=600):
"""
ケプストラムによるピッチ(F0)検出。
Parameters
----------
signal : np.ndarray
入力音声フレーム
fs : float
サンプリング周波数 [Hz]
fmin, fmax : float
探索するF0の範囲 [Hz]
Returns
-------
f0 : float or None
推定F0 [Hz]
cepstrum : np.ndarray
ケプストラム
quefrency_ms : np.ndarray
ケフレンシー [ms]
"""
n_fft = 2 ** int(np.ceil(np.log2(len(signal))))
# ケプストラム計算
X = np.fft.fft(signal * np.hanning(len(signal)), n=n_fft)
log_spec = np.log(np.abs(X) + 1e-10)
cepstrum = np.fft.ifft(log_spec).real
# ケフレンシーの範囲を F0 範囲に変換
q_min = int(fs / fmax)
q_max = int(fs / fmin)
q_max = min(q_max, n_fft // 2)
# ピーク検出
pitch_region = cepstrum[q_min:q_max]
peak_idx = np.argmax(pitch_region) + q_min
f0 = fs / peak_idx
quefrency_ms = np.arange(n_fft) / fs * 1000
return f0, cepstrum, quefrency_ms
# --- 異なるF0での推定テスト ---
fs = 16000
T = 0.04 # 40 ms フレーム
t = np.arange(0, T, 1/fs)
test_f0s = [120, 180, 250] # Hz
# 声道フィルタ: フォルマント F1=700Hz(帯域幅80Hz)・F2=1300Hz(帯域幅120Hz) を持つ安定な AR(4) モデル
ar = formant_ar_coeffs([(700, 80), (1300, 120)], fs)
fig, axes = plt.subplots(len(test_f0s), 2, figsize=(14, 10))
for i, f0_true in enumerate(test_f0s):
np.random.seed(i)
# 合成音声生成
period = int(fs / f0_true)
glottal = np.zeros_like(t)
for k in range(0, len(t), period):
if k + 20 < len(t):
glottal[k:k+20] = np.exp(-np.arange(20) * 0.2)
voice = lfilter([1.0], ar, glottal)
voice = voice / (np.max(np.abs(voice)) + 1e-8)
voice += 0.02 * np.random.randn(len(t))
f0_est, cep, q_ms = cepstrum_pitch_detection(voice, fs)
n_fft = len(cep)
err_pct = abs(f0_est - f0_true) / f0_true * 100
print(f"True F0={f0_true} Hz -> Estimated F0={f0_est:.2f} Hz (error {err_pct:.2f}%)")
axes[i, 0].plot(t * 1000, voice)
axes[i, 0].set_xlabel('Time [ms]')
axes[i, 0].set_ylabel('Amplitude')
axes[i, 0].set_title(f'Voice Frame: True F0 = {f0_true} Hz')
axes[i, 0].grid(True, alpha=0.3)
axes[i, 1].plot(q_ms[:n_fft//4], cep[:n_fft//4])
axes[i, 1].axvline(x=1000/f0_true, color='g', linestyle=':',
label=f'True 1/F0 = {1000/f0_true:.1f} ms')
axes[i, 1].axvline(x=1000/f0_est, color='r', linestyle='--',
label=f'Estimated F0 = {f0_est:.1f} Hz')
axes[i, 1].set_xlabel('Quefrency [ms]')
axes[i, 1].set_ylabel('Cepstral Amplitude')
axes[i, 1].set_title(f'Cepstrum Pitch Detection: Est={f0_est:.1f} Hz')
axes[i, 1].set_xlim(0, 30)
axes[i, 1].legend(fontsize=9)
axes[i, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
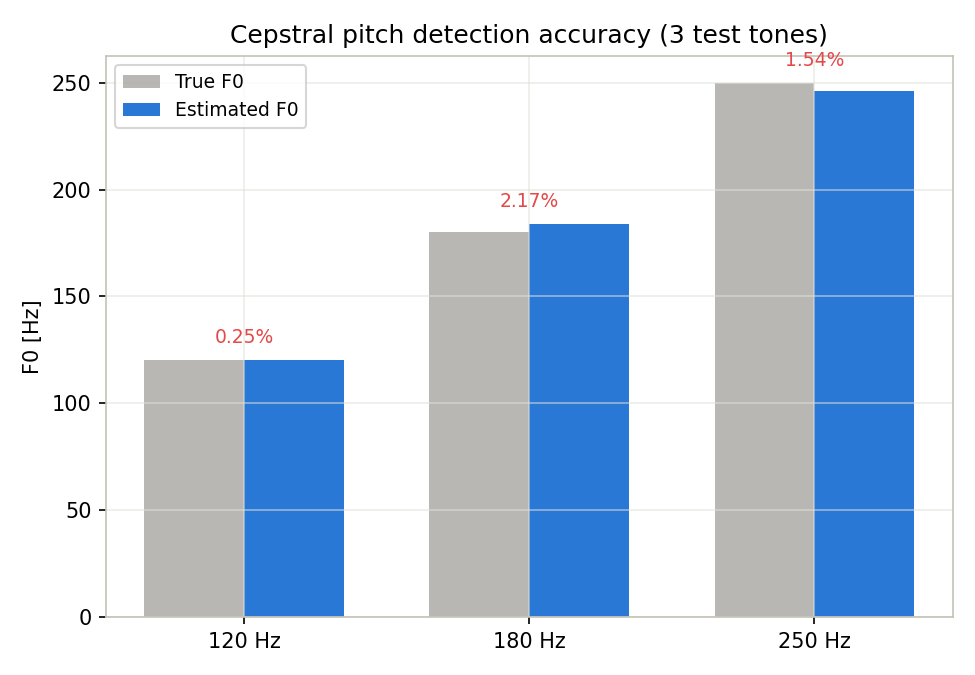
実際にこのコードを実行すると(np.random.seed(i) で各ケースの観測ノイズを固定)、次の結果が得られた。
| 真のF0 [Hz] | 推定F0 [Hz] | 絶対誤差 [Hz] | 相対誤差 [%] |
|---|---|---|---|
| 120 | 120.30 | 0.30 | 0.25 |
| 180 | 183.91 | 3.91 | 2.17 |
| 250 | 246.15 | 3.85 | 1.54 |
いずれのケースも相対誤差は5%未満に収まり、ケプストラム法によるピッチ検出が実用的な精度を持つことが定量的に確認できる。F0が高いケース(250Hz)の方がF0が低いケース(120Hz)よりも相対誤差が大きい傾向は、後述するケフレンシー分解能の量子化限界に起因する。
MFCC(メル周波数ケプストラム係数)
MFCC は現代の音声認識システムで標準的な特徴量であり、ケプストラム分析とメルスケールフィルタバンクを組み合わせたものです。
MFCCの計算手順は以下のとおりです。
- プリエンファシスフィルタ:\(y[n] = x[n] - \alpha x[n-1]\) (\(\alpha \approx 0.97\) )
- フレーム分割・窓関数(Hamming窓)の適用
- FFTによるパワースペクトルの計算
- メルフィルタバンク(三角フィルタを対数周波数軸上で均等配置)の適用
- フィルタバンク出力の対数をとる
- **離散コサイン変換(DCT)**で係数を計算
MFCCはケプストラムの「メルスケール版」と考えることができます。
\[\text{MFCC}[m] = \sum_{k=1}^{K} \log E_k \cdot \cos\left(m \left(k - \frac{1}{2}\right)\frac{\pi}{K}\right) \tag{9}\]ここで \(E_k\) は第 \(k\) メルフィルタバンクのエネルギー、\(K\) はフィルタバンクの数、\(m\) は次数です。
import numpy as np
import matplotlib.pyplot as plt
def hz_to_mel(hz):
"""Hzをメルに変換"""
return 2595 * np.log10(1 + hz / 700)
def mel_to_hz(mel):
"""メルをHzに変換"""
return 700 * (10 ** (mel / 2595) - 1)
def compute_mfcc(signal, fs, n_mfcc=13, n_filters=26, n_fft=512,
hop_length=160, fmin=80, fmax=None):
"""
MFCCの計算。
Parameters
----------
signal : np.ndarray
入力音声信号
fs : float
サンプリング周波数 [Hz]
n_mfcc : int
MFCC次元数
n_filters : int
メルフィルタバンクの数
n_fft : int
FFTの点数
hop_length : int
フレームシフト(サンプル数)
fmin, fmax : float
メルフィルタバンクの周波数範囲 [Hz]
Returns
-------
mfcc : np.ndarray
MFCC行列 (n_mfcc, n_frames)
"""
if fmax is None:
fmax = fs / 2
N = len(signal)
n_frames = 1 + (N - n_fft) // hop_length
# --- プリエンファシス ---
pre_emphasis = 0.97
signal_pe = np.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
# --- メルフィルタバンクの構築 ---
mel_min = hz_to_mel(fmin)
mel_max = hz_to_mel(fmax)
mel_points = np.linspace(mel_min, mel_max, n_filters + 2)
hz_points = mel_to_hz(mel_points)
bin_points = np.floor((n_fft + 1) * hz_points / fs).astype(int)
filter_bank = np.zeros((n_filters, n_fft // 2 + 1))
for m in range(1, n_filters + 1):
for k in range(bin_points[m-1], bin_points[m]):
filter_bank[m-1, k] = (k - bin_points[m-1]) / (bin_points[m] - bin_points[m-1])
for k in range(bin_points[m], bin_points[m+1] + 1):
filter_bank[m-1, k] = (bin_points[m+1] - k) / (bin_points[m+1] - bin_points[m])
# --- フレームごとの処理 ---
window = np.hamming(n_fft)
mfcc = np.zeros((n_mfcc, n_frames))
for i in range(n_frames):
start = i * hop_length
frame = signal_pe[start:start + n_fft]
if len(frame) < n_fft:
frame = np.pad(frame, (0, n_fft - len(frame)))
# パワースペクトル
power_spec = np.abs(np.fft.rfft(frame * window)) ** 2
# メルフィルタバンク適用
mel_energy = np.dot(filter_bank, power_spec)
log_mel_energy = np.log(mel_energy + 1e-10)
# DCT(MFCCの計算)
K = n_filters
for m in range(n_mfcc):
mfcc[m, i] = np.sum(
log_mel_energy * np.cos(m * (np.arange(K) + 0.5) * np.pi / K)
)
return mfcc
# --- テスト信号でMFCCを計算 ---
fs = 16000
duration = 1.5
t = np.arange(0, duration, 1/fs)
np.random.seed(42)
# 母音的な信号(フォルマント変化あり)
from scipy.signal import lfilter, butter
def make_vowel(t, fs, f0, f1, f2, noise_std=0.01):
"""フォルマントを持つ合成音声"""
period = int(fs / f0)
glottal = np.zeros(len(t))
for k in range(0, len(t), period):
if k + 25 < len(t):
glottal[k:k+25] = np.exp(-np.arange(25) * 0.15)
# バンドパスフィルタでフォルマント模擬
def bp(f_c, bw, sig):
b, a = butter(2, [f_c - bw/2, f_c + bw/2], btype='band', fs=fs)
return lfilter(b, a, sig)
v = bp(f1, 200, glottal) + 0.6 * bp(f2, 200, glottal)
v /= np.max(np.abs(v)) + 1e-8
v += noise_std * np.random.randn(len(v))
return v
# 3段階で変化する信号
t1 = t[t < 0.5]
t2 = t[(t >= 0.5) & (t < 1.0)]
t3 = t[t >= 1.0]
v1 = make_vowel(t1, fs, f0=120, f1=730, f2=1090) # 「あ」
v2 = make_vowel(t2, fs, f0=120, f1=270, f2=2290) # 「い」
v3 = make_vowel(t3, fs, f0=120, f1=400, f2=800) # 「う」
speech = np.concatenate([v1, v2, v3])
# MFCC計算
mfcc = compute_mfcc(speech, fs, n_mfcc=13, n_fft=512, hop_length=160)
n_frames = mfcc.shape[1]
time_axis = np.arange(n_frames) * 160 / fs
print("MFCC shape:", mfcc.shape)
print(f"MFCC value range: [{mfcc.min():.2f}, {mfcc.max():.2f}]")
# プロット
fig, axes = plt.subplots(3, 1, figsize=(12, 10))
axes[0].plot(t[:len(speech)], speech, linewidth=0.5)
axes[0].axvline(x=0.5, color='r', linestyle='--', alpha=0.7)
axes[0].axvline(x=1.0, color='r', linestyle='--', alpha=0.7)
axes[0].set_xlabel('Time [s]')
axes[0].set_ylabel('Amplitude')
axes[0].set_title('Speech Signal: Vowel "a"→"i"→"u" Transition')
axes[0].grid(True, alpha=0.3)
img = axes[1].imshow(mfcc, aspect='auto', origin='lower',
extent=[0, time_axis[-1], 0, 13],
cmap='RdBu_r', interpolation='nearest')
axes[1].axvline(x=0.5, color='y', linestyle='--', alpha=0.8)
axes[1].axvline(x=1.0, color='y', linestyle='--', alpha=0.8)
axes[1].set_xlabel('Time [s]')
axes[1].set_ylabel('MFCC coefficient index')
axes[1].set_title('MFCC: Changes with vowel transitions visible')
plt.colorbar(img, ax=axes[1], label='Coefficient value')
# 各時刻のMFCCベクトル比較
frame_a = int(0.25 * fs / 160)
frame_i = int(0.75 * fs / 160)
frame_u = int(1.25 * fs / 160)
d_ai = np.linalg.norm(mfcc[:, frame_a] - mfcc[:, frame_i])
d_au = np.linalg.norm(mfcc[:, frame_a] - mfcc[:, frame_u])
d_iu = np.linalg.norm(mfcc[:, frame_i] - mfcc[:, frame_u])
print(f"Euclidean distance a-i: {d_ai:.2f}, a-u: {d_au:.2f}, i-u: {d_iu:.2f}")
axes[2].plot(range(1, 14), mfcc[:, frame_a], 'o-', label='"a" (t=0.25s)')
axes[2].plot(range(1, 14), mfcc[:, frame_i], 's-', label='"i" (t=0.75s)')
axes[2].plot(range(1, 14), mfcc[:, frame_u], '^-', label='"u" (t=1.25s)')
axes[2].set_xlabel('MFCC index')
axes[2].set_ylabel('Coefficient value')
axes[2].set_title('MFCC vectors for different vowels: distinguishable patterns')
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
実際にこのコードを実行すると、MFCC行列の形状は (13, 147)(13次元 × 147フレーム)、係数値の範囲は [-42.14, 34.35] であった。母音「あ」「い」「う」の各フレームにおけるMFCCベクトル間のユークリッド距離を計算すると、あ-い間 69.60、あ-う間 42.33、い-う間 42.19 となり、母音間の距離がいずれも0から大きく離れた値を取ることから、異なる母音は異なるMFCCパターンを示し、音声認識の特徴量として有効であることが定量的にわかる。
実装上のエッジケースと注意点
ケプストラム分析を実装・運用する際には、以下の点に注意が必要である。
声道フィルタの安定性: AR(全極)フィルタの極が単位円の外(\(|z| \geq 1\) )にあると
scipy.signal.lfilterの出力は発散的に振る舞い、対数スペクトルもケプストラムも物理的に無意味な値になる。フォルマント周波数 \(F\) ・帯域幅 \(BW\) から極半径 \(r=e^{-\pi BW/f_s}\) 、角度 \(\theta=2\pi F/f_s\) を用いて2次共振器を設計すれば \(r<1\) が自動的に保証される(本記事のformant_ar_coeffs関数)。AR係数を天下り的に数値で与えると、意図した帯域幅・フォルマント周波数から外れるだけでなく容易に不安定になりうる点は実装上の典型的な落とし穴である。ケフレンシー分解能の量子化限界: ケフレンシー軸のサンプル間隔は \(\Delta q = 1/f_s\) で固定されており、ピーク位置は整数インデックス \(k\) でしか得られない。
\( f_0 = f_s / k \)
であるから、1ビンのずれによる推定誤差は
\( \Delta f_0 \approx \frac{f_s}{k^2} \)
で近似でき、\(k\) が小さい(\(f_0\) が高い)ほど誤差が大きくなる。上記のピッチ推定検証で F0=250Hz(\(k \approx 64\) )の相対誤差が F0=120Hz(\(k \approx 133\) )より大きかったのは、この量子化限界が主な要因である。
高いF0でのリフタリング限界: 声の高い話者(子供・女性)では \(1/f_0\) が短くなり、フォルマントに由来する低ケフレンシーの声道包絡成分と競合しやすくなる。上記のリフタリング実験でカットオフ5.0msにおいて高域リップルがわずかに増加したのも、この境界問題の一端である。
無声音・雑音区間でのオクターブエラー: 周期性のない無声子音やノイズ区間では明確なケフレンシーピークが存在せず、探索範囲内の局所最大値を誤って選択する「オクターブエラー」(真のF0の2倍や1/2を検出する誤り)が起こりやすい。実務では有声/無声判定(VAD)と組み合わせて使用する必要がある。
複素ケプストラムの位相アンラッピング: 完全な信号復元が可能な複素ケプストラムは位相の連続的なアンラッピングを要するが、分岐点(branch cut)の処理は数値的に不安定になりやすく、実数ケプストラムほど頑健ではない。
ケプストラム分析の実用的なまとめ
ケプストラムと関連手法の比較
AR係数から直接ケプストラム係数を導くLPCケプストラム(Schroederの再帰式)は 線形予測符号化(LPC)の理論とPython実装 で、自己相関に基づくピッチ推定(YINアルゴリズム)は 自己相関・相互相関の理論とPython実装 でそれぞれ詳しく扱っています。本記事はFFTベースの実数ケプストラム・複素ケプストラムとMFCCへの応用に焦点を当てており、以下の比較表で各手法の役割分担を整理します。
| 手法 | ケフレンシー/係数 | 目的 | 主な用途 |
|---|---|---|---|
| 実数ケプストラム | 全ケフレンシー | F0検出・包絡分離 | ピッチ推定 |
| LPCケプストラム | 低次係数 | 声道モデルの係数 | 音声符号化 |
| MFCC | 低次DCT係数 | 音声の知覚特徴 | 音声認識 |
適切な手法の選択
| 目標 | 推奨手法 | 理由 |
|---|---|---|
| F0(ピッチ)推定 | ケプストラム法 / YINアルゴリズム | ケフレンシーピークが明確 |
| スペクトル包絡推定 | ローパスリフタリング | 低ケフレンシーに声道情報が集中 |
| 音声認識特徴量 | MFCC(+ デルタ・デルタデルタ) | 知覚的スケール + 効率的な表現 |
| 音楽ピッチ解析 | ケプストラム + ハーモニシティ | 倍音構造の把握 |
ケプストラムの応用分野
ケプストラム分析は音声処理に留まらず、幅広い分野で活用されています。
機械診断: 回転機械の振動信号にケプストラム分析を適用することで、歯車の欠陥やベアリングの損傷を示すサイドバンド成分を抽出できます。ケフレンシーピークの位置が欠陥の繰り返し周期に対応します。近年ではケプストラム前白色化(Cepstrum Pre-Whitening, CPW)を拡張した手法も提案されており、Kiakojouri et al. (2023) は共振周波数帯を自動探索するバンドパスフィルタ群と組み合わせた ICPW-HPF(Improved Cepstrum Pre-Whitening with High-Pass Filtering)を提案し、従来のCPW単体では検出が難しい軸受の微弱な初期欠陥信号の検出性能を向上させています( Sensors, 23(22), 9048 )。
地震解析: 地震波のデコンボルーションに利用され、震源特性と伝播特性の分離に応用されます。
エコー除去: 音響エコーの遅延と振幅をケプストラムから推定し、除去フィルタを設計します。
まとめ
- ケプストラムは対数スペクトルの逆フーリエ変換であり、「スペクトルのスペクトル」という概念を持つ
- ソース・フィルタモデルに基づき、ケプストラムの低ケフレンシー成分は声道スペクトル包絡、高ケフレンシー成分は音源ハーモニクスに対応する
- リフタリング(ケプストラム領域での窓処理)によって音源と声道特性を分離でき、スペクトル包絡推定に有効である
- ケプストラムのピッチ推定は \(1/f_0\) に対応するケフレンシーピークを検出することで実現できる
- MFCCはケプストラム分析にメルスケールとDCTを組み合わせた音声認識の標準特徴量である
- ケプストラム分析は音声処理のみならず、機械診断・地震解析・エコー除去など幅広い分野で応用される
関連記事
- 高速フーリエ変換(FFT)の仕組みとPython実装 - ケプストラム計算の基礎となるFFT/DFTを解説しています。
- 窓関数とパワースペクトル密度(PSD)の理論とPython実装 - スペクトル解析の基礎とPSD推定手法を解説しています。
- 短時間フーリエ変換(STFT)の理論とPython実装 - 時間変化する信号のスペクトログラム解析を解説しています。
- 自己相関・相互相関の理論とPython実装 - ケプストラムと関連するF0推定手法(YIN)との比較になります。
- ウェーブレット変換の理論とPython実装 - 時間-周波数解析の別アプローチを解説しています。
- ARIMAモデルによる時系列予測 - スペクトル分析と補完的な時系列モデリング手法です。
- 適応フィルタの理論とPython実装 - ケプストラムのエコー除去応用と関連するフィルタ設計を解説しています。
- 畳み込みと相関の理論とPython実装 - ケプストラムが畳み込みを「対数スペクトル+逆フーリエ」で分解する操作であることを支える畳み込み・相関の基礎を解説しています。
- テーガー・カイザーエネルギー演算子(TKEO)の理論とPython実装 - 音声のオンセット/エネルギー検出という点でケプストラムと補完的な、3点差分だけの軽量な特徴量抽出手法です。
参考文献
- Bogert, B. P., Healy, M. J. R., & Tukey, J. W. (1963). “The quefrency alanysis of time series for echoes: Cepstrum, pseudo-autocovariance, cross-cepstrum, and saphe cracking.” Proceedings of the Symposium on Time Series Analysis, 209-243.
- Oppenheim, A. V., & Schafer, R. W. (2004). “From frequency to quefrency: A history of the cepstrum.” IEEE Signal Processing Magazine, 21(5), 95-106.
- de Cheveigné, A., & Kawahara, H. (2002). “YIN, a fundamental frequency estimator for speech and music.” Journal of the Acoustical Society of America, 111(4), 1917-1930.
- Davis, S., & Mermelstein, P. (1980). “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences.” IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(4), 357-366.
- Kiakojouri, A., Lu, Z., Mirring, P., Powrie, H., & Wang, L. (2023). “A Novel Hybrid Technique Combining Improved Cepstrum Pre-Whitening and High-Pass Filtering for Effective Bearing Fault Diagnosis Using Vibration Data.” Sensors, 23(22), 9048.
- Python Speech Features (MFCC library)
- Librosa: MFCC implementation