カクテルパーティー問題:動機づけ
騒がしいパーティー会場を想像してください。複数の人が同時に話しており、それぞれ異なる位置に置かれたマイクが、それらの混合音を収録しています。各マイクは特定の話者の声だけを拾うことなく、すべての音源の重ね合わせを録音します。
このとき「各マイクの録音データしか持っていない状態で、個々の音源を復元できるか?」という問いが**カクテルパーティー問題(Cocktail Party Problem)**です。直感的には不可能に思えますが、音源の統計的性質に関する適切な仮定を置けば解くことができます。
この問題を一般化したのが**ブラインド信号源分離(Blind Source Separation, BSS)であり、その最も強力な手法の一つが独立成分分析(Independent Component Analysis, ICA)**です。「ブラインド(盲目的)」という語は、混合プロセスの詳細(どのマイクがどの位置にあるか等)を一切知らずに分離を行うことを意味します。
ICA は音声分離のみならず、EEG・fMRI などの脳神経科学データ解析、金融時系列の要因分解など、幅広い領域で応用されています。
ブラインド信号源分離の数学的定式化
線形混合モデル
\(n\) 個の統計的に独立な信号源 \(s_1(t), s_2(t), \ldots, s_n(t)\) があるとします。これらを縦ベクトルにまとめたものを \(\mathbf{s}(t) \in \mathbb{R}^n\) とします。\(m\) 個のセンサー(マイクや電極)が観測する信号 \(\mathbf{x}(t) \in \mathbb{R}^m\) は、線形混合モデルで表されます:
\[ \mathbf{x}(t) = \mathbf{A}\mathbf{s}(t) \tag{1} \]ここで \(\mathbf{A} \in \mathbb{R}^{m \times n}\) は**混合行列(Mixing Matrix)**です。\(\mathbf{A}\) の各列 \(\mathbf{a}_j\) は \(j\) 番目の信号源がどのようにセンサーに混合されるかを表す「混合ベクトル」です。
ICA の目標は、観測値 \(\mathbf{x}(t)\) のみから 分離行列(Unmixing Matrix) \(\mathbf{W}\) を推定し、
\[ \hat{\mathbf{s}}(t) = \mathbf{W}\mathbf{x}(t) \approx \mathbf{s}(t) \tag{2} \]を達成することです。理想的には \(\mathbf{W} \approx \mathbf{A}^{-1}\) (\(m = n\) の場合)となります。
不定性(Indeterminacy)
ICA には本質的に解決できない不定性が二つあります:
- スケールの不定性: 分離された成分のスケール(振幅)は特定できません。\(\mathbf{A}\) の列を \(c\) 倍すれば \(\mathbf{s}\) を \(1/c\) 倍しても観測値は変わりません。
- 順序の不定性: 分離された成分の順番は特定できません。行列の積は列の並び替えに対して不変な性質を持ちます。
これらの不定性は ICA の実用上の限界であり、後述する「ICA の限界」の節でも触れます。
基本的仮定:独立性と非ガウス性
ICA が成立するためには、次の二つの仮定が必要です。
仮定 1: 統計的独立性
信号源 \(s_i\) と \(s_j\) (\(i \neq j\) )は統計的に独立でなければなりません。統計的独立性は相関がないこと(2次統計量)よりも強い条件で、すべての高次統計量についての独立性を意味します:
\[ p(\mathbf{s}) = \prod_{i=1}^{n} p_i(s_i) \tag{3} \]つまり同時確率密度が周辺確率密度の積に分解できることが条件です。
仮定 2: 非ガウス性
最大でも 1 つの信号源のみがガウス分布に従うことが必要です。この条件の本質は中心極限定理から理解できます。
中心極限定理によると、独立な確率変数の和はガウス分布に近づきます。混合信号 \(x_i = \sum_j a_{ij} s_j\) は、複数の独立な信号源の重み付き和ですから、個々の \(s_j\) よりも「ガウス的」になります。逆に言えば、混合信号の中でより非ガウス的な成分こそが元の独立信号源に近いものです。
ICA はこの原理を逆用して、「最も非ガウス的な方向」を次々と探索することで元の信号源を復元します。
識別可能性定理(Comon, 1994)
上記の仮定 1・仮定 2 が「なぜ ICA を成立させるのか」を数学的に保証するのが、Comon (1994) による識別可能性定理です。天下り的に仮定を置くのではなく、この定理が仮定の必然性を示します。
定理: 信号源ベクトル \(\mathbf{s} = (s_1, \ldots, s_n)\) の各成分が統計的に独立であり、かつ高々 1 つを除いて非ガウス分布に従うとする。観測 \(\mathbf{x} = \mathbf{A}\mathbf{s}\) に対して、ある行列 \(\mathbf{B}\) が \(\mathbf{y} = \mathbf{B}\mathbf{x}\) の各成分を互いに独立にするならば、
\[ \mathbf{B}\mathbf{A} = \mathbf{P}\mathbf{D} \]が成り立つ。ここで \(\mathbf{P}\) は置換行列、\(\mathbf{D}\) は正則な対角行列である。
つまり、「独立性」という条件だけから、混合行列は置換とスケーリングの不定性を除いて一意に定まります。
証明の骨子は統計学における Darmois–Skitovitch の定理 に基づきます:
2 つの独立な確率変数の線形結合
\[ > Y_1 = \sum_{i} a_i X_i, \qquad Y_2 = \sum_{i} b_i X_i > \]が互いに独立であるならば、\(a_i \neq 0\) かつ \(b_i \neq 0\) となるすべての \(X_i\) はガウス分布に従う。
この定理を対偶的に用いると、非ガウスな独立成分が 2 つ以上の観測変数の線形結合に「跨って」混入している限り、その結合同士が独立になることはあり得ません。したがって \(\mathbf{y} = \mathbf{B}\mathbf{A}\mathbf{s}\) の各成分が独立であるためには、各 \(y_i\) が単一の \(s_j\) (の定数倍)に一致するしかなく、これはまさに \(\mathbf{B}\mathbf{A}\) が置換行列と対角行列の積であることを意味します。
この定理は「不定性」の節で述べたスケール・順序の不定性の数学的根拠であると同時に、後述する「ガウス信号源が 2 つ以上あると分離不能である」ことの理論的な裏付けでもあります。
非ガウス性の測度:尖度とネゲントロピー
尖度(Kurtosis)
最もシンプルな非ガウス性の測度は尖度(Kurtosis)、または**超過尖度(Excess Kurtosis)**です:
\[ \text{kurt}(y) = E[y^4] - 3(E[y^2])^2 \tag{4} \]白色化(\(E[y^2] = 1\) )された変数の場合は:
\[ \text{kurt}(y) = E[y^4] - 3 \tag{5} \]- ガウス分布の場合:\(\text{kurt}(y) = 0\)
- 尖った分布(超過尖度 > 0、尖鋒性(Leptokurtic)):音声信号、スパース信号
- 平坦な分布(超過尖度 < 0、扁平性(Platykurtic)):一様分布
尖度の絶対値 \(|\text{kurt}(y)|\) を最大化することで非ガウス的方向を探索できますが、外れ値に対して非常に感度が高いという欠点があります。
ネゲントロピー(Negentropy)
より頑健な非ガウス性の測度として**ネゲントロピー(Negentropy)**があります。エントロピーはガウス分布のとき最大になるという性質を利用します:
\[ J(y) = H(y_{\text{Gauss}}) - H(y) \geq 0 \tag{6} \]ここで \(H\) は微分エントロピー、\(y_{\text{Gauss}}\) は \(y\) と同じ分散を持つガウス変数です。\(J(y) = 0\) はガウス分布のときのみ成立します。
厳密なネゲントロピーの計算はコスト高のため、Hyvärinen & Oja(2000)は次の近似を提案しました:
\[ J(y) \approx \left[E\{G(y)\} - E\{G(\nu)\}\right]^2 \tag{7} \]ここで \(\nu\) は標準正規変数、\(G\) は非二次の非線形関数です。実用的な選択肢として:
\[ G_1(u) = \frac{1}{a}\log\cosh(au), \quad g_1(u) = \tanh(au) \tag{8} \] \[ G_2(u) = -\exp\left(-\frac{u^2}{2}\right), \quad g_2(u) = u\exp\left(-\frac{u^2}{2}\right) \tag{9} \]が挙げられます。\(G_1\) は汎用的、\(G_2\) は超ガウス的(スパース)な信号に適しています。
FastICA アルゴリズム
FastICA は Hyvärinen & Oja(1997, 2000)によって提案された、ネゲントロピーを最大化する高速な固定点反復アルゴリズムです。
前処理:白色化(Whitening)
アルゴリズムを実行する前に、観測データを**白色化(Whitening / Sphering)**します。白色化とは、データの共分散行列を単位行列にする変換です:
\[ E[\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T] = \mathbf{I} \tag{10} \]PCA を用いて固有値分解 \(\mathbf{C} = \mathbf{E}\mathbf{D}\mathbf{E}^T\) を求め、
\[ \tilde{\mathbf{x}} = \mathbf{D}^{-1/2}\mathbf{E}^T\mathbf{x} \tag{11} \]と変換します。白色化後の混合行列はユニタリ行列になるため、探索空間が大幅に縮小されます。
固定点反復(Fixed-Point Iteration)
1 成分目の重みベクトル \(\mathbf{w} \in \mathbb{R}^n\) を推定するアルゴリズムは以下の通りです:
1. 初期化: \(\mathbf{w}\) をランダムに初期化し、\(\|\mathbf{w}\| = 1\) に正規化。
2. 更新則(式12):
\[ \mathbf{w} \leftarrow E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{w} \tag{12} \]ここで \(g = G'\) は選択した非線形関数の一次導関数、\(g'\) はその導関数です。
3. 正規化: \(\mathbf{w} \leftarrow \mathbf{w} / \|\mathbf{w}\|\)
4. 収束判定: \(|\mathbf{w}_{\text{new}}^T \mathbf{w}_{\text{old}} - 1| < \epsilon\) になるまで繰り返す。
式(12)の導出:ニュートン法による固定点更新
式(12)は天下り的に与えられる公式ではなく、制約付き最適化問題にニュートン法を適用することで導かれます(Hyvärinen, 1999)。
白色化データ \(\tilde{\mathbf{x}}\) (\(E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\} = \mathbf{I}\) )の上で、ネゲントロピー近似 \(J(\mathbf{w}^T\tilde{\mathbf{x}}) \approx [E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{G(\nu)\}]^2\) を最大化したい。第 2 項は \(\mathbf{w}\) に依存しない定数であり、符号によらず絶対値を大きくすればよいので、実質的な最適化問題は次のように書けます:
\[ \max_{\mathbf{w}} \; E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} \quad \text{s.t.} \quad E\{(\mathbf{w}^T\tilde{\mathbf{x}})^2\} = \|\mathbf{w}\|^2 = 1 \]白色化により制約 \(E\{(\mathbf{w}^T\tilde{\mathbf{x}})^2\} = \mathbf{w}^T\mathbf{w}\) は単位球面上への制約 \(\|\mathbf{w}\| = 1\) に帰着します。ラグランジュ関数
\[ F(\mathbf{w}) = E\{G(\mathbf{w}^T\tilde{\mathbf{x}})\} - \beta(\|\mathbf{w}\|^2 - 1) \]の勾配をゼロとおくと、最適性の必要条件が得られます:
\[ \nabla_{\mathbf{w}} F(\mathbf{w}) = E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w} = \mathbf{0} \tag{12a} \]この非線形方程式を \(\mathbf{H}(\mathbf{w}) \equiv E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w} = \mathbf{0}\) として、\(\mathbf{w}\) についてニュートン法で解きます。\(\mathbf{H}\) のヤコビ行列は
\[ J_{\mathbf{H}}(\mathbf{w}) = E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\, g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{I} \]ここで FastICA 特有の近似を用います。\(\mathbf{w}^T\tilde{\mathbf{x}}\) が真の独立成分に近ければ、\(\tilde{\mathbf{x}}\) とほぼ無相関になるため、期待値の分離
\[ E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\, g'(\mathbf{w}^T\tilde{\mathbf{x}})\} \approx E\{\tilde{\mathbf{x}}\tilde{\mathbf{x}}^T\}\, E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} = E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{I} \]が近似的に成立し、ヤコビ行列は対角行列 \(J_{\mathbf{H}}(\mathbf{w}) \approx [E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta]\mathbf{I}\) に単純化されます。対角行列の逆行列は自明に計算できるため、ニュートン更新式
\[ \mathbf{w}_{\text{new}} = \mathbf{w} - J_{\mathbf{H}}(\mathbf{w})^{-1}\mathbf{H}(\mathbf{w}) \]に代入すると
\[ \mathbf{w}_{\text{new}} = \mathbf{w} - \frac{E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta\mathbf{w}}{E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta} \]両辺に分母 \([E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\} - 2\beta]\) を掛けて整理すると(後段でどのみち正規化するため、全体に掛かるスカラー倍は結果に影響しません)
\[ \mathbf{w}_{\text{new}} \; \propto \; E\{\tilde{\mathbf{x}}\, g(\mathbf{w}^T\tilde{\mathbf{x}})\} - E\{g'(\mathbf{w}^T\tilde{\mathbf{x}})\}\,\mathbf{w} \]これがまさに式(12)です。ニュートン法に由来するため、FastICA は勾配上昇法(1 次収束)よりもはるかに高速な収束性(局所的に 2〜3 次収束)を持ちます。後段の実装例(カクテルパーティー問題)では、この固定点反復が tol=1e-4 の収束判定のもとで実際に 5 回の反復で収束することが確認できます。
デフレーション法と対称的直交化
複数の独立成分を求める際には、既に求めた成分との重複を排除する必要があります。
デフレーション法(Deflation Approach): 成分を 1 つずつ順番に求め、グラム・シュミット直交化を適用します:
\[ \mathbf{w}_p \leftarrow \mathbf{w}_p - \sum_{j=1}^{p-1} (\mathbf{w}_p^T \mathbf{w}_j)\mathbf{w}_j \tag{13} \]デフレーション法は最初の成分ほど高精度になりやすく、誤差が伝播する欠点があります。
対称的直交化(Symmetric Decorrelation): すべての成分を同時に推定し、行列全体を一括で直交化します:
\[ \mathbf{W} \leftarrow (\mathbf{W}\mathbf{W}^T)^{-1/2}\mathbf{W} \tag{14} \]\((...)^{-1/2}\) は行列の対称平方根の逆行列(固有値分解で計算)を表します。全成分が均等に扱われるため、より安定した推定が得られます。
アルゴリズム全体のフロー
1. データを白色化(zero-mean, 単位分散)
2. W をランダム初期化
3. 各成分について固定点反復を収束まで実行
4. デフレーション or 対称的直交化で成分間の重複を除去
5. 推定信号 ŝ = Wx̃ を計算
PCA と ICA の比較
主成分分析(PCA)の復習
PCA は観測データの共分散行列を固有値分解し、最大分散方向を順番に求めます。得られた主成分は**無相関(Uncorrelated)**ですが、必ずしも独立ではありません。PCA は 2 次統計量(共分散)のみを使用します。
ICA との本質的な違い
| 性質 | PCA | ICA |
|---|---|---|
| 前提 | 2 次統計量のみ | 高次統計量(独立性) |
| 出力の性質 | 無相関(Uncorrelated) | 独立(Independent) |
| ガウス信号への対応 | 可能 | 不可(ガウス信号は分離不能) |
| スケール・順序 | 分散の大きい順 | 未定(不定性あり) |
| 幾何学的解釈 | 分散最大化(回転) | 非ガウス性最大化(任意の線形変換) |
| 主な用途 | 次元削減、可視化 | 信号源分離、特徴抽出 |
| 白色化 | アルゴリズム出力 | ICA の前処理として利用 |
重要な点として、白色化は PCA と同一の変換ですが、ICA はさらにその先の「回転」を決定します。PCA は分散を最大化する方向(直交軸)を見つけますが、ICA はその中から非ガウス性を最大化する方向を選択します。
幾何学的な確認:PCA は白色化止まり、ICA はさらに回転する
言葉で説明した「PCA は楕円を正円に変換するところまで、ICA はさらに円を回転させる」という主張を、実際にデータを生成して確認します。2 つの独立な一様分布信号源 \(s_1, s_2 \sim \text{Uniform}(-1, 1)\) を非直交行列で混合すると、観測データの散布図は平行四辺形になります。この平行四辺形を PCA で白色化しても、得られる図形は依然として(軸に対して斜めの)正方形のままで、真の信号源方向とは一致しません。ICA はそこからさらに回転を加え、正方形を座標軸に揃えます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import FastICA, PCA
from itertools import permutations
np.random.seed(7)
# ---- 1. 独立な一様分布信号源(非ガウス)を生成 ----
n = 3000
s1 = np.random.uniform(-1, 1, n)
s2 = np.random.uniform(-1, 1, n)
S = np.c_[s1, s2]
# ---- 2. 非直交な行列で混合(観測データは平行四辺形になる) ----
A = np.array([[2.0, 1.0],
[0.5, 1.5]])
X = S @ A.T
# ---- 3. 白色化(PCAで分散1に正規化) ----
pca = PCA(n_components=2, whiten=True)
X_white = pca.fit_transform(X)
# ---- 4. ICA でさらに回転して軸を揃える ----
ica = FastICA(n_components=2, whiten="unit-variance", random_state=7, max_iter=1000)
S_ica = ica.fit_transform(X)
# ---- 定量評価: 真の信号源との相関 ----
def best_correlation(S_true, S_est):
n_comp = S_true.shape[1]
best_corr = 0.0
for perm in permutations(range(n_comp)):
corrs = [abs(np.corrcoef(S_true[:, i], S_est[:, j])[0, 1])
for i, j in enumerate(perm)]
avg = np.mean(corrs)
best_corr = max(best_corr, avg)
return best_corr
print(f"PCA白色化後の各成分の分散: {X_white.var(axis=0)}")
print(f"白色化(PCA)出力と真の信号源の平均絶対相関: {best_correlation(S, X_white):.4f}")
print(f"ICA復元と真の信号源の平均絶対相関: {best_correlation(S, S_ica):.4f}")
# ---- 図示: 観測データ/PCA白色化後/ICA適用後の散布図 ----
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].scatter(X[:, 0], X[:, 1], s=6, alpha=0.35, color="steelblue")
axes[0].set_title("Observed mixture x = As")
axes[0].set_xlabel("$x_1$"); axes[0].set_ylabel("$x_2$")
axes[0].set_aspect("equal"); axes[0].grid(True, alpha=0.3)
axes[1].scatter(X_white[:, 0], X_white[:, 1], s=6, alpha=0.35, color="steelblue")
axes[1].set_title("After PCA whitening\n(square, but axes not aligned)")
axes[1].set_xlabel("whitened $x_1$"); axes[1].set_ylabel("whitened $x_2$")
axes[1].set_aspect("equal"); axes[1].grid(True, alpha=0.3)
axes[2].scatter(S_ica[:, 0], S_ica[:, 1], s=6, alpha=0.35, color="crimson")
axes[2].set_title("After ICA\n(axes aligned with independent sources)")
axes[2].set_xlabel(r"$\hat{s}_1$"); axes[2].set_ylabel(r"$\hat{s}_2$")
axes[2].set_aspect("equal"); axes[2].grid(True, alpha=0.3)
plt.suptitle("PCA stops at whitening; ICA rotates further to align with independent sources")
plt.tight_layout()
plt.savefig("ica_geometry_pca_vs_ica.png", dpi=150, bbox_inches="tight")
plt.show()
実際に実行すると次の値が得られます:
PCA白色化後の各成分の分散: [0.99966667 0.99966667]
白色化(PCA)出力と真の信号源の平均絶対相関: 0.7650
ICA復元と真の信号源の平均絶対相関: 1.0000
PCA 白色化後の分散はほぼ 1(設計通り)ですが、真の信号源との相関は 0.7650 にとどまります。つまり分散は揃っても、軸の向きは信号源と一致していません。一方 ICA は相関 1.0000、すなわちほぼ完全な復元を達成しています。実際にこの実行では、ICA は白色化後のデータに対しさらに約 50.4° の追加回転を適用していました。図示すると次のようになります。
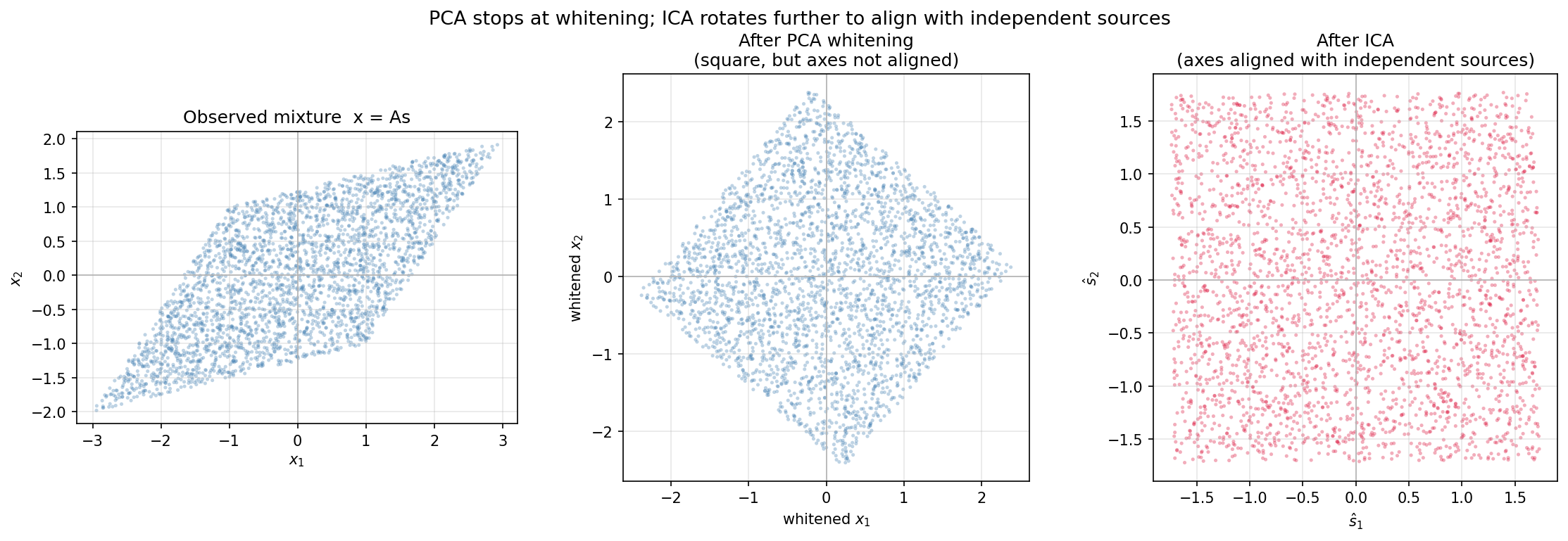
左のパネルは観測データ \(\mathbf{x} = \mathbf{A}\mathbf{s}\) の散布図で、平行四辺形の形をしています。中央のパネルは PCA 白色化後で、共分散は単位行列になり図形は正方形になりますが、軸に対して斜めに傾いたままです(無相関ではあるが独立ではない)。右のパネルは ICA 適用後で、正方形が座標軸に揃い、\(\hat{s}_1\) と \(\hat{s}_2\) が完全に独立な一様分布として復元されています。
Python 実装
カクテルパーティー問題のシミュレーション
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import FastICA, PCA
np.random.seed(42)
# ---- 1. 信号源の生成 ----
n_samples = 2000
t = np.linspace(0, 8 * np.pi, n_samples)
# 3つの独立な信号源(正弦波、鋸歯波、方形波)
s1 = np.sin(t) # 正弦波
s2 = (t % (2 * np.pi) / np.pi - 1.0) # 鋸歯波
s3 = np.sign(np.sin(2.5 * t)) # 方形波
S = np.c_[s1, s2, s3]
S /= S.std(axis=0) # 各信号の標準偏差を1に正規化
# ---- 2. ランダムな混合行列で混合 ----
A = np.array([[1.0, 1.0, 1.0],
[0.5, 2.0, 1.0],
[1.5, 1.0, 2.0]])
X = S @ A.T # 観測信号: shape = (n_samples, 3)
# ---- 3. FastICA で分離 ----
ica = FastICA(n_components=3, max_iter=500, tol=1e-4, random_state=42)
S_ica = ica.fit_transform(X)
# ---- 4. PCA で比較 ----
pca = PCA(n_components=3)
S_pca = pca.fit_transform(X)
# ---- 5. プロット ----
fig, axes = plt.subplots(3, 3, figsize=(15, 9))
labels = ["Sine", "Sawtooth", "Square"]
colors = ["steelblue", "darkorange", "seagreen"]
for i in range(3):
# 元の信号源
axes[0, i].plot(t[:300], S[:300, i], color=colors[i], linewidth=1.2)
axes[0, i].set_title(f"Source: {labels[i]}")
axes[0, i].set_xlim(0, t[299])
axes[0, i].grid(True, alpha=0.4)
for i in range(3):
# 混合信号
axes[1, i].plot(t[:300], X[:300, i], color="gray", linewidth=1.2)
axes[1, i].set_title(f"Mixed signal {i + 1}")
axes[1, i].set_xlim(0, t[299])
axes[1, i].grid(True, alpha=0.4)
for i in range(3):
# ICA 復元信号
comp = S_ica[:300, i]
comp /= np.abs(comp).max() # 振幅を正規化して表示
axes[2, i].plot(t[:300], comp, color="crimson", linewidth=1.2)
axes[2, i].set_title(f"ICA component {i + 1}")
axes[2, i].set_xlim(0, t[299])
axes[2, i].grid(True, alpha=0.4)
axes[0, 0].set_ylabel("Original Sources", fontsize=11)
axes[1, 0].set_ylabel("Mixed Signals", fontsize=11)
axes[2, 0].set_ylabel("ICA Recovery", fontsize=11)
plt.suptitle("Cocktail Party Problem: ICA Source Separation", fontsize=14)
plt.tight_layout()
plt.savefig("ica_cocktail_party.png", dpi=150, bbox_inches="tight")
plt.show()
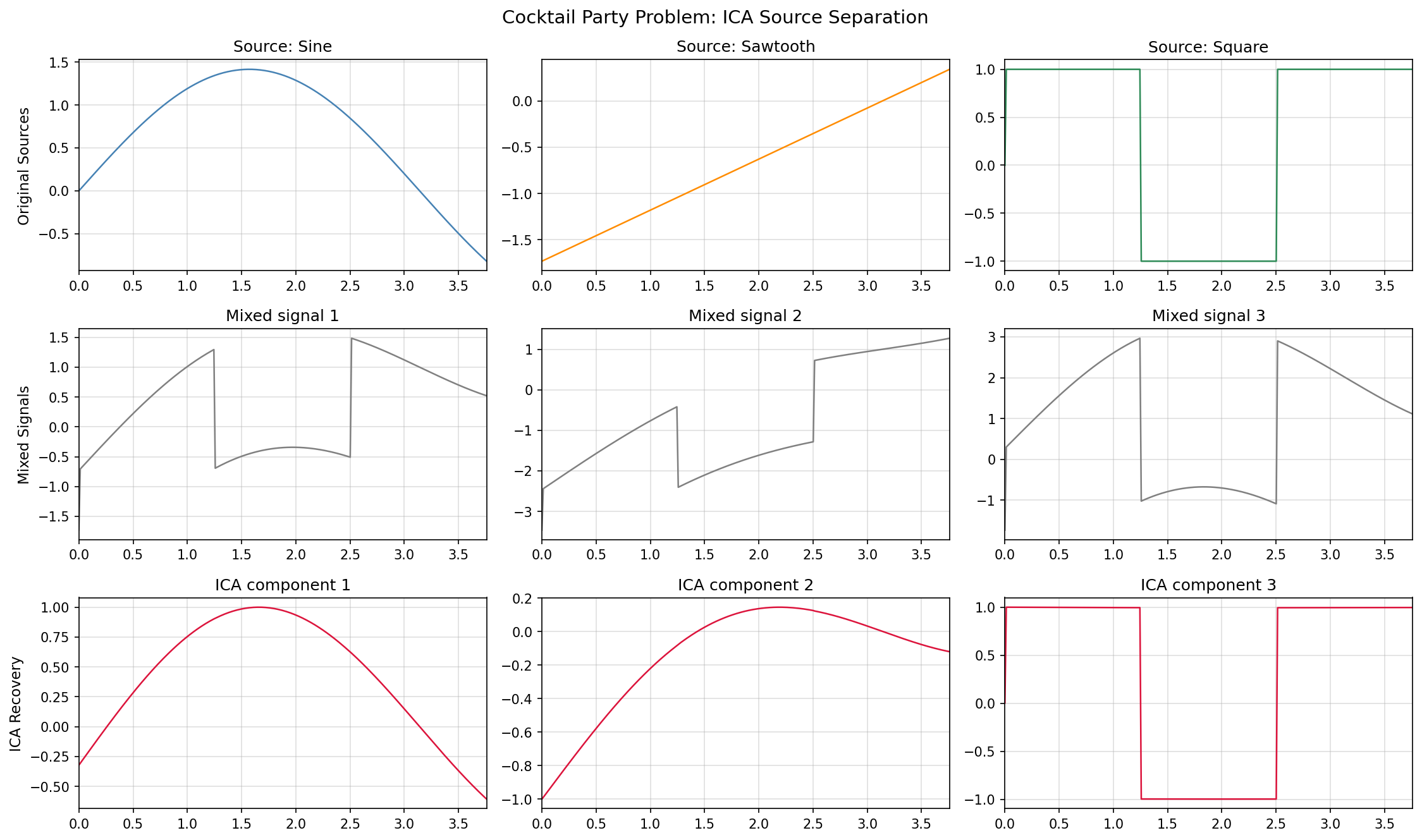
ICA が復元した成分はスケールと符号が不定ですが、波形の形状(正弦波・鋸歯波・方形波)は正確に復元されます。
PCA との復元精度の比較
相関係数を用いて ICA と PCA の復元精度を定量的に比較します。
from itertools import permutations
def best_correlation(S_true, S_est):
"""最適な成分の対応付けによる平均絶対相関係数を返す"""
n = S_true.shape[1]
best_corr = 0.0
for perm in permutations(range(n)):
corrs = []
for i, j in enumerate(perm):
r = np.corrcoef(S_true[:, i], S_est[:, j])[0, 1]
corrs.append(abs(r))
avg = np.mean(corrs)
if avg > best_corr:
best_corr = avg
return best_corr
corr_ica = best_correlation(S, S_ica)
corr_pca = best_correlation(S, S_pca)
print(f"ICA 平均絶対相関係数: {corr_ica:.4f}")
print(f"PCA 平均絶対相関係数: {corr_pca:.4f}")
上のコードを実際に実行すると、次の出力が得られます(np.random.seed(42) および random_state=42 により再現可能):
ICA 平均絶対相関係数: 0.9120
PCA 平均絶対相関係数: 0.7708
ICA は PCA よりも高い相関係数で元の信号源を復元しています。ただし、この 3 信号源・非直交混合という条件下では ICA の相関係数も 1.0 には届かず 0.9120 にとどまる点に注意してください。正弦波とサンプル数 2000 という有限サンプルでの推定誤差に加え、正弦波はサンプル区間内でおおむね対称な分布を持ち非ガウス性の指標(尖度)が小さいため、分離が相対的に難しい信号源です。先述の「幾何学的な確認」の例(独立な一様分布 2 信号源、相関 1.0000)と比べると、信号源の非ガウス性の強さが分離精度に直接影響することが分かります。PCA は分散最大化の方向を返すため、いずれの実験でも信号源の復元精度は ICA に劣ります。
EEG アーティファクト除去の例
EEG(脳波)データには、眼球運動(眼電図、EOG)や筋電図(EMG)などのアーティファクトが混入します。ICA は、これらの独立した「ノイズ源」と「脳波源」を分離するために広く利用されています。
np.random.seed(0)
# ---- EEG ライクなデータを生成 ----
n_samples = 3000
t = np.linspace(0, 6, n_samples) # 6秒間
# 脳波成分(アルファ波 10Hz、シータ波 6Hz)
alpha = np.sin(2 * np.pi * 10 * t) * 0.5
theta = np.sin(2 * np.pi * 6 * t) * 0.3
# アーティファクト成分(眼球運動: 低周波大振幅、筋電: 高周波)
eye_blink = np.zeros(n_samples)
blink_positions = [500, 1200, 2100, 2700]
for pos in blink_positions:
width = 80
idx = np.arange(max(0, pos - width), min(n_samples, pos + width))
eye_blink[idx] += np.exp(-0.5 * ((idx - pos) / 30) ** 2) * 3.0
rng = np.random.default_rng(42)
muscle = rng.standard_normal(n_samples) * 0.2 # 高周波ノイズ
# 4 成分(アルファ、シータ、眼球運動、筋電)を 4 チャンネルに混合
sources = np.c_[alpha, theta, eye_blink, muscle]
A_eeg = np.array([
[1.0, 0.8, 2.0, 0.5],
[0.7, 1.0, 1.5, 0.8],
[0.5, 0.6, 1.0, 0.3],
[0.9, 0.4, 0.8, 1.0],
])
X_eeg = sources @ A_eeg.T
# ---- ICA でアーティファクト成分を分離 ----
ica_eeg = FastICA(n_components=4, max_iter=1000, tol=1e-5, random_state=0)
components = ica_eeg.fit_transform(X_eeg)
# ---- アーティファクト成分を特定して除去 ----
# 実際の解析では成分の波形・パワースペクトルを目視確認するが、
# ここでは尖度が最も大きい成分(眼球運動)を自動特定
kurtosis_vals = []
for i in range(4):
c = components[:, i]
c_norm = (c - c.mean()) / c.std()
kurt = np.mean(c_norm**4) - 3
kurtosis_vals.append(abs(kurt))
artifact_idx = np.argmax(kurtosis_vals)
print(f"アーティファクト成分と判定: 成分 {artifact_idx} (尖度絶対値: {kurtosis_vals[artifact_idx]:.2f})")
# アーティファクト成分をゼロにして信号を再合成
components_clean = components.copy()
components_clean[:, artifact_idx] = 0.0
X_clean = components_clean @ ica_eeg.mixing_.T + ica_eeg.mean_
# ---- プロット ----
fig, axes = plt.subplots(3, 1, figsize=(14, 10))
time_range = slice(0, 1000) # 最初の2秒
for ch in range(4):
offset = ch * 4
axes[0].plot(t[time_range], X_eeg[time_range, ch] + offset,
linewidth=0.8, label=f"ch {ch+1}")
axes[0].set_title("EEG: 混合信号(4チャンネル)")
axes[0].set_ylabel("振幅 (a.u.)")
axes[0].legend(loc="upper right", fontsize=9)
axes[0].grid(True, alpha=0.3)
for i in range(4):
c = components[time_range, i]
c /= np.abs(c).max() + 1e-10
axes[1].plot(t[time_range], c + i * 2.5,
linewidth=0.8,
label=f"IC{i} (kurt={kurtosis_vals[i]:.1f})" +
(" ← artifact" if i == artifact_idx else ""))
axes[1].set_title("ICA 独立成分")
axes[1].set_ylabel("振幅 (正規化)")
axes[1].legend(loc="upper right", fontsize=9)
axes[1].grid(True, alpha=0.3)
for ch in range(4):
offset = ch * 4
axes[2].plot(t[time_range], X_clean[time_range, ch] + offset,
linewidth=0.8, label=f"ch {ch+1}")
axes[2].set_title("アーティファクト除去後の EEG")
axes[2].set_xlabel("時間 (s)")
axes[2].set_ylabel("振幅 (a.u.)")
axes[2].legend(loc="upper right", fontsize=9)
axes[2].grid(True, alpha=0.3)
plt.suptitle("ICA による EEG アーティファクト除去", fontsize=14)
plt.tight_layout()
plt.savefig("ica_eeg_artifact.png", dpi=150, bbox_inches="tight")
plt.show()
上のコードを実際に実行すると、次の出力が得られます(random_state=0 および np.random.default_rng(42) により再現可能):
アーティファクト成分と判定: 成分 0 (尖度絶対値: 5.46)
4 つの独立成分それぞれの尖度絶対値は IC0(眼球運動)が 5.4568、IC1(アルファ波)が 1.4990、IC2(シータ波)が 1.4854、IC3(筋電ノイズ)が 0.0141 でした。眼球運動成分の尖度が突出して大きく、また筋電ノイズはガウス分布(正規分布)に近いホワイトノイズであるため尖度がほぼ 0 になっている点に注目してください。これは後述する「ガウス信号源は分離不能」という限界の裏返しでもあり、ガウス的な筋電ノイズ自体を ICA で他の脳波成分ときれいに切り分けることは原理的に難しくなります。
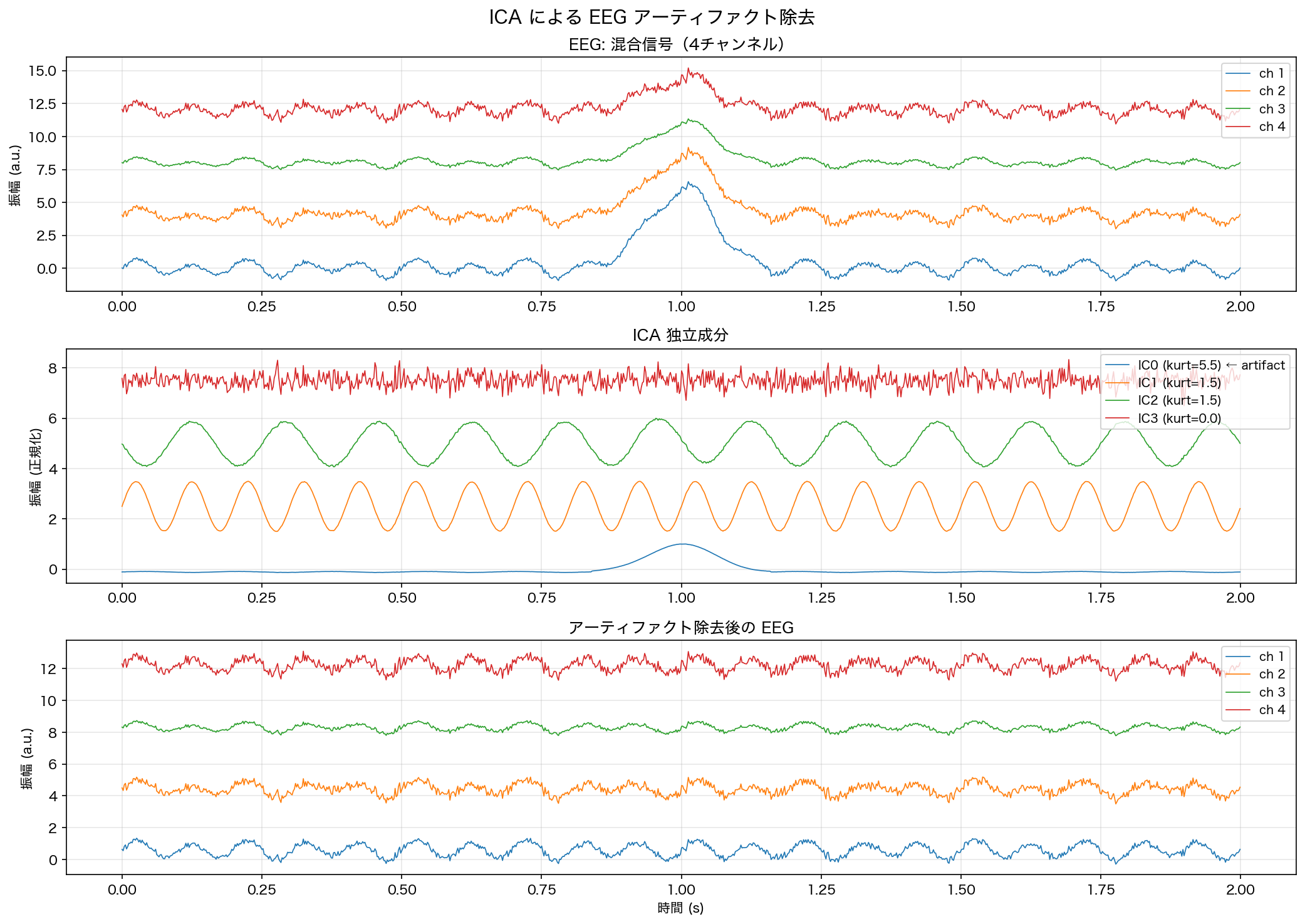
眼球運動成分(IC0)は、低周波で大振幅のパルス状波形を持つため尖度が大きく、自動的にアーティファクトとして特定できます。ICA 成分のうちその成分のみをゼロにして再合成(逆変換)することで、アーティファクトを除去した EEG を得ます。上段と下段の図を比較すると、1 秒付近に見られた眼球運動由来のパルス状の膨らみが除去後の EEG では消えており、他のチャンネルの波形はほぼ保たれていることが確認できます。
ICA の限界と ICA が機能しない場合
ICA は強力な手法ですが、以下のような根本的な限界と適用できないケースがあります。
限界 1: スケールと順序の不定性
式(1)~(2)で示したように、復元された成分のスケール(振幅)と順序を一意に決定することはできません。これは ICA の数学的構造から来る本質的な不定性です。実用上はスケールを正規化し、波形の形状や周波数特性によって成分を解釈します。
限界 2: ガウス信号源は分離不能
すべての信号源がガウス分布に従う場合、ICA は機能しません。ガウス分布は 2 次統計量(平均・分散)で完全に特徴付けられ、高次統計量を利用する ICA では区別できないからです。2 つのガウス変数の直交変換は同じ結合分布を持ちます(等方性)。
限界 3: 信号源数 ≤ センサー数の仮定
標準的な ICA では信号源の数がセンサーの数以下でないと、方程式が underdetermined になります(\(n \leq m\) が必要)。過多信号(\(n > m\) )の場合は過完全 ICA や疎な ICA などの拡張手法が必要です。
限界 4: 線形混合の仮定
ICA のモデル式(1)は線形混合を仮定しています。音波の反射・回折、非線形センサー特性などが存在する実際の問題では、線形 ICA の精度は劣化します。非線形 ICA も研究されていますが、理論的・実用的な課題が多く残っています。
限界 5: 時間的独立性は考慮しない
基本的な ICA は各時刻 \(t\) のデータを独立なサンプルとして扱い、時系列の依存構造を考慮しません。時間的な依存性( 自己相関 など)を活用する手法として SOBI(Second-Order Blind Identification)などがあります。
ICA の適用可否まとめ
| 条件 | ICA の適用可否 |
|---|---|
| 信号源が非ガウス的 | 適用可 |
| 信号源が独立 | 適用可 |
| 混合が線形 | 適用可 |
| 信号源が全てガウス分布 | 不可 |
| 信号源数 > センサー数 | 拡張が必要 |
| 混合が非線形 | 別手法が必要 |
応用例
脳神経科学(EEG / fMRI)
EEG アーティファクト除去は ICA の最も広く使われている応用の一つです。眼球運動(10〜20μV 規模)、心電図(ECG)、筋電図(EMG)などの成分は、脳活動(EEG)と統計的に独立であるため、ICA によって効果的に分離できます。fMRI では空間的 ICA(sDR-ICA)を用いて、デフォルトモードネットワークなどの機能的脳領域を自動的に抽出します。
近年は ICA を置き換える/補完する深層学習ベースの手法も研究が進んでいます。例えば Kalita, Deb, & Das(2024, Scientific Reports)が提案した AnEEG は LSTM ベースの GAN(敵対的生成ネットワーク)を用いてアーティファクトを除去する手法で、従来法(ICA・離散ウェーブレット変換・他の GAN ベース手法)を NMSE・RMSE の指標で上回ったと報告されています。この研究では、ICA はアーティファクト成分の手動選別が必要でありコストが高いという実務上の課題が指摘されており、本記事の EEG の例で用いた「尖度による自動判定」はまさにこの課題(成分選別の自動化)に対する簡易な対処法の一つと位置づけられます。ただし ICA は教師データを必要としないブラインド手法であり、ラベル付きデータが乏しい状況でも適用できるという利点は深層学習ベース手法にはない強みです。
音声・音楽処理
カクテルパーティー問題の直接的な応用として、複数のマイクで収録した混合音声から各話者の音声を分離する話者分離があります。また楽器ごとの音源分離、ノイズ除去にも応用されています。
金融データ分析
複数の金融資産の収益率の時系列に ICA を適用すると、共通の経済ファクター(市場全体の動き、業種特有のリスク等)を独立な成分として抽出できます。これは PCA によるファクター分析よりも経済的に解釈しやすい成分を与えることがあります。
通信・センサーアレイ
CDMA(符号分割多元接続)や MIMO 通信において、複数のアンテナで受信した混合信号から個々のユーザーの信号を分離するために使われます。また地震波解析や気象データのパターン抽出にも応用されています。
関連手法との位置づけ
適応フィルタ(LMS/RLS) との比較では、適応フィルタは所望信号の参照信号が既知の教師あり手法であるのに対し、ICA は参照信号が不要なブラインド手法です。 ウェーブレット変換 は時間周波数解析のツールですが、ICA は信号源の統計的独立性を利用した異なるアプローチです。
まとめ
独立成分分析(ICA)の要点を整理します:
問題設定: 混合行列 \(\mathbf{A}\) を知らずに観測値 \(\mathbf{x} = \mathbf{A}\mathbf{s}\) から独立な信号源 \(\mathbf{s}\) を復元するブラインド信号源分離問題。
キー仮定: 信号源の統計的独立性と非ガウス性。中心極限定理の逆用として、「最も非ガウス的な方向」が元の信号源に対応。
測度: 尖度(\(E[y^4] - 3\) )は単純だが外れ値感度が高い。ネゲントロピーは頑健だが近似が必要。FastICA は \(\tanh\) などの非線形関数を使った近似ネゲントロピーを最大化。
FastICA: 白色化後に固定点反復で各成分を推定。デフレーション法または対称的直交化で成分間の独立性を確保。
PCA との違い: PCA は 2 次統計量(無相関)、ICA は高次統計量(独立)を最大化。信号源分離には ICA が必要。
限界: ガウス信号源は分離不能、スケール・順序の不定性、線形混合の仮定。
sklearn の FastICA は実用上十分な精度と速度を提供し、EEG 解析や音声分離への応用が容易です。
関連記事
- 適応フィルタ(LMS/RLS):理論とPython実装 — 参照信号を使った教師あり信号分離手法。ICA とは対照的なアプローチ。
- ウェーブレット変換の基礎と応用 — 時間周波数解析の基礎。ICA と組み合わせた EEG 解析でも使われる。
- 自己相関関数(ACF)とパワースペクトル密度 — 信号の時系列的依存構造の解析。SOBI など時系列 ICA との関連。
- 時系列異常検知の手法まとめ — ICA で抽出した独立成分を異常検知に応用するアプローチも存在。
参考文献
- Hyvärinen, A., & Oja, E. (2000). Independent component analysis: algorithms and applications. Neural Networks, 13(4–5), 411–430.
- Hyvärinen, A. (1999). Fast and robust fixed-point algorithms for independent component analysis. IEEE Transactions on Neural Networks, 10(3), 626–634.
- Bell, A. J., & Sejnowski, T. J. (1995). An information-maximization approach to blind separation and blind deconvolution. Neural Computation, 7(6), 1129–1159.
- Comon, P. (1994). Independent component analysis, a new concept? Signal Processing, 36(3), 287–314.
- Hyvärinen, A., Karhunen, J., & Oja, E. (2001). Independent Component Analysis. John Wiley & Sons.
- Makeig, S., Bell, A. J., Jung, T. P., & Sejnowski, T. J. (1996). Independent component analysis of electroencephalographic data. Advances in Neural Information Processing Systems, 8, 145–151.
- Kalita, B., Deb, N., & Das, D. (2024). AnEEG: leveraging deep learning for effective artifact removal in EEG data. Scientific Reports, 14, 24234.