はじめに
LMS(Least Mean Squares)アルゴリズムは、ウィーナーフィルタの最適解を確率的勾配降下法で逐次近似する適応フィルタ手法です。実装が極めて単純(演算量 \(O(L)\) )で安定性も高いため、エコーキャンセラ、ノイズキャンセレーション、チャネル等化、システム同定など幅広い分野で実用されています。
定常確率過程を前提とした ウィーナーフィルタ は、信号統計(自己相関 \(R_{yy}\) と相互相関 \(R_{sy}\) )が既知という強い仮定を置きます。LMSは統計が未知でも観測サンプルから直接フィルタ係数を更新できる点で、より実用的です。
問題設定
長さ \(L\) の FIR 適応フィルタを考えます。時刻 \(n\) における入力ベクトルとフィルタ係数ベクトルを以下のように定義します。
\[ \mathbf{x}(n) = [x(n), x(n-1), \dots, x(n-L+1)]^\top \tag{1} \] \[ \mathbf{w}(n) = [w_0(n), w_1(n), \dots, w_{L-1}(n)]^\top \tag{2} \]フィルタ出力と誤差は
\[ y(n) = \mathbf{w}(n)^\top \mathbf{x}(n), \qquad e(n) = d(n) - y(n) \tag{3} \]ここで \(d(n)\) は所望信号(教師信号)です。目的は、二乗誤差の期待値(コスト関数)
\[ J(\mathbf{w}) = E\bigl[e(n)^2\bigr] \tag{4} \]を最小化する \(\mathbf{w}\) を逐次的に求めることです。
LMSアルゴリズム
勾配の確率的近似
コスト関数 \(J(\mathbf{w})\) の勾配は
\[ \nabla J = -2\, E\bigl[e(n)\, \mathbf{x}(n)\bigr] \tag{5} \]ですが、期待値は実際には計算できません。LMSの核心は、期待値を瞬時値で置き換える確率的勾配近似です。
\[ \hat{\nabla} J(n) = -2\, e(n)\, \mathbf{x}(n) \tag{6} \]これを最急降下法に代入して、係数更新則が得られます。
\[ \mathbf{w}(n+1) = \mathbf{w}(n) + \mu\, e(n)\, \mathbf{x}(n) \tag{7} \]ここで \(\mu > 0\) はステップサイズ(学習率)です。係数 \(2\) は \(\mu\) に吸収しています。
収束条件
平均的な収束(係数の期待値が最適解 \(\mathbf{w}^\ast\) に収束)のためには、ステップサイズが入力相関行列 \(\mathbf{R} = E[\mathbf{x}(n)\mathbf{x}(n)^\top]\) の最大固有値 \(\lambda_{\max}\) に対して
\[ 0 < \mu < \frac{2}{\lambda_{\max}} \tag{8} \]を満たす必要があります。実用上は、入力パワーを使ったより緩い条件
\[ 0 < \mu < \frac{2}{L \cdot P_x}, \qquad P_x = E\bigl[x(n)^2\bigr] \tag{9} \]を採用することが多く、\(\lambda_{\max} \le \mathrm{tr}(\mathbf{R}) = L P_x\) から導かれます。
ステップサイズと挙動の関係は次のとおりです。
| \(\mu\) の大きさ | 挙動 |
|---|---|
| 小さい | 収束が遅いが定常誤差が小さい |
| 中程度 | 収束速度と定常誤差のバランスが良い |
| 大きい | 収束は速いが定常誤差が大きい |
| 上限超過 | 発散(誤差が増大し続ける) |
自己相関 \(\mathbf{R}\) の固有値広がり \(\chi(\mathbf{R}) = \lambda_{\max} / \lambda_{\min}\) が大きいほど収束が遅くなります。詳細は 自己相関関数 を参照してください(固有値拡散の定量的な影響は後述の「固有値拡散の影響」節と実行検証で扱います)。
平均収束の厳密証明
式(8)の収束条件は天下り的に提示しましたが、ここでは重み誤差ベクトルの漸化式から導出します。
真のウィーナー解を \(\mathbf{w}^\ast\) 、重み誤差ベクトルを \(\boldsymbol{\epsilon}(n) = \mathbf{w}(n) - \mathbf{w}^\ast\) と定義します。直交原理(ウィーナー解の最小誤差 \(e_o(n) = d(n) - \mathbf{w}^{\ast\top}\mathbf{x}(n)\) は \(\mathbf{x}(n)\) と無相関、すなわち \(E[e_o(n)\mathbf{x}(n)]=\mathbf{0}\) )より、所望信号は
\[ d(n) = \mathbf{w}^{\ast\top}\mathbf{x}(n) + e_o(n) \tag{10} \]と分解できます。これを式(3)の誤差定義に代入すると
\[ e(n) = -\boldsymbol{\epsilon}(n)^\top\mathbf{x}(n) + e_o(n) \tag{11} \]を得ます。式(7)の更新則に代入して整理すると、重み誤差ベクトルの漸化式が求まります。
\[ \boldsymbol{\epsilon}(n+1) = \bigl[\mathbf{I} - \mu\,\mathbf{x}(n)\mathbf{x}(n)^\top\bigr]\boldsymbol{\epsilon}(n) + \mu\, e_o(n)\,\mathbf{x}(n) \tag{12} \]ここで独立性仮定(independence assumption;Haykin等の標準的解析で用いられる近似で、入力ベクトル列 \(\{\mathbf{x}(n)\}\) が \(\boldsymbol{\epsilon}(n)\) と統計的に独立とみなす)を置き、両辺の期待値を取ります。\(E[e_o(n)\mathbf{x}(n)]=\mathbf{0}\) より第2項は消え、
\[ E[\boldsymbol{\epsilon}(n+1)] = \bigl[\mathbf{I} - \mu\mathbf{R}\bigr]\, E[\boldsymbol{\epsilon}(n)] \tag{13} \]が得られます(\(\mathbf{R}=E[\mathbf{x}(n)\mathbf{x}(n)^\top]\) )。\(\mathbf{R}\) は対称行列なので直交対角化 \(\mathbf{R}=\mathbf{Q}\boldsymbol{\Lambda}\mathbf{Q}^\top\) が可能です。回転座標 \(\mathbf{v}(n) = \mathbf{Q}^\top E[\boldsymbol{\epsilon}(n)]\) を定義すると、式(13)は固有モードごとに完全に分離します。
\[ v_i(n+1) = (1-\mu\lambda_i)\, v_i(n) \quad\Longrightarrow\quad v_i(n) = (1-\mu\lambda_i)^n\, v_i(0) \tag{14} \]各モードが \(0\) に収束する条件は \(|1-\mu\lambda_i|<1\) 、すなわち \(0<\mu<2/\lambda_i\) です。これがすべての固有値 \(\lambda_i\) について同時に成り立つ必要があるため、最も厳しい制約は最大固有値 \(\lambda_{\max}\) から来て、式(8)の \(0 < \mu < 2/\lambda_{\max}\) が導出されます。同時に式(14)は、収束速度が固有値ごとの幾何級数 \((1-\mu\lambda_i)^n\) で決まることを示しており、次節の固有値拡散の議論に直結します。
固有値拡散(eigenvalue spread)の影響
式(14)より、\(n\) ステップ後の各モードの誤差は \(|1-\mu\lambda_i|^n\) に比例して減衰します。\(\lambda_i\) が小さいモードほど \(|1-\mu\lambda_i|\) が \(1\) に近く、減衰が遅くなります。全体の収束速度は最も遅いモード、すなわち最小固有値 \(\lambda_{\min}\) に支配されます。
\(\mu\) の上限は最大固有値からの制約 \(\mu<2/\lambda_{\max}\) で決まるため、\(\lambda_{\min}\) が \(\lambda_{\max}\) に比べて極端に小さい(固有値拡散 \(\chi(\mathbf{R})=\lambda_{\max}/\lambda_{\min}\) が大きい)場合、最遅モードの収束レート \(1-\mu\lambda_{\min}\) は \(1\) に非常に近くなり、収束が著しく遅くなります。これは強く自己相関した入力信号(狭帯域信号、音声のホルマント構造など)でLMSの収束が実務上問題になる主要因です。この点は後の実行検証で数値的に確認します。
ミスアジャストメント(misadjustment)の導出
LMSは十分小さいステップサイズでウィーナー解近傍に収束しますが、瞬時勾配を使う代償として、収束後も真の最小MSE \(J_{\min}\) より大きい定常誤差が残ります。この超過分をミスアジャストメント \(M = J_{ex}(\infty)/J_{\min}\) (\(J_{ex}(\infty)\) は超過MSE)と呼びます。
式(12)を回転座標 \(\mathbf{v}(n)=\mathbf{Q}^\top\boldsymbol{\epsilon}(n)\) 、\(\mathbf{u}(n)=\mathbf{Q}^\top\mathbf{x}(n)\) (\(E[u_i(n)u_j(n)]=\lambda_i\delta_{ij}\) )で書き直すと、第 \(i\) モードの瞬時値の漸化式は
\[ v_i(n+1) = v_i(n) - \mu\, u_i(n)\Bigl(\textstyle\sum_j u_j(n) v_j(n)\Bigr) + \mu\, e_o(n)\, u_i(n) \tag{15} \]となります。両辺を二乗し期待値を取ると、独立性仮定と \(E[e_o(n)\mathbf{x}(n)]=\mathbf{0}\) により交差項は消えます。\(\mu\lambda_i \ll 1\) を仮定する小ステップサイズ近似(Widrow・Haykinの標準的な解析で用いる近似)のもとで \(\mu^2\) の主要項のみを残すと、
\[ E[v_i(n+1)^2] \approx (1-2\mu\lambda_i)\, E[v_i(n)^2] + \mu^2 \lambda_i\, J_{\min} \tag{16} \]が得られます。定常状態(\(n\to\infty\) )では \(E[v_i(n+1)^2]=E[v_i(n)^2]=E[v_i(\infty)^2]\) となるため、
\[ 2\mu\lambda_i\, E[v_i(\infty)^2] = \mu^2\lambda_i\, J_{\min} \] \[ \Longrightarrow\quad E[v_i(\infty)^2] = \frac{\mu\, J_{\min}}{2} \tag{17} \]興味深いことに、この定常値は \(\lambda_i\) に依存しません。回転が直交変換であること(\(\boldsymbol{\epsilon}^\top\mathbf{R}\boldsymbol{\epsilon}=\mathbf{v}^\top\boldsymbol{\Lambda}\mathbf{v}\) )から超過MSEは \(J_{ex}(\infty) = \sum_i \lambda_i E[v_i(\infty)^2]\) で与えられるので、
\[ J_{ex}(\infty) = \sum_{i=1}^{L} \lambda_i \cdot \frac{\mu J_{\min}}{2} = \frac{\mu J_{\min}}{2}\,\mathrm{tr}(\mathbf{R}) \tag{18} \]ミスアジャストメントは
\[ M = \frac{J_{ex}(\infty)}{J_{\min}} \approx \frac{\mu}{2}\,\mathrm{tr}(\mathbf{R}) \tag{19} \]となります。式(19)は、\(\mu\) を大きくすると収束は速くなる(式(14))一方で定常誤差も比例して増大するという、LMSの根本的なトレードオフを定量化しています。この近似は \(\mu\,\mathrm{tr}(\mathbf{R})/2 \ll 1\) (すなわち \(M\ll1\) )でのみ有効であり、\(M\) が \(1\) に近づくと線形化近似が崩れ、実際には発散に至ります。これは次の実行検証で確認します。
実行検証:収束境界・固有値拡散・ミスアジャストメント
収束条件の境界における発散
式(8)の \(0 < \mu < 2/\lambda_{\max}\) は \(E[\mathbf{w}(n)]\) の収束(平均収束)を保証する条件であり、実際の(確率的な)重みベクトルそのものの安定性を保証するものではありません。この違いを、\(L=8\) タップの白色雑音入力で実際に確認します。
import numpy as np
np.random.seed(0)
L = 8
N = 4000
x = np.random.randn(N)
# データから R を推定
X = np.array([x[i:i - L:-1] for i in range(L, N)])
R = (X.T @ X) / X.shape[0]
eigvals = np.linalg.eigvalsh(R)
lam_max = eigvals.max()
tr_R = np.trace(R)
w_true = np.array([0.5, -0.3, 0.2, 0.1, -0.05, 0.02, 0.0, 0.0])
v = 0.05 * np.random.randn(N)
d = np.convolve(x, w_true, mode='full')[:N] + v
def lms_run(x, d, L, mu, n_steps):
w = np.zeros(L)
e = np.zeros(n_steps)
for n in range(L, n_steps):
x_vec = x[n:n - L:-1]
y = w @ x_vec
e[n] = d[n] - y
w = w + mu * e[n] * x_vec
if not np.all(np.isfinite(w)) or np.linalg.norm(w) > 1e8:
return w, e, n, True
return w, e, n_steps, False
print(f"lambda_max={lam_max:.4f}, tr(R)={tr_R:.4f}")
print(f"mean-convergence bound 2/lambda_max = {2/lam_max:.4f}")
for mu in [0.02, 0.05, 0.10, 0.15, 0.20, 0.30, 0.50, 1.0, 2.0]:
w, e, stop_n, diverged = lms_run(x, d, L, mu, 3000)
tail = e[max(L, stop_n - 200):stop_n]
tail = tail[np.isfinite(tail)]
mean_e2 = np.mean(tail ** 2) if len(tail) else np.nan
print(f"mu={mu:.3f} (mu*tr(R)/2={mu*tr_R/2:.3f}): diverged={diverged}, "
f"stop_n={stop_n}, tail mean e^2={mean_e2:.3e}")
実行結果は次の通りでした(\(L=8\) 、白色雑音入力)。
lambda_max=0.9943, tr(R)=7.7061
mean-convergence bound 2/lambda_max = 2.0115
mu=0.020 (mu*tr(R)/2=0.077): diverged=False, stop_n=3000, tail mean e^2=1.958e-03
mu=0.050 (mu*tr(R)/2=0.193): diverged=False, stop_n=3000, tail mean e^2=2.252e-03
mu=0.100 (mu*tr(R)/2=0.385): diverged=False, stop_n=3000, tail mean e^2=3.028e-03
mu=0.150 (mu*tr(R)/2=0.578): diverged=False, stop_n=3000, tail mean e^2=5.892e-03
mu=0.200 (mu*tr(R)/2=0.771): diverged=False, stop_n=3000, tail mean e^2=1.465e-01
mu=0.300 (mu*tr(R)/2=1.156): diverged=True, stop_n=285, tail mean e^2=9.119e+13
mu=0.500 (mu*tr(R)/2=1.927): diverged=True, stop_n=95, tail mean e^2=1.674e+14
mu=1.000 (mu*tr(R)/2=3.853): diverged=True, stop_n=35, tail mean e^2=7.356e+12
mu=2.000 (mu*tr(R)/2=7.706): diverged=True, stop_n=27, tail mean e^2=1.479e+12
推定された固有値は \(\lambda_{\max}=0.9943\) で、式(8)の平均収束限界は \(2/\lambda_{\max}=2.0115\) です。しかし実際に発散が始まるのは \(\mu=0.20\) (安定、ただし尾部誤差が \(\mu=0.15\) 時点の約\(25\) 倍に劣化)と \(\mu=0.30\) の間であり、理論上の平均収束限界(\(\approx 2.01\) )よりはるかに小さい \(\mu\) ですでに不安定化しています。この遷移点は、式(19)のミスアジャストメント近似が \(M=\mu\,\mathrm{tr}(\mathbf{R})/2 \approx 1\) に達する付近(\(\mu \approx 2/\mathrm{tr}(\mathbf{R}) \approx 0.259\) )とよく一致します。これは、式(8)の \(\mu<2/\lambda_{\max}\) が保証するのはあくまで平均の収束であって、瞬時勾配の分散(勾配ノイズ)まで含めた実際の確率過程としての安定性(mean-square stability)はより厳しい条件を要求するためです。\(M\approx1\) 付近で式(19)の線形近似が破綻し、実際に発散に転じることが数値的に確認できました。実用上は \(\mu \ll 2/\mathrm{tr}(\mathbf{R})\) (\(M \ll 1\) )を目安にする方が、式(8)の限界値の半分を使うよりも安全です。
固有値拡散と収束速度の比較
次に、固有値拡散が収束速度に与える影響を、白色雑音(固有値拡散が小さい)と強く自己相関した AR(1) 信号(固有値拡散が大きい)の2種類の入力で比較します。
import numpy as np
np.random.seed(1)
L = 8
N = 6000
# --- 入力1: 白色雑音 ---
x_white = np.random.randn(N)
# --- 入力2: 強く自己相関した AR(1) 過程(rho=0.95、分散1に正規化) ---
rho = 0.95
raw = np.random.randn(N)
x_corr = np.zeros(N)
for n in range(1, N):
x_corr[n] = rho * x_corr[n - 1] + np.sqrt(1 - rho ** 2) * raw[n]
def autocorr_matrix(x, L, burn=500):
X = np.array([x[i:i - L:-1] for i in range(burn + L, len(x))])
return (X.T @ X) / X.shape[0]
R_white = autocorr_matrix(x_white, L)
R_corr = autocorr_matrix(x_corr, L)
ew_white = np.linalg.eigvalsh(R_white)
ew_corr = np.linalg.eigvalsh(R_corr)
print("白色雑音:", f"lambda_max={ew_white.max():.4f}, lambda_min={ew_white.min():.4f}, "
f"cond={ew_white.max()/ew_white.min():.3f}")
print("AR(1) rho=0.95:", f"lambda_max={ew_corr.max():.4f}, lambda_min={ew_corr.min():.4f}, "
f"cond={ew_corr.max()/ew_corr.min():.3f}")
w_true = np.array([0.5, -0.3, 0.2, 0.1, -0.05, 0.02, 0.0, 0.0])
v_white = 0.05 * np.random.randn(N)
v_corr = 0.05 * np.random.randn(N)
d_white = np.convolve(x_white, w_true, mode='full')[:N] + v_white
d_corr = np.convolve(x_corr, w_true, mode='full')[:N] + v_corr
def lms(x, d, L, mu, N):
w = np.zeros(L)
wnorm = np.zeros(N)
for n in range(L, N):
x_vec = x[n:n - L:-1]
e_n = d[n] - w @ x_vec
w = w + mu * e_n * x_vec
wnorm[n] = np.linalg.norm(w - w_true)
return w, wnorm
# 両者に共通の、より大きい lambda_max に対して安全な mu を使う
mu = 0.3 / max(ew_white.max(), ew_corr.max())
w_w, wn_w = lms(x_white, d_white, L, mu, N)
w_c, wn_c = lms(x_corr, d_corr, L, mu, N)
thresh = 0.05
n_white = np.where(wn_w[L:] < thresh)[0][0] + L
n_corr = np.where(wn_c[L:] < thresh)[0][0] + L
print(f"mu={mu:.4f}: ||w-w*||<{thresh} に到達する反復数: 白色={n_white}, 相関={n_corr}")
実行結果は次の通りでした。
白色雑音: lambda_max=1.0602, lambda_min=0.9537, cond=1.112
AR(1) rho=0.95: lambda_max=7.3407, lambda_min=0.0295, cond=249.244
mu=0.0409: ||w-w*||<0.05 に到達する反復数: 白色=115, 相関=1417
固有値拡散(条件数)は白色雑音で \(1.11\) 、AR(1)信号で \(249.2\) と大きく異なります。同一のステップサイズ(両者に共通して安全な \(\mu=0.0409\) )を用いたにもかかわらず、係数誤差 \(\|\mathbf{w}(n)-\mathbf{w}^\ast\|\) が閾値 \(0.05\) を下回るまでの反復数は、白色雑音で \(115\) サンプル、強く相関した入力で \(1417\) サンプルと、約12.3倍の差が生じました。これは式(14)で導出した通り、収束速度が最小固有値 \(\lambda_{\min}\) に支配される最遅モードによって決まるためです。
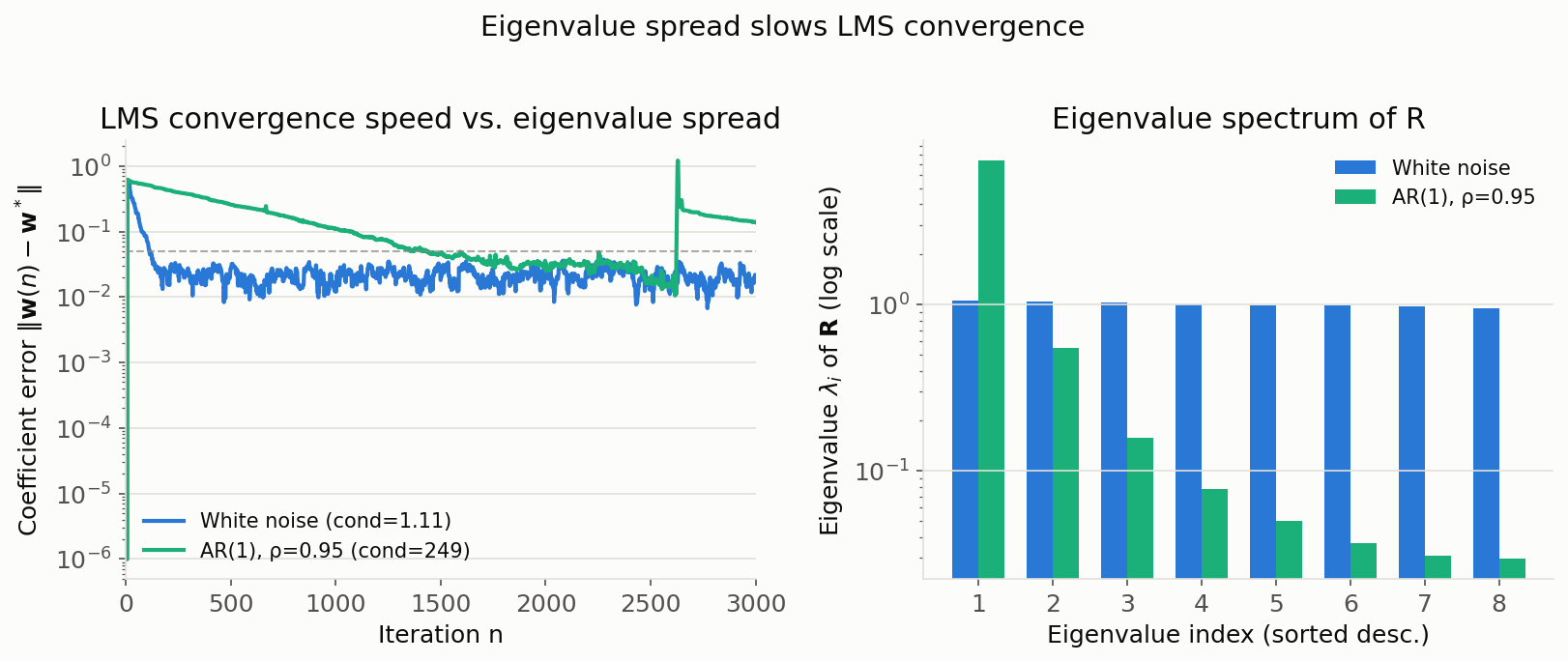
図から、白色雑音入力(条件数が\(1\) に近い)では係数誤差が指数的に速く減衰するのに対し、AR(1)入力(条件数249)では減衰が著しく緩やかであることが視覚的にも確認できます。また相関入力側の収束曲線には、途中で一時的に誤差が増大する区間(\(n\approx2600\) 付近)も見られ、固有値拡散が大きい入力では瞬時勾配のばらつきが大きくなることも示唆されます。
ミスアジャストメント近似の実測
最後に、式(19)の \(M\approx\mu\,\mathrm{tr}(\mathbf{R})/2\) が実測値とどの程度一致するか、\(L=8\) ・白色雑音入力・\(30\) 試行のモンテカルロ平均で検証します。
import numpy as np
np.random.seed(3)
L = 8
N = 20000
n_trials = 30
w_true = np.array([0.5, -0.3, 0.2, 0.1, -0.05, 0.02, 0.0, 0.0])
noise_var = 0.05 ** 2 # J_min(観測ノイズ分散)
for mu in [0.005, 0.01, 0.02, 0.04]:
excess_list = []
trR_list = []
for t in range(n_trials):
x = np.random.randn(N)
v = 0.05 * np.random.randn(N)
d = np.convolve(x, w_true, mode='full')[:N] + v
w = np.zeros(L)
e = np.zeros(N)
for n in range(L, N):
x_vec = x[n:n - L:-1]
e[n] = d[n] - w @ x_vec
w = w + mu * e[n] * x_vec
tail = e[int(N * 0.7):]
excess_list.append(np.mean(tail ** 2) - noise_var)
X = np.array([x[i:i - L:-1] for i in range(L, N)])
trR_list.append(np.trace((X.T @ X) / X.shape[0]))
M_measured = np.mean(excess_list) / noise_var
M_pred = mu * np.mean(trR_list) / 2
print(f"mu={mu:.3f}: 予測 M={M_pred:.4f}, 実測 M={M_measured:.4f}")
実行結果は次の通りでした(\(J_{\min}=0.0025\) )。
mu=0.005: 予測 M=0.0199, 実測 M=0.0189
mu=0.010: 予測 M=0.0401, 実測 M=0.0407
mu=0.020: 予測 M=0.0800, 実測 M=0.0864
mu=0.040: 予測 M=0.1600, 実測 M=0.1946
予測値と実測値は \(\mu=0.005\) 〜\(0.02\) の範囲でよく一致しており(誤差5〜8%程度)、式(19)の近似が小さいステップサイズで妥当であることが確認できました。\(\mu=0.04\) になると予測と実測の乖離がやや広がります(誤差約22%)。これは式(19)の導出で \(\mu\lambda_i\ll1\) を仮定して高次項を無視したためで、\(\mu\) が大きくなるほど無視した高次項の寄与が無視できなくなることを示しています。
NLMSアルゴリズム
正規化の動機
LMSの収束はステップサイズ \(\mu\) と入力パワー \(P_x\) の積に依存します(式(19)の \(\mathrm{tr}(\mathbf{R}) \approx L P_x\) を思い出してください)。入力レベルが大きく変動する環境(音声信号など)では、\(\mu\) を固定値にすると過小・過大の両方が起き、安定性が損なわれます。
NLMS(Normalized LMS)は、入力ベクトルのノルムでステップサイズを正規化することでこの問題を解決します。
\[ \mathbf{w}(n+1) = \mathbf{w}(n) + \frac{\tilde{\mu}}{\lVert \mathbf{x}(n) \rVert^2 + \varepsilon}\, e(n)\, \mathbf{x}(n) \tag{20} \]\(\tilde{\mu} \in (0, 2)\) が正規化されたステップサイズで、入力パワーに依存せず収束条件を満たします。\(\varepsilon\) は分母が小さくなりすぎないようにするための小さい正の定数です。
導出:最小擾乱原理
式(20)は天下り的に見えますが、最小擾乱原理(minimum disturbance principle)から導出できます。考え方は、「現在の重みを最小限だけ動かしつつ、更新後の重みで同じ入力ベクトル \(\mathbf{x}(n)\) に対する誤差(事後誤差、a posteriori error)\(\bar{e}(n) = d(n) - \mathbf{w}(n+1)^\top\mathbf{x}(n)\) をちょうど \(0\) にする」というものです。
更新則を \(\mathbf{w}(n+1)=\mathbf{w}(n)+\mu(n)\, e(n)\,\mathbf{x}(n)\) (勾配方向 \(e(n)\mathbf{x}(n)\) は固定し、スカラー \(\mu(n)\) のみ選ぶ)の形に限定してこの条件を課すと、
\[ \bar{e}(n) = d(n) - \bigl[\mathbf{w}(n) + \mu(n) e(n)\mathbf{x}(n)\bigr]^\top \mathbf{x}(n) = e(n)\bigl[1 - \mu(n)\lVert\mathbf{x}(n)\rVert^2\bigr] \tag{21} \]となり、\(\bar{e}(n)=0\) (\(e(n)\neq 0\) の場合)を解くと
\[ \mu(n) = \frac{1}{\lVert \mathbf{x}(n) \rVert^2} \tag{22} \]が唯一解として求まります。この \(\mu(n)\) をそのまま使うと現在の観測を毎回完全に打ち消す積極的な更新になるため、実用上はゼロ割回避の \(\varepsilon\) を加えたうえで式(22)を \(\tilde\mu\in(0,2)\) 倍にスケールし、式(20)を得ます。\(\tilde\mu=1\) がちょうど式(22)の厳密解(事後誤差ゼロ)に対応し、\(\tilde\mu<1\) は保守的(観測ノイズに頑健)、\(\tilde\mu\) を \(2\) に近づけるほど積極的な更新になります。これはLMSの安定域 \(\mu<2/\lambda_{\max}\) に対応する境界が、NLMSでは入力に依存しない \(\tilde\mu<2\) という単純な形になることを意味します。
この定式化から、NLMSがなぜ入力レベル変動に頑健かが明確になります。ステップサイズが \(1/\lVert\mathbf{x}(n)\rVert^2\) で自動的にスケールされるため、入力振幅が \(10\) 倍になれば実効ステップサイズは自動的に \(1/100\) になり、実効的な更新量は常に同じオーダーに保たれます。一方、固定 \(\mu\) のLMSでは入力振幅の変化がそのまま収束速度・安定性に影響します(次の実行検証で実測します)。
LMSとの比較
| 特性 | LMS | NLMS |
|---|---|---|
| 計算量 | \(O(L)\) | \(O(L)\) |
| ステップサイズ | \(\mu < 2/(L P_x)\) (入力依存) | \(\tilde{\mu} < 2\) (入力非依存) |
| 入力変動への頑健性 | 弱い | 強い |
| 実装の手間 | 最小 | LMS に正規化項を追加 |
実行検証:NLMSの入力振幅ロバスト性
式(22)の導出通り、NLMSは入力振幅の変化に対して自動的にステップサイズを調整します。これを実際に確認するため、同一のシステム同定タスクで入力信号の振幅だけを変えながら、固定ステップサイズのLMSと固定 \(\tilde\mu\) のNLMSを比較します。
import numpy as np
np.random.seed(2)
L = 8
N = 4000
w_true = np.array([0.5, -0.3, 0.2, 0.1, -0.05, 0.02, 0.0, 0.0])
def lms(x, d, L, mu, N):
w = np.zeros(L)
for n in range(L, N):
x_vec = x[n:n - L:-1]
e_n = d[n] - w @ x_vec
w = w + mu * e_n * x_vec
if not np.all(np.isfinite(w)):
return np.full(L, np.nan)
return w
def nlms(x, d, L, mu_tilde, N, eps=1e-6):
w = np.zeros(L)
for n in range(L, N):
x_vec = x[n:n - L:-1]
e_n = d[n] - w @ x_vec
norm = x_vec @ x_vec + eps
w = w + (mu_tilde / norm) * e_n * x_vec
return w
mu_lms = 0.01 # スケール1で調整済みの固定ステップサイズ
mu_tilde_nlms = 0.5 # 同じくスケール1で調整済み
for scale in [0.1, 0.5, 1.0, 3.0, 10.0]:
x = scale * np.random.randn(N)
v = 0.05 * scale * np.random.randn(N)
d = np.convolve(x, w_true, mode='full')[:N] + v
w_l = lms(x, d, L, mu_lms, N)
w_n = nlms(x, d, L, mu_tilde_nlms, N)
err_l = np.linalg.norm(w_l - w_true) if np.all(np.isfinite(w_l)) else np.inf
err_n = np.linalg.norm(w_n - w_true)
print(f"scale={scale:>5.1f}: LMS ||w-w*||={err_l:.4e}, NLMS ||w-w*||={err_n:.4e}")
実行結果は次の通りでした。
scale= 0.1: LMS ||w-w*||=4.1894e-01, NLMS ||w-w*||=1.6290e-02
scale= 0.5: LMS ||w-w*||=7.1713e-03, NLMS ||w-w*||=2.3375e-02
scale= 1.0: LMS ||w-w*||=1.1037e-02, NLMS ||w-w*||=3.0448e-02
scale= 3.0: LMS ||w-w*||=4.0226e-02, NLMS ||w-w*||=3.4492e-02
scale= 10.0: LMS ||w-w*||=inf, NLMS ||w-w*||=2.5266e-02
LMSの固定ステップサイズ \(\mu=0.01\)
はスケール\(1\)
付近でのみ良好に機能します。振幅が\(1/10\)
(scale=0.1)に縮小すると実効ステップサイズが不足し、\(N=4000\)
サンプル後でも係数誤差が\(0.419\)
と収束しきれていません。逆に振幅が\(10\)
倍(scale=10.0)になると式(9)の安定限界を超え、実際に発散(inf)しました。一方NLMSは、\(\tilde\mu=0.5\)
を固定したまま、振幅が\(100\)
倍(\(0.1\to10\)
)変化する全区間で係数誤差が\(0.016\)
〜\(0.034\)
の狭い範囲に収まっており、式(20)の正規化項 \(1/\lVert\mathbf{x}(n)\rVert^2\)
が入力パワーの変動を自動的に吸収していることが実測できました。
Python実装
システム同定の例
未知のFIRシステム \(\mathbf{w}^\ast\) を、白色雑音 \(x(n)\) を入力として LMS / NLMS で同定します。誤差 \(e(n)\) の二乗を学習曲線としてプロットします。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
# --- 真のシステム(同定対象) ---
L = 16
w_true = np.array([0.5, -0.3, 0.2, 0.1, -0.05, 0.02,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0])
# --- 入力・観測信号 ---
N = 5000
x = np.random.randn(N)
v = 0.05 * np.random.randn(N) # 観測ノイズ
d = np.convolve(x, w_true, mode='full')[:N] + v
def lms(x, d, L, mu):
"""標準LMSアルゴリズム"""
N = len(x)
w = np.zeros(L)
e = np.zeros(N)
for n in range(L, N):
x_vec = x[n:n - L:-1] if n - L >= 0 else x[n::-1]
y = w @ x_vec
e[n] = d[n] - y
w = w + mu * e[n] * x_vec
return w, e
def nlms(x, d, L, mu_tilde, eps=1e-6):
"""正規化LMSアルゴリズム"""
N = len(x)
w = np.zeros(L)
e = np.zeros(N)
for n in range(L, N):
x_vec = x[n:n - L:-1]
y = w @ x_vec
e[n] = d[n] - y
norm = x_vec @ x_vec + eps
w = w + (mu_tilde / norm) * e[n] * x_vec
return w, e
# --- 実行 ---
mu_lms = 0.01
mu_nlms = 0.5
w_lms, e_lms = lms(x, d, L, mu_lms)
w_nlms, e_nlms = nlms(x, d, L, mu_nlms)
# --- 学習曲線(瞬時誤差の二乗を移動平均) ---
def smooth(v, win=50):
kernel = np.ones(win) / win
return np.convolve(v ** 2, kernel, mode='same')
plt.figure(figsize=(10, 5))
plt.semilogy(smooth(e_lms), label=f'LMS (μ={mu_lms})')
plt.semilogy(smooth(e_nlms), label=f'NLMS (μ̃={mu_nlms})')
plt.xlabel('Iteration n')
plt.ylabel('Mean Squared Error')
plt.title('Learning Curves: LMS vs NLMS')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"LMS final coeff error: {np.linalg.norm(w_lms - w_true):.4f}")
print(f"NLMS final coeff error: {np.linalg.norm(w_nlms - w_true):.4f}")
学習曲線(縦軸が対数)を見ると、最初は誤差が指数的に減少し、やがて定常誤差レベルで水平になります。\(\mu\) (または \(\tilde{\mu}\) )を大きくすると初期収束は速くなりますが、定常誤差レベルも上昇する典型的なトレードオフが観察できます。
ステップサイズの感度解析
plt.figure(figsize=(10, 5))
for mu in [0.005, 0.02, 0.05, 0.1]:
_, e = lms(x, d, L, mu)
plt.semilogy(smooth(e), label=f'μ={mu}', alpha=0.8)
plt.xlabel('Iteration n')
plt.ylabel('Mean Squared Error')
plt.title('LMS: Sensitivity to Step Size μ')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
\(\mu\) が小さすぎると収束が極めて遅く、\(\mu\) が上限近くでは初期から振動的になります。実用上は (8) 式の半分以下を目安に選ぶと安定です。
ウィーナーフィルタとの関係
LMSは、ウィーナー解 \(\mathbf{w}^\ast = \mathbf{R}^{-1}\mathbf{p}\) (\(\mathbf{p} = E[d(n)\mathbf{x}(n)]\) )に逐次的に収束します。
\[ E\bigl[\mathbf{w}(n)\bigr] \xrightarrow{n \to \infty} \mathbf{w}^\ast \tag{23} \]これは式(13)-(14)で厳密に示した通りです。ただし、瞬時勾配を使うため有限の過剰平均二乗誤差(excess MSE、式(19)のミスアジャストメント \(M=\mu\,\mathrm{tr}(\mathbf{R})/2\) )が残ります。RLS(再帰的最小二乗)はこれを高速化する代替手法です。
用途別ガイド
| 用途 | 推奨 | 理由 |
|---|---|---|
| 入力レベルが安定 | LMS | 実装最小、計算量も最少 |
| 音声・通信信号など変動大 | NLMS | 入力パワー変動に頑健 |
| 速い収束が必須 | RLS | 二次収束、ただし \(O(L^2)\) |
| 組み込み・低リソース | LMS / NLMS | \(O(L)\) で十分 |
近年の研究動向:深層学習との融合
LMS/NLMS/RLSといった伝統的な適応フィルタは、今なおエコーキャンセレーションやノイズキャンセレーションの基盤技術として使われ続けていますが、2023年前後からは、深層ニューラルネットワークと組み合わせるハイブリッド構成が主流になりつつあります。典型的な設計は、まず線形適応フィルタ(NLMSやKalmanフィルタベースの手法)で入力信号中の線形なエコー成分・定常雑音成分を除去し、その残差信号をディープニューラルネットワーク(DNN)に通して非線形な歪みや残留エコー・非定常雑音をさらに抑圧する、という二段構成です。Microsoftが主催する Deep Noise Suppression (DNS) Challenge やエコーキャンセレーション関連のチャレンジは、こうしたハイブリッド手法の発展を後押ししてきました。
この構成が支持される理由は、適応フィルタ側が持つ「軽量(\(O(L)\) )」「入力統計が変化しても理論的な収束条件・定常誤差が明示できる」という性質と、DNN側が持つ「非線形・非定常な残差を柔軟にモデル化できる」という性質が補完的だからです。純粋なend-to-endニューラルモデルだけで置き換える動きもありますが、計算コストや未知環境への汎化性、遅延制約の観点から、適応フィルタを完全に代替するには至っていません。この分野は変化が速いため、具体的な手法名や性能数値については各年のチャレンジの公式論文・リーダーボードなど一次情報を参照することをお勧めします。
関連記事
- 適応フィルタの基礎理論とデジタル信号処理への応用 - 本記事のLMSアルゴリズムの理論的な出発点。Wiener-Hopf方程式をMMSE問題として導出し、LMSがWiener解に収束することを数値検証しています。
- RLS(逐次最小二乗法)アルゴリズムの理論とPython実装 - 本記事末尾で触れたRLSを行列反転補題から導出し、LMSとの収束速度比較・カルマンフィルタとの等価性を実証した発展編です。
- ウィーナーフィルタ:最適線形フィルタの理論とPython実装 - LMSが逐次近似する最適解そのもの。バッチ処理(周波数領域)と適応処理(時間領域)の違いを比較できます。
- 適応フィルタ(LMS/RLS)の理論とPython実装 - LMSとRLSの比較、ノイズキャンセレーション応用を含む包括解説です。
- 自己相関関数の理論とPython実装 - LMSの収束速度を支配する入力相関行列 \(\mathbf{R}\) の理解に直結します。
- FFTの基礎:高速フーリエ変換の理論と実装 - 周波数領域版の適応アルゴリズム(FDAF)の前提となるFFTの解説です。
- カルマンフィルタの理論とPython実装 - 適応フィルタとは別系統の逐次推定手法。RLSはカルマンフィルタと数学的に等価です。
- 移動平均フィルタの種類と比較:SMA・WMA・EMAのPython実装 - 固定係数フィルタとの設計思想の違いを把握できます。
- FIRフィルタとIIRフィルタの比較 - LMS/NLMSの多くがFIR構造を採用するため、IIRとの特性差はステップサイズ・収束性の理解に直結します。
参考文献
- Haykin, S. (2014). Adaptive Filter Theory (5th ed.). Pearson. Chapters 5-6.
- Widrow, B., & Stearns, S. D. (1985). Adaptive Signal Processing. Prentice Hall.
- Sayed, A. H. (2008). Adaptive Filters. Wiley-IEEE Press.