ガウス過程とは
ガウス過程(Gaussian Process, GP) は、関数そのものを確率変数として扱う確率モデルです。直感的には、有限次元の多変量正規分布を「無限次元」へ拡張したものと見なせます。
通常の正規分布が「ベクトル \(\mathbf{y} \in \mathbb{R}^n\) の分布」を定めるのに対し、GP は「関数 \(f: \mathcal{X} \rightarrow \mathbb{R}\) の分布」を定めます。GP の定義は次の通りです:任意の有限個の入力点 \(\{\mathbf{x}_1, \ldots, \mathbf{x}_n\}\) に対して、対応する関数値ベクトル \([f(\mathbf{x}_1), \ldots, f(\mathbf{x}_n)]^T\) が多変量正規分布に従うとき、\(f\) はガウス過程に従うといいます。
GP は平均関数 \(m(\mathbf{x})\) とカーネル関数(共分散関数)\(k(\mathbf{x}, \mathbf{x}')\) の2つで完全に特徴付けられます:
\[ f(\mathbf{x}) \sim \mathcal{GP}(m(\mathbf{x}), k(\mathbf{x}, \mathbf{x}')) \tag{1} \]実用上は \(m(\mathbf{x}) = 0\) とすることが多く、関数の形状はカーネルによって決まります。
カーネル関数(事前分布の設計)
カーネル関数 \(k(\mathbf{x}, \mathbf{x}')\) は2点間の関数値の共分散を与え、関数の滑らかさ・周期性などの事前知識を埋め込みます。
RBF(二乗指数)カーネル
最も広く使われるのが RBF カーネル(または二乗指数カーネル)です:
\[ k_{\text{RBF}}(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \exp\left(-\frac{\|\mathbf{x} - \mathbf{x}'\|^2}{2 \ell^2}\right) \tag{2} \]- \(\sigma_f^2\) : 出力の分散(関数の振幅)
- \(\ell\) : length scale。距離 \(\ell\) だけ離れた点間の相関がどの程度残るかを決める
\(\ell\) が大きいほど関数は滑らかになり、小さいほど局所的に激しく変動します。RBF カーネルから生成される関数は無限回微分可能です。
Matern カーネル
実問題ではしばしば「滑らかすぎ」が問題になります。Matern カーネルは滑らかさパラメータ \(\nu\) で微分可能性を制御できます:
\[ k_{\text{Matern}}(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \frac{2^{1-\nu}}{\Gamma(\nu)} \left(\frac{\sqrt{2\nu}\, \|\mathbf{x} - \mathbf{x}'\|}{\ell}\right)^{\nu} K_{\nu}\left(\frac{\sqrt{2\nu}\, \|\mathbf{x} - \mathbf{x}'\|}{\ell}\right) \tag{3} \]ここで \(K_{\nu}\) は第二種変形ベッセル関数です。\(\nu = 1/2\) で指数カーネル、\(\nu \to \infty\) で RBF に収束します。実用では \(\nu = 3/2, 5/2\) がよく用いられます。
観測データへの条件付け(事後分布)
GP の真価は、観測データを与えると 解析的に閉形式で事後分布が得られる 点にあります。
\(n\) 個の観測 \(\mathcal{D} = \{(\mathbf{x}_i, y_i)\}_{i=1}^n\) にノイズを仮定します:
\[ y_i = f(\mathbf{x}_i) + \varepsilon_i, \quad \varepsilon_i \sim \mathcal{N}(0, \sigma_n^2) \tag{4} \]新しい入力 \(\mathbf{x}_*\) における関数値 \(f_*\) と観測ベクトル \(\mathbf{y}\) の同時分布は次式で書けます:
\[ \begin{bmatrix} \mathbf{y} \\ f_* \end{bmatrix} \sim \mathcal{N}\left(\mathbf{0}, \begin{bmatrix} \mathbf{K} + \sigma_n^2 \mathbf{I} & \mathbf{k}_* \\ \mathbf{k}_*^T & k(\mathbf{x}_*, \mathbf{x}_*) \end{bmatrix} \right) \tag{5} \]ここで \(K_{ij} = k(\mathbf{x}_i, \mathbf{x}_j)\) 、\(\mathbf{k}_* = [k(\mathbf{x}_1, \mathbf{x}_*), \ldots, k(\mathbf{x}_n, \mathbf{x}_*)]^T\) です。
事後分布の導出:シューア補行列による証明
式(6)・式(7)は「多変量正規分布の条件付けの公式」として天下り的に与えられることが多いですが、ここでは式(5)の同時分布から出発し、**シューア補行列(Schur complement)**を用いてブロック行列の逆行列を構成することで、閉形式の事後分布を実際に導出します。
記法を簡略化するため、
\[ A := \mathbf{K} + \sigma_n^2 \mathbf{I} \ (n \times n), \quad \mathbf{b} := \mathbf{k}_* \ (n \times 1), \quad c := k(\mathbf{x}_*, \mathbf{x}_*) \ (\text{スカラー}) \]とおくと、式(5)の共分散行列は \(\Sigma = \begin{bmatrix} A & \mathbf{b} \\ \mathbf{b}^T & c \end{bmatrix}\) と書けます。まず、次のブロック LDL 分解が成り立つことを直接の乗算で確認します:
\[ \Sigma = \begin{bmatrix} I & 0 \\ \mathbf{b}^T A^{-1} & 1 \end{bmatrix} \begin{bmatrix} A & 0 \\ 0 & s \end{bmatrix} \begin{bmatrix} I & A^{-1}\mathbf{b} \\ 0 & 1 \end{bmatrix}, \qquad s := c - \mathbf{b}^T A^{-1} \mathbf{b} \](右辺を展開すると \((2,2)\) 成分が \(\mathbf{b}^T A^{-1}\mathbf{b} + s = c\) となり、確かに \(\Sigma\) に一致します。)ここで現れるスカラー \(s\) が \(A\) に関する \(\Sigma\) のシューア補行列です。各因子は下三角・対角・上三角のブロック行列なので個別に逆行列を計算でき、
\[ \Sigma^{-1} = \begin{bmatrix} A^{-1} + A^{-1}\mathbf{b}\, s^{-1} \mathbf{b}^T A^{-1} & -A^{-1}\mathbf{b}\, s^{-1} \\ -s^{-1}\mathbf{b}^T A^{-1} & s^{-1} \end{bmatrix} \]が得られます。同時分布 \(p(\mathbf{y}, f_*) \propto \exp\left(-\frac{1}{2}\begin{bmatrix}\mathbf{y}\\f_*\end{bmatrix}^T \Sigma^{-1} \begin{bmatrix}\mathbf{y}\\f_*\end{bmatrix}\right)\) の指数部分にこの \(\Sigma^{-1}\) を代入し、\(m := \mathbf{b}^T A^{-1}\mathbf{y}\) (スカラー)とおいて整理すると、
\[ \begin{bmatrix}\mathbf{y}\\f_*\end{bmatrix}^T \Sigma^{-1} \begin{bmatrix}\mathbf{y}\\f_*\end{bmatrix} = \mathbf{y}^T A^{-1}\mathbf{y} + \frac{(f_* - m)^2}{s} \]という平方完成が成り立ちます(\(f_*\) を含む項だけを取り出すと \(f_*^2 s^{-1} - 2 f_* s^{-1} m + m^2 s^{-1} = (f_*-m)^2/s\) になることから確認できます)。\(\mathbf{y}\) に依存する項 \(\mathbf{y}^T A^{-1}\mathbf{y}\) は \(f_*\) を含まない定数なので、\(\mathbf{y}\) を所与としたときの \(f_*\) の条件付き分布は
\[ f_* \mid \mathbf{y} \sim \mathcal{N}(m,\, s) = \mathcal{N}\big(\mathbf{b}^T A^{-1}\mathbf{y},\ c - \mathbf{b}^T A^{-1}\mathbf{b}\big) \]に従うことがわかります。\(A, \mathbf{b}, c\) を元の記号に戻せば、これはまさに式(6)・式(7)そのものです:
\[ \mu_*(\mathbf{x}_*) = \mathbf{k}_*^T (\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1} \mathbf{y} \tag{6} \] \[ \sigma_*^2(\mathbf{x}_*) = k(\mathbf{x}_*, \mathbf{x}_*) - \mathbf{k}_*^T (\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1} \mathbf{k}_* \tag{7} \]「条件付けの公式」を無条件に信じるのではなく、ブロック行列の逆行列(シューア補行列)と平方完成という2つの初等的な道具だけから式(6)・式(7)が導けることが確認できました。この導出は後述のコレスキー分解の議論とも直結します——\(A^{-1}\mathbf{y}\) や \(A^{-1}\mathbf{b}\) という「\(A\) の逆行列と何かの積」の形が繰り返し現れるため、\(A\) を明示的に逆行列にせず、三角行列に対する連立方程式の求解に置き換えることが数値計算上重要になります。
式(6)が予測平均、式(7)が予測分散です。データが密な領域では \(\sigma_*^2\) が小さくなり、データから離れた領域では \(\sigma_f^2\) に近づく 「データに引き寄せられる挙動」 が自動的に得られます。これがニューラルネットなどの点推定モデルにはない、GP の本質的な強みです。
RKHSとRepresenter定理:なぜ有限個の点の和で書けるのか
式(6)には奇妙な点があります。GP は「無限次元の関数空間」上の分布のはずなのに、事後平均 \(\mu_*(\mathbf{x}_*)\) は \(n\) 個の訓練点に対応するカーネル値 \(k(\mathbf{x}_i, \mathbf{x}_*)\) の有限次元の線形結合
\[ \mu_*(\mathbf{x}_*) = \sum_{i=1}^n \alpha_i\, k(\mathbf{x}_i, \mathbf{x}_*), \qquad \boldsymbol{\alpha} = (\mathbf{K}+\sigma_n^2\mathbf{I})^{-1}\mathbf{y} \]として書けています。なぜ無限次元の探索が有限次元の計算に落ちるのでしょうか。この問いに答えるのが再生核ヒルベルト空間(Reproducing Kernel Hilbert Space, RKHS)とRepresenter定理です。
RKHS:カーネルが定める関数空間
対称かつ半正定値なカーネル \(k(\mathbf{x}, \mathbf{x}')\) が与えられると、Moore–Aronszajnの定理(Aronszajn, 1950)により、\(k\) を再生核として持つ関数空間 \(\mathcal{H}_k\) (RKHS)がただ一つ存在します。\(\mathcal{H}_k\) は次の2条件で特徴づけられます。
- 任意の \(\mathbf{x}\) に対して \(k(\mathbf{x}, \cdot) \in \mathcal{H}_k\) (カーネルを一方の引数に固定した関数が空間の要素になっている)
- 再生性:任意の \(f \in \mathcal{H}_k\) と任意の \(\mathbf{x}\) に対して \(f(\mathbf{x}) = \langle f,\, k(\mathbf{x}, \cdot) \rangle_{\mathcal{H}_k}\) (関数の点評価が内積で「再現」される)
RBF カーネルの \(\mathcal{H}_k\) は無限次元です(式(2)を無限次多項式カーネルの重み付き和に展開できることに対応します)。したがって GP の事前分布 \(f \sim \mathcal{GP}(0, k)\) が探索する関数の集合も、直感的には無限次元の広がりを持ちます。
Representer定理:正則化問題の解は必ず有限次元に落ちる
Representer定理(Kimeldorf & Wahba, 1970; 一般化版は Schölkopf, Herbrich & Smola, 2001)は次を主張します。\(n\) 個の訓練点 \(\{(\mathbf{x}_i, y_i)\}_{i=1}^n\) に対して、損失関数 \(L\) と単調非減少な正則化項 \(\Omega\) を用いた
\[ f^* = \arg\min_{f \in \mathcal{H}_k}\ L\big(f(\mathbf{x}_1), \ldots, f(\mathbf{x}_n),\, y_1, \ldots, y_n\big) + \Omega(\|f\|_{\mathcal{H}_k}) \]という最適化問題の解 \(f^*\) は、\(\mathcal{H}_k\) がどれだけ高次元(無限次元)であっても、必ず
\[ f^*(\mathbf{x}) = \sum_{i=1}^n \alpha_i\, k(\mathbf{x}_i, \mathbf{x}) \]という有限次元の形で書けます。証明は驚くほど短く済みます。任意の \(f \in \mathcal{H}_k\) を、訓練点の張る部分空間 \(V = \mathrm{span}\{k(\mathbf{x}_1,\cdot), \ldots, k(\mathbf{x}_n,\cdot)\}\) への正射影 \(f_\parallel \in V\) と、その直交補空間の成分 \(f_\perp \perp V\) に分解します:\(f = f_\parallel + f_\perp\) 。再生性より \(f(\mathbf{x}_i) = \langle f, k(\mathbf{x}_i,\cdot)\rangle = \langle f_\parallel, k(\mathbf{x}_i,\cdot)\rangle + \langle f_\perp, k(\mathbf{x}_i,\cdot)\rangle = f_\parallel(\mathbf{x}_i)\) (\(k(\mathbf{x}_i,\cdot) \in V\) なので \(f_\perp\) との内積はゼロ)となり、損失項 \(L\) は \(f_\perp\) に一切依存しません。一方ノルムはピタゴラスの定理より \(\|f\|_{\mathcal{H}_k}^2 = \|f_\parallel\|^2 + \|f_\perp\|^2 \geq \|f_\parallel\|^2\) で、等号は \(f_\perp = 0\) のときに限ります。\(\Omega\) は単調非減少なので、損失を変えずに正則化項だけを厳密に下げられる \(f_\perp = 0\) が最適解でなければなりません。ゆえに \(f^* = f_\parallel \in V\) 、すなわち訓練点のカーネル関数の線形結合です。
GP事後平均との対応
GP 回帰の負の対数事後(式4のノイズモデルのもとで \(f\) を \(\mathcal{H}_k\) 上の関数として最適化する問題)は
\[ J(f) = \frac{1}{2\sigma_n^2}\sum_{i=1}^n \big(y_i - f(\mathbf{x}_i)\big)^2 + \frac{1}{2}\|f\|_{\mathcal{H}_k}^2 \]という形に書け、これはまさに Representer 定理の枠組み(\(L\) が二乗誤差、\(\Omega\) が恒等関数)に一致します。したがって最小化解は \(f^*(\mathbf{x}) = \sum_i \alpha_i k(\mathbf{x}_i, \mathbf{x})\) の形を取り、\(f^*\) を訓練点で評価した値 \(\mathbf{f} = \mathbf{K}\boldsymbol{\alpha}\) を \(J\) に代入して \(\boldsymbol{\alpha}\) について最小化すると \(\boldsymbol{\alpha} = (\mathbf{K}+\sigma_n^2\mathbf{I})^{-1}\mathbf{y}\) が得られます。これは式(6)の \(\boldsymbol{\alpha}\) と完全に一致します。
つまり、GP事後平均は「カーネルのRKHSノルムで正則化されたリッジ回帰(kernel ridge regression)」の解と数学的に同一であり、GP の確率的な導出(シューア補行列による事後分布の計算)と、RKHS の関数解析的な導出(Representer定理による正則化問題の求解)は、同じ式(6)へ2つの独立な経路から到達する双対的な関係にあります(Kimeldorf & Wahba, 1970 がこの対応を初めて示しました)。無限次元の関数空間で「サポートベクター」ならぬ「サポート点」が訓練データの \(n\) 点に限られる理由は、確率論の言葉ではなく、この直交射影の議論にあります。
周辺尤度とハイパーパラメータ
カーネルのハイパーパラメータ \(\boldsymbol{\theta} = (\sigma_f^2, \ell, \sigma_n^2)\) は、対数周辺尤度(log marginal likelihood) の最大化により学習できます。式(4)より観測ベクトル \(\mathbf{y}\) 自体も平均 \(\mathbf{0}\) の多変量正規分布 \(\mathbf{y} \sim \mathcal{N}(\mathbf{0}, \mathbf{K}+\sigma_n^2\mathbf{I})\) に従うので(式(5)の同時分布の周辺分布として、あるいは式(4)を直接見ても、\(\mathbf{y}\) 自身の共分散は \(\mathrm{Cov}(y_i,y_j) = k(\mathbf{x}_i,\mathbf{x}_j) + \sigma_n^2\delta_{ij}\) )、その対数尤度は多変量正規分布の密度関数
\[ p(\mathbf{y} \mid \mathbf{X}, \boldsymbol{\theta}) = \frac{1}{(2\pi)^{n/2} |\mathbf{K}+\sigma_n^2\mathbf{I}|^{1/2}} \exp\!\left(-\frac{1}{2}\mathbf{y}^T (\mathbf{K}+\sigma_n^2\mathbf{I})^{-1} \mathbf{y}\right) \]の対数を取るだけで直ちに導けます:
\[ \log p(\mathbf{y} \mid \mathbf{X}, \boldsymbol{\theta}) = -\frac{1}{2}\mathbf{y}^T (\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1} \mathbf{y} - \frac{1}{2} \log |\mathbf{K} + \sigma_n^2 \mathbf{I}| - \frac{n}{2} \log 2\pi \tag{8} \]第1項がデータ適合度、第2項が モデル複雑度のペナルティ(オッカムの剃刀)として働きます。この2項の綱引きは直感的に理解できます。\(\ell\) を小さくすると \(\mathbf{K}\) は単位行列に近づき(各点が独立)、\(\mathbf{y}\) をほぼそのまま再現できるため第1項は改善しますが、\(\mathbf{K}\) の固有値が均等に分布して行列式 \(|\mathbf{K}+\sigma_n^2\mathbf{I}|\) が相対的に大きくなり、\(-\frac12\log|\cdot|\) の罰則が強く効きます。逆に \(\ell\) を大きくすると点同士の相関が上がって \(\mathbf{K}\) はほぼ階数1の行列に退化し、行列式は極端に小さくなって罰則はほぼ消えますが、平坦な関数しか表現できず第1項(データ適合度)が悪化します。交差検証を一切使わずに、この2項の釣り合いだけでモデルの複雑さが自動調整されるのが GP がベイズ的に過適合を抑制する仕組みです。
Python実装:1次元 GP 回帰
NumPy と SciPy だけで GP 回帰をスクラッチ実装します。Cholesky 分解で逆行列計算を安定化します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import cho_factor, cho_solve
class GaussianProcessRegressor:
def __init__(self, length_scale=1.0, signal_var=1.0, noise_var=1e-4):
self.l = length_scale
self.sf2 = signal_var
self.sn2 = noise_var
def rbf(self, X1, X2):
"""式(2): RBFカーネル"""
d2 = (np.sum(X1**2, axis=1, keepdims=True)
- 2.0 * X1 @ X2.T
+ np.sum(X2**2, axis=1))
return self.sf2 * np.exp(-0.5 * d2 / self.l**2)
def fit(self, X, y):
self.X_train = X.copy()
self.y_train = y.copy()
K = self.rbf(X, X) + self.sn2 * np.eye(len(X))
# Cholesky で安定化
self.L_, self.lower_ = cho_factor(K, lower=True)
self.alpha_ = cho_solve((self.L_, self.lower_), y)
def predict(self, X_new):
"""式(6), (7): 事後予測平均と分散"""
k_star = self.rbf(self.X_train, X_new)
mu = k_star.T @ self.alpha_
v = cho_solve((self.L_, self.lower_), k_star)
var = self.sf2 - np.sum(k_star * v, axis=0)
var = np.maximum(var, 1e-10)
return mu, var
def log_marginal_likelihood(self):
"""式(8): 対数周辺尤度"""
n = len(self.y_train)
log_det = 2.0 * np.sum(np.log(np.diag(self.L_)))
return (-0.5 * self.y_train @ self.alpha_
- 0.5 * log_det
- 0.5 * n * np.log(2 * np.pi))
サンプリングと予測
ノイズあり観測から事後分布を構築し、95%信頼区間を可視化します。
# 真の関数(ノイズなし)
def true_f(x):
return np.sin(2.0 * x) + 0.3 * x
# 観測データ
np.random.seed(0)
X_train = np.array([[-3.0], [-2.0], [-0.5], [1.0], [2.5], [3.5]])
y_train = true_f(X_train.ravel()) + 0.1 * np.random.randn(len(X_train))
gp = GaussianProcessRegressor(length_scale=1.0, signal_var=1.0, noise_var=0.01)
gp.fit(X_train, y_train)
X_test = np.linspace(-5.0, 5.0, 300).reshape(-1, 1)
mu, var = gp.predict(X_test)
sigma = np.sqrt(var)
plt.figure(figsize=(10, 5))
plt.plot(X_test, true_f(X_test.ravel()), "k--", label="True function")
plt.plot(X_test, mu, "b-", label="GP mean")
plt.fill_between(X_test.ravel(), mu - 1.96 * sigma, mu + 1.96 * sigma,
alpha=0.2, color="blue", label="95% CI")
plt.scatter(X_train, y_train, c="red", s=60, zorder=5, label="Observations")
plt.xlabel("x"); plt.ylabel("f(x)")
plt.title("Gaussian Process Regression (RBF kernel)")
plt.legend(); plt.grid(True); plt.tight_layout()
plt.savefig("gp_regression.png", dpi=150)
print(f"log marginal likelihood: {gp.log_marginal_likelihood():.4f}")
観測点付近では信頼区間が狭まり、データから離れるほど不確実性(青い帯)が広がる挙動が確認できます。これは式(7)の第1項 \(k(\mathbf{x}_*, \mathbf{x}_*) = \sigma_f^2\) が支配的になるためです。
検証:ノイズなし観測は正確に補間されるか
RKHSの節で見た通り、GP事後平均は訓練データを通る関数を返すはずです。ノイズ分散 \(\sigma_n^2\) をほぼゼロ(ジッター程度の \(10^{-10}\) )にして、訓練点そのものを予測点として与え、実際に補間が成り立つか実行検証しました。
# 検証:ノイズなし観測は訓練点を正確に補間するか
y_train_clean = true_f(X_train.ravel()) # ノイズを加えない
gp_clean = GaussianProcessRegressor(length_scale=1.0, signal_var=1.0, noise_var=1e-10)
gp_clean.fit(X_train, y_train_clean)
mu_train, var_train = gp_clean.predict(X_train) # 訓練点そのもので予測
print("y_train =", np.round(y_train_clean, 6))
print("mu (at train)=", np.round(mu_train, 6))
print("max|mu - y_train| =", np.max(np.abs(mu_train - y_train_clean)))
print("max posterior var at train points =", np.max(var_train))
実行結果:
y_train = [-0.620585 0.156802 -0.991471 1.209297 -0.208924 1.706987]
mu (at train)= [-0.620585 0.156802 -0.991471 1.209297 -0.208924 1.706987]
max|mu - y_train| = 3.5771496875725006e-10
max posterior var at train points = 1.0000011929633956e-10
事後平均は訓練データの値を小数点以下9桁まで正確に再現し、事後分散も設定したジッター(\(10^{-10}\) )とほぼ同じ大きさまで潰れています。これは式(6)・式(7)から理論的にも保証される性質です——\(\mathbf{x}_* = \mathbf{x}_i\) (訓練点そのもの)のとき \(\mathbf{k}_* \) は \(\mathbf{K}\) の第 \(i\) 列と一致するため、\(\sigma_n^2 \to 0\) の極限で \(\mu_*(\mathbf{x}_i) \to y_i\) 、\(\sigma_*^2(\mathbf{x}_i) \to 0\) となることが式(6)・(7)に \(\mathbf{x}_*=\mathbf{x}_i\) を代入すれば直接確認できます。GP が単なる「なめらかな近似」ではなく、ノイズがなければデータを厳密に補間する非パラメトリック回帰であることが実験的に裏付けられました。
数値安定性:コレスキー分解とジッター
式(6)・式(7)・式(8)にはいずれも \((\mathbf{K}+\sigma_n^2\mathbf{I})^{-1}\)
という逆行列が登場します。実装上、この逆行列を np.linalg.inv で明示的に計算するのは避けるべきです。理由は速度と数値精度の両面にあります。
なぜ明示的な逆行列を避けるのか
\(\mathbf{K}+\sigma_n^2\mathbf{I}\) は対称正定値行列です。対称正定値行列に対しては、一般の LU 分解ではなくコレスキー分解 \(\mathbf{K}+\sigma_n^2\mathbf{I} = \mathbf{L}\mathbf{L}^T\) (\(\mathbf{L}\) は下三角行列)が使えます。コレスキー分解を使うと、以下の3つの利点が同時に得られます。
- 計算量が半分:対称性を利用するため、一般の LU 分解(\(\frac{2}{3}n^3\) flops)の約半分(\(\frac{1}{3}n^3\) flops)で済みます。
- 逆行列を作らずに済む:予測に必要なのは \((\mathbf{K}+\sigma_n^2\mathbf{I})^{-1}\mathbf{y}\) や \((\mathbf{K}+\sigma_n^2\mathbf{I})^{-1}\mathbf{k}_*\) という「逆行列と何かの積」だけです。\(\mathbf{L}\mathbf{L}^T \boldsymbol{\alpha} = \mathbf{y}\) を前進代入・後退代入の2回の三角行列の求解で解けば、\(n\times n\) の逆行列を陽に構成せずに済みます。逆行列を明示的に計算する方が求めたい積を直接解くより演算量が多く、丸め誤差も余分に蓄積します。
- 1回の分解を使い回せる:\(\mathbf{L}\) さえ手元にあれば、予測平均(式6)・予測分散(式7)・対数周辺尤度(式8、\(\log|\mathbf{K}+\sigma_n^2\mathbf{I}| = 2\sum_i \log L_{ii}\) として \(O(n)\) で計算可能)のすべてを同じ \(\mathbf{L}\) から求められます。ハイパーパラメータ最適化では対数周辺尤度とその勾配を反復評価するため、\(O(n^3)\) の分解を毎回1度で済ませられることは計算コスト全体に直結します。
ジッター(jitter)の必要性
理論上、カーネル行列 \(\mathbf{K}\) は半正定値です。しかし浮動小数点演算では、訓練点同士が近い、あるいは length scale \(\ell\) が大きく点間の相関がほぼ1になる場合に、丸め誤差によって \(\mathbf{K}\) の最小固有値が実際には負の微小値になってしまうことがあります。コレスキー分解は各ステップで正の数の平方根を取るため、行列が(数値的に)正定値でなければ分解が失敗します。この対策が対角に小さな値 \(\epsilon\) (ジッター、典型値 \(10^{-10} \sim 10^{-6}\) )を足す \(\mathbf{K} + \epsilon \mathbf{I}\) という正則化です。ジッターはすべての固有値を \(\epsilon\) だけ底上げし、コレスキー分解が安全に通る最小固有値を保証します。
実行検証:速度・精度・安定性の実測
(1) コレスキー分解 vs 直接逆行列——訓練点数 \(n\)
を変えて、np.linalg.inv による直接計算と cho_factor/cho_solve による解法を、実行時間(20回の中央値)と残差 \(\|\mathbf{K}\boldsymbol{\alpha} - \mathbf{y}\|_\infty\)
(\(\boldsymbol{\alpha}\)
が連立方程式をどれだけ正確に満たすかの指標)で比較しました。
import time
rng = np.random.default_rng(0)
for n in [50, 200, 500, 1000, 2000]:
X = rng.uniform(-5, 5, size=(n, 1))
y = true_f(X.ravel()) + 0.1 * rng.standard_normal(n)
K = GaussianProcessRegressor(1.0, 1.0, 0.01).rbf(X, X) + 0.01 * np.eye(n)
t_direct, t_chol = [], []
for _ in range(50):
t0 = time.perf_counter()
alpha_direct = np.linalg.inv(K) @ y
t_direct.append(time.perf_counter() - t0)
t0 = time.perf_counter()
L, low = cho_factor(K, lower=True)
alpha_chol = cho_solve((L, low), y)
t_chol.append(time.perf_counter() - t0)
resid_direct = np.max(np.abs(K @ alpha_direct - y))
resid_chol = np.max(np.abs(K @ alpha_chol - y))
print(f"n={n}: direct={np.median(t_direct)*1e3:.3f}ms chol={np.median(t_chol)*1e3:.3f}ms "
f"speedup={np.median(t_direct)/np.median(t_chol):.2f}x "
f"resid_direct={resid_direct:.2e} resid_chol={resid_chol:.2e}")
実行結果:
n=50: direct=0.029ms chol=0.023ms speedup=1.22x resid_direct=1.67e-13 resid_chol=1.87e-14
n=200: direct=0.292ms chol=0.116ms speedup=2.53x resid_direct=4.17e-13 resid_chol=6.04e-14
n=500: direct=2.845ms chol=0.800ms speedup=3.56x resid_direct=5.70e-13 resid_chol=1.11e-13
n=1000: direct=18.183ms chol=4.401ms speedup=4.13x resid_direct=3.19e-12 resid_chol=3.75e-13
n=2000: direct=193.70ms chol=25.13ms speedup=7.71x resid_direct=4.85e-12 resid_chol=4.81e-13
\(n\) が大きくなるほどコレスキー分解の優位性が顕著になり、\(n=2000\) では 7.71倍高速でした(\(n=50\) ではオーバーヘッドが支配的でほぼ互角)。さらに注目すべきは残差の桁です。コレスキー分解による解は、あらゆる \(n\) で直接逆行列より5〜10倍小さい残差、つまり連立方程式をより正確に満たす解を返しています。「速いだけでなく精度も高い」ことが実測から確認できました。
(2) ジッターがないと何が起こるか——訓練点の一部をほぼ重複させた(\(10^{-9}\)
しか離れていない点を3組含む)30点のデータで、ジッターなしのカーネル行列の最小固有値と cho_factor の成否を確認しました。
rng2 = np.random.default_rng(1)
Xc = np.sort(rng2.uniform(-3, 3, 30)).reshape(-1, 1)
Xc[5, 0] = Xc[4, 0] + 1e-9 # ほぼ重複する点を3組つくる
Xc[15, 0] = Xc[14, 0] + 1e-9
Xc[25, 0] = Xc[24, 0] + 1e-9
K0 = GaussianProcessRegressor(1.0, 1.0, 0.0).rbf(Xc, Xc)
print("min eigenvalue (no jitter):", np.linalg.eigvalsh(K0).min())
try:
cho_factor(K0, lower=True)
print("cho_factor succeeded")
except np.linalg.LinAlgError as e:
print("cho_factor FAILED:", e)
for jit in [1e-10, 1e-8, 1e-6]:
ev = np.linalg.eigvalsh(K0 + jit * np.eye(30))
print(f"jitter={jit:.0e}: min_eig={ev.min():.3e}")
実行結果:
min eigenvalue (no jitter): -5.48e-16
cho_factor FAILED: Internal potrf return info = [13] for slices [0]
jitter=1e-10: min_eig=1.000e-10
jitter=1e-08: min_eig=1.000e-08
jitter=1e-06: min_eig=1.000e-06
ジッターなしでは最小固有値が理論上ゼロ以上のはずが \(-5.48\times10^{-16}\)
という浮動小数点誤差の範囲で負に転じ、cho_factor が「正定値ではない」というエラー(LAPACK の potrf がピボットの13行目で失敗)で停止しました。ジッターを \(10^{-10}\)
以上加えるだけで最小固有値がその値まで底上げされ、分解が安定して成功します。下図は、この2つの実験結果——(A) 訓練点数を増やしたときのコレスキー分解と直接逆行列の実行時間の差、(B) ジッターの有無・大きさとコレスキー分解の成否——をまとめたものです。
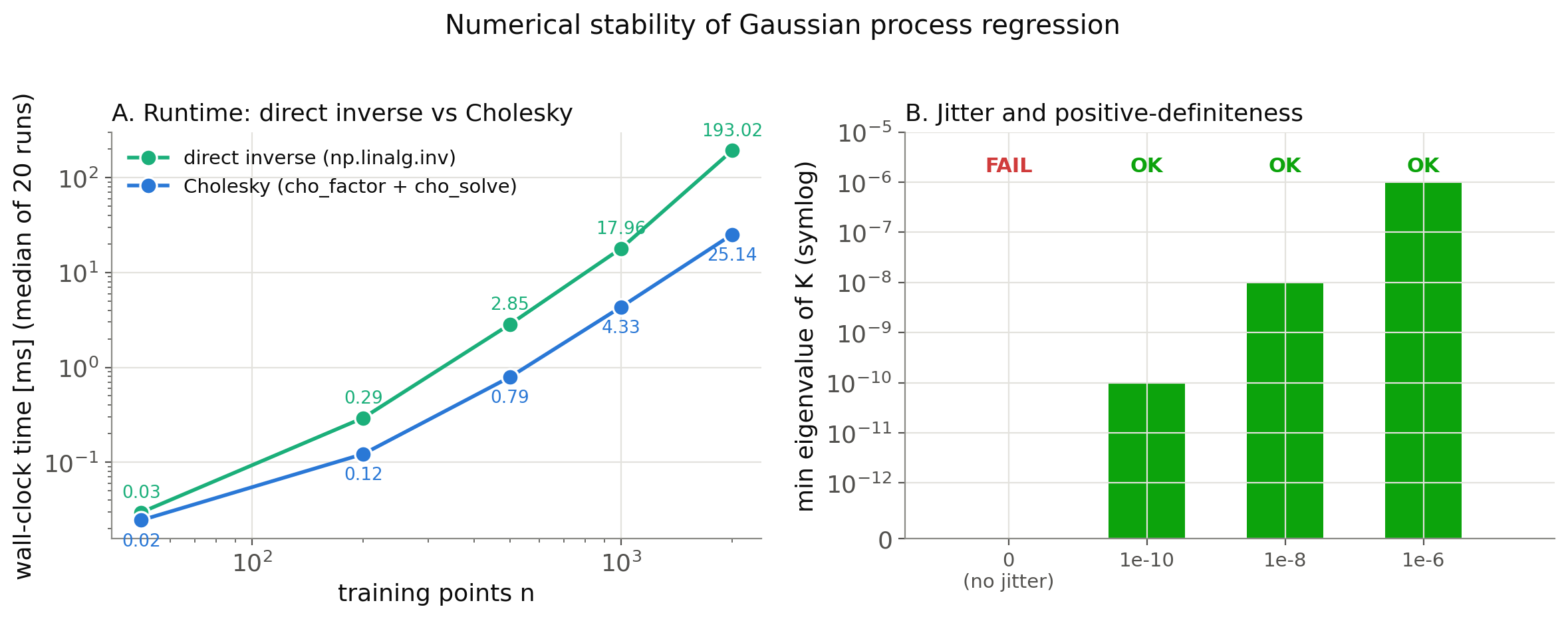
実務的な指針は明快です。逆行列は明示的に計算しない。ジッターは常に加える(scikit-learn の既定値は \(10^{-10}\)
前後)。カーネルの length scale を極端に大きくしすぎない——この3点を守るだけで、GP実装の数値的な落とし穴の大半を避けられます。
ハイパーパラメータの影響
length scale \(\ell\) とノイズ分散 \(\sigma_n^2\) は GP の挙動を大きく変えます。
length scale \(\ell\)
- \(\ell\) が小さい:局所的に激しく変動、データ点間の補間も急峻。過適合のリスク。
- \(\ell\) が大きい:滑らかな近似、データ点を貫通せず平均化される。過小適合のリスク。
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
for ax, l in zip(axes, [0.3, 1.0, 3.0]):
gp = GaussianProcessRegressor(length_scale=l, signal_var=1.0, noise_var=0.01)
gp.fit(X_train, y_train)
mu, var = gp.predict(X_test)
sigma = np.sqrt(var)
ax.plot(X_test, true_f(X_test.ravel()), "k--")
ax.plot(X_test, mu, "b-")
ax.fill_between(X_test.ravel(), mu - 1.96*sigma, mu + 1.96*sigma,
alpha=0.2, color="blue")
ax.scatter(X_train, y_train, c="red", s=40, zorder=5)
ax.set_title(f"length_scale = {l}")
ax.grid(True)
plt.tight_layout()
plt.savefig("gp_length_scale.png", dpi=150)
ノイズ分散 \(\sigma_n^2\)
\(\sigma_n^2\) が小さいと GP は観測点を厳密に通り、大きいと観測値からの乖離を許容して滑らかな曲線になります。式(6)の \((\mathbf{K} + \sigma_n^2 \mathbf{I})^{-1}\) の数値安定化 jitter としても重要です(典型値 \(10^{-6} \sim 10^{-4}\) )。
実用上は、式(8)の対数周辺尤度を scipy.optimize.minimize で最大化してハイパーパラメータを自動調整します。
スパースGP概観
前節までの通り、コレスキー分解を使ってもなお GP の学習は \(O(n^3)\) の計算量と \(O(n^2)\) のメモリを要します。ハイパーパラメータ最適化ではこの分解を反復評価するため、\(n \approx 10^4\) あたりが素朴な実装の実用上限とされます。
大規模データへのスケールアップに共通する発想は、\(m \ll n\) 個の誘導点(inducing points) \(\mathbf{Z} = \{\mathbf{z}_1, \ldots, \mathbf{z}_m\}\) を導入し、\(n \times n\) のカーネル行列 \(\mathbf{K}\) を低ランク行列 \(\mathbf{K}_{nm}\mathbf{K}_{mm}^{-1}\mathbf{K}_{mn}\) で近似することです。これにより逆行列の計算が \(m \times m\) の行列(Woodburyの恒等式により実質 \(O(nm^2)\) )に縮小されます。この基本アイデアの上に、予測分散の過小評価を補正する FITC、誘導点自体を変分下限の最大化で学習する VFE、ミニバッチ化して \(n \sim 10^6\) 超へ拡張する SVGP といった手法が積み重なっています。
誘導点法の導出・実装・使い分けの詳細は、本記事の理論を前提とした実務編である ガウス過程回帰の実践:カーネル設計と応用 で扱っています。ここでは「\(O(n^3)\) の壁を突破する主流の発想は次元削減(誘導点)である」という骨子だけを押さえておけば十分です。
近年の研究動向
GP 理論そのものは1990年代〜2000年代に確立されていますが、深層学習との融合や大規模化を巡る研究は現在も活発です。以下は2023年以降の代表的な方向性です(個々の手法の詳細は原論文を参照してください)。
Deep Kernel Learning(深層カーネル学習):入力をニューラルネットで非線形変換してからカーネルに通す手法は Wilson et al. (2016) が提案した古典的な枠組みですが、深いネットワークを使うほど対数周辺尤度の素朴な最大化が過信した(オーバーコンフィデントな)不確実性を生みやすいという問題が指摘されてきました。Zhu, Yuchi & Xie (2025) は、ニューラルネットで構成した低ランクの基底関数群(deep basis kernels)を使い、サンプル数に対して線形の計算量で推論しつつ、ミニバッチ確率的目的関数と分離された正則化によってこの過信問題に対処する手法を提案しています。
Neural Processes(NP):GP がテスト時に \(O(n^3)\) の行列分解を要するのに対し、NP は条件付き分布の推論をエンコーダ・デコーダ型ニューラルネットに**償却(amortize)**し、多数のタスク(関数)に対するメタ学習を通じて「1回の順伝播で予測分布を返す」枠組みを学習します。Wang, Federici & van Hoof(ICLR 2023; arXiv:2501.03264)は、NP の学習目的関数と目標対数尤度との間の乖離(inference gap)を、期待値最大化(EM)に基づく代理目的関数(SI-NP)で緩和する手法を提案し、より正確な関数事前分布の学習と目標対数尤度に対する改善保証を報告しています。
両者に共通するのは、GP が持つ較正された不確実性と、ニューラルネットが持つ表現力・スケーラビリティを両立させようとする問題意識です。どちらの方向も発展途上であり、本記事で導出した閉形式の事後分布(式6・式7)は、これらの近似・拡張手法が「何を再現しようとしているか」の基準点であり続けています。
ベイズ最適化への接続
GP の予測平均(式6)と予測分散(式7)は、ベイズ最適化のサロゲートモデルとしてそのまま再利用されます。獲得関数(Expected Improvement, UCB など)は \(\mu_*\) と \(\sigma_*\) の関数として定義され、不確実性が高くかつ改善が期待される点を次の評価点として選びます。
たとえば UCB 獲得関数は次のようにシンプルに書けます:
\[ \alpha_{\text{UCB}}(\mathbf{x}) = \mu_*(\mathbf{x}) - \kappa\, \sigma_*(\mathbf{x}) \tag{9} \]GP がベイズ最適化の根幹を支えていることがわかります。詳細は次の記事を参照してください。
おすすめ書籍
ガウス過程の理論からベイズ最適化への応用まで、日本語で体系的に学べる決定版です。
ベイズ推論の枠組みをゼロから積み上げる入門書で、本記事の背後にある確率モデリングの考え方を補強できます。
※ 上記は Amazon アソシエイトのリンクです。
関連記事
- SVMのカーネル設計:Mercerの定理・グラム行列の正定値性とRandom Fourier Features - 本記事で使うカーネル関数がなぜ妥当なのか(Mercerの定理・グラム行列の正定値性)を数学的に掘り下げ、SVMの文脈で解説しています。
- ガウス過程回帰の実践:カーネル設計と応用 - 本記事の理論を前提に、カーネルの選択・合成やハイパーパラメータ調整など、実データへ適用する際の実践ノウハウを解説しています。
- ベイズ最適化の基礎とPython実装 - 本記事のGPをサロゲートモデルとして用い、獲得関数(EI/UCB/PI)で効率的に大域最適解を探索する手法を解説しています。
- MCMC入門:メトロポリス・ヘイスティングス法とギブスサンプリング - GPの背景にあるベイズ推論の計算手法。
- Hamiltonian Monte Carlo(HMC)の理論とPython実装 - GPのハイパーパラメータをフルベイズ推定する際に、勾配情報を使い高相関事後分布でも効率的にサンプリングできるHMCが有用です。
- 確率的勾配降下法からAdamまで - GPで学習されたハイパーパラメータをチューニング対象とする勾配ベース最適化。
- サポートベクターマシン(SVM)の理論とPython実装 - 同じくRBFカーネルを用いる代表的な手法。GPの確率的予測とSVMの決定論的マージン最大化を対比できます。
- 粒子群最適化(PSO)の理論とPython実装 - 大量評価で探索する集団最適化。GPサロゲートを用いるベイズ最適化との評価コスト観点での使い分けが理解できます。
- Transformer による時系列予測:Self-Attention / 位置符号化 / Informer — 小データ・予測区間は GP、長系列・大データは Transformer、と「サンプル数 × 系列長」の 2 軸でモデル選択を整理できます。Transformer の attention 重みは「カーネル類似度」と類比的に解釈でき、GP の RBF カーネルと対比すると深く理解できます。
参考文献
- Rasmussen, C. E., & Williams, C. K. I. (2006). Gaussian Processes for Machine Learning. MIT Press.
- Murphy, K. P. (2023). Probabilistic Machine Learning: Advanced Topics. MIT Press, Ch. 18.
- Snelson, E., & Ghahramani, Z. (2006). “Sparse Gaussian Processes using Pseudo-inputs.” NeurIPS 2006.
- Hensman, J., Fusi, N., & Lawrence, N. D. (2013). “Gaussian Processes for Big Data.” UAI 2013.
- Aronszajn, N. (1950). “Theory of Reproducing Kernels.” Transactions of the American Mathematical Society, 68(3), 337–404.
- Kimeldorf, G., & Wahba, G. (1970). “A Correspondence Between Bayesian Estimation on Stochastic Processes and Smoothing by Splines.” The Annals of Mathematical Statistics, 41(2), 495–502.
- Schölkopf, B., Herbrich, R., & Smola, A. J. (2001). “A Generalized Representer Theorem.” COLT 2001, LNCS 2111.
- Wilson, A. G., Hu, Z., Salakhutdinov, R., & Xing, E. P. (2016). “Deep Kernel Learning.” AISTATS 2016.
- Zhu, Y., Yuchi, H. S., & Xie, Y. (2025). “Scalable Deep Basis Kernel Gaussian Processes.” arXiv:2505.18526.
- Wang, Q., Federici, M., & van Hoof, H. (2023). “Bridge the Inference Gaps of Neural Processes via Expectation Maximization.” ICLR 2023 (arXiv:2501.03264).