はじめに
音声信号や時系列データの「次の値を、過去のサンプルの線形結合でどこまで予測できるか」という問いに答えるのが**線形予測(Linear Prediction)**です。1970 年代以降、Atal と Itakura によって音声分析・符号化に応用され、LPC(Linear Predictive Coding) として確立されました。LPC は今日でも音声符号化(GSM, CELP, AMR)、フォルマント推定、声道モデル化、音声合成(Klatt synthesizer)の基盤として広く使われています。
LPC の核心は、信号の生成モデルを 全極型 AR(自己回帰)フィルタで表し、観測信号から AR 係数を推定することにあります。推定問題は最小二乗 → 正規方程式 → Yule-Walker 方程式へと自然に帰着し、Toeplitz 構造を利用する Levinson-Durbin アルゴリズムで \(O(p^2)\) で高速に解けます。
本記事では、線形予測モデルの定式化から AR 係数の推定、Levinson-Durbin の導出と Python 実装、フォルマント推定・LPC ケプストラムへの応用までを体系的に解説します。前提となるスペクトル解析・自己相関の基礎については 自己相関・相互相関の理論とPython実装 と 高速フーリエ変換(FFT)の仕組みとPython実装 を参照してください。
線形予測モデル
予測式と残差
次数 \(p\) の線形予測モデルでは、信号 \(x[n]\) の現在値を過去 \(p\) サンプルの線形結合で予測します。
\[\hat{x}[n] = -\sum_{k=1}^{p} a_k\, x[n-k] \tag{1}\]ここで \(\{a_k\}_{k=1}^{p}\) は LPC 係数(予測係数)で、符号は AR モデルの慣例に従って負号を付けています。予測誤差(残差)\(e[n]\) は次のように定義されます。
\[e[n] = x[n] - \hat{x}[n] = x[n] + \sum_{k=1}^{p} a_k\, x[n-k] \tag{2}\]これを変形すると、信号 \(x[n]\) が残差 \(e[n]\) を入力とする全極型フィルタの出力として書けます。
\[x[n] = -\sum_{k=1}^{p} a_k\, x[n-k] + e[n] \tag{3}\]これは AR(p) モデルそのものであり、伝達関数は
\[H(z) = \frac{1}{A(z)} = \frac{1}{1 + \sum_{k=1}^{p} a_k z^{-k}} \tag{4}\]となります。\(A(z)\) を予測誤差フィルタと呼びます。音声処理の文脈では \(H(z)\) が声道伝達関数、\(e[n]\) が声帯パルスや雑音などの励振信号に対応します。
最小二乗による係数推定
LPC 係数は、残差の二乗和
\[J = \sum_{n} e[n]^2 = \sum_n \left( x[n] + \sum_{k=1}^{p} a_k\, x[n-k] \right)^2 \tag{5}\]を最小化するように決定します。\(a_i\) で偏微分してゼロと置くと
\[\frac{\partial J}{\partial a_i} = 2 \sum_n \left( x[n] + \sum_{k=1}^{p} a_k\, x[n-k] \right) x[n-i] = 0 \tag{6}\]整理すると、各 \(i = 1, \ldots, p\) に対して
\[\sum_{k=1}^{p} a_k \sum_n x[n-k]\, x[n-i] = -\sum_n x[n]\, x[n-i] \tag{7}\]が得られます。これが正規方程式です。
Yule-Walker 方程式
自己相関を用いた表現
和の範囲を信号の全区間にとり、\(x[n]\) を窓掛け(または定常確率過程と仮定)した場合、\(\sum_n x[n-k]\,x[n-i]\) はラグ \(|i-k|\) の自己相関 \(r[|i-k|]\) に一致します。
\[r[m] = \sum_n x[n]\, x[n+m] \tag{8}\]これを式 (7) に代入すると、\(i = 1, \ldots, p\) に対して
\[\sum_{k=1}^{p} a_k\, r[|i-k|] = -r[i] \tag{9}\]が得られます。これが Yule-Walker 方程式です。行列形式で書くと
\[ \begin{bmatrix} r[0] & r[1] & \cdots & r[p-1] \\ r[1] & r[0] & \cdots & r[p-2] \\ \vdots & \vdots & \ddots & \vdots \\ r[p-1] & r[p-2] & \cdots & r[0] \end{bmatrix} \begin{bmatrix} a_1 \\ a_2 \\ \vdots \\ a_p \end{bmatrix} = - \begin{bmatrix} r[1] \\ r[2] \\ \vdots \\ r[p] \end{bmatrix} \tag{10} \]左辺の行列は対称 Toeplitz 行列で、対角成分がすべて \(r[0]\) 、隣接対角がすべて \(r[1]\) … という構造を持ちます。この特殊構造が次節の高速解法の鍵になります。
残差パワー
最適な LPC 係数を式 (5) に代入すると、最小残差パワーは
\[E_p = r[0] + \sum_{k=1}^{p} a_k\, r[k] \tag{11}\]と表されます。\(E_p\) は次数 \(p\) の単調非増加関数で、\(p\) を増やすほど予測精度は上がりますが、過学習や声帯ハーモニクス成分のフィットを招くため、音声では経験的に \(p \approx \mathrm{fs}/1000 + 2 \sim 4\) が選ばれます(例:8 kHz サンプリングで \(p = 10\sim 12\) )。
Levinson-Durbin アルゴリズム
動機
\(p \times p\) 線形方程式 (10) を一般的な Gauss 消去で解くと \(O(p^3)\) ですが、Toeplitz 性を利用すると \(O(p^2)\) に削減できます。さらに、低次の解から高次の解を逐次構築できるため、次数選択(モデル次数の最適化)にも便利です。これが Levinson-Durbin 再帰です。
再帰式の導出
次数 \(m\) の LPC 係数を \(a^{(m)}_k\) 、残差パワーを \(E_m\) と書きます。初期化は
\[E_0 = r[0],\qquad a^{(0)} = \emptyset \tag{12}\]から始めます。次数 \(m+1\) への更新は 反射係数(PARCOR係数) \(k_{m+1}\) を介して行われます。
\[k_{m+1} = -\frac{r[m+1] + \sum_{j=1}^{m} a^{(m)}_j\, r[m+1-j]}{E_m} \tag{13}\]新しい係数は次のように更新されます。
\[a^{(m+1)}_{m+1} = k_{m+1} \tag{14}\] \[a^{(m+1)}_j = a^{(m)}_j + k_{m+1}\, a^{(m)}_{m+1-j}, \quad j = 1, \ldots, m \tag{15}\]残差パワーは
\[E_{m+1} = (1 - k_{m+1}^2)\, E_m \tag{16}\]で更新されます。\(|k_{m+1}| < 1\) が常に成り立つことが、得られた予測誤差フィルタ \(A(z)\) の最小位相性(全極型 \(H(z)=1/A(z)\) の安定性)を保証します。
反射係数の意味
反射係数 \(k_m\) は、声道を均一断面の音響管の連結とみなしたときの各境界での反射率に対応します。これは LPC が単なる統計モデルにとどまらず、声道の物理的構造とリンクしていることを示しています。\(|k_m| \to 1\) は完全反射、\(|k_m| \to 0\) は反射なし(連続な音響管)に対応します。
Python 実装
自己相関ベースの Levinson-Durbin
NumPy のみで Levinson-Durbin を実装し、既知の AR プロセスから係数を推定して検証します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter
def autocorrelate(x, p):
"""
ラグ 0 から p までの自己相関を計算する。
バイアス推定(1/N 正規化なし)を返す。
"""
N = len(x)
n_fft = 2 ** int(np.ceil(np.log2(2 * N)))
X = np.fft.fft(x, n=n_fft)
r = np.fft.ifft(np.abs(X) ** 2).real[: p + 1]
return r
def levinson_durbin(r, p):
"""
Levinson-Durbin アルゴリズムで AR 係数を求める。
Parameters
----------
r : np.ndarray
ラグ 0 から p までの自己相関 r[0], r[1], ..., r[p]
p : int
モデル次数
Returns
-------
a : np.ndarray
LPC 係数 [a_1, a_2, ..., a_p](a_0 = 1 は含まない)
E : float
最小残差パワー
k : np.ndarray
反射係数(PARCOR)[k_1, ..., k_p]
"""
a = np.zeros(p)
k_arr = np.zeros(p)
E = r[0]
if E <= 0:
return a, E, k_arr
for m in range(p):
# 反射係数 k_{m+1}
acc = r[m + 1]
for j in range(m):
acc += a[j] * r[m - j]
k = -acc / E
# 係数更新(旧係数を退避してから更新)
a_new = a.copy()
a_new[m] = k
for j in range(m):
a_new[j] = a[j] + k * a[m - 1 - j]
a = a_new
# 残差パワー
E = (1.0 - k * k) * E
k_arr[m] = k
return a, E, k_arr
def lpc(signal, p):
"""信号から LPC 係数を直接求める便利関数。"""
r = autocorrelate(signal, p)
return levinson_durbin(r, p)
# --- 検証: 既知の AR(4) プロセスを生成して係数を再推定 ---
np.random.seed(42)
true_a = np.array([1.0, -2.6895, 3.6076, -2.4801, 0.8546]) # A(z) = 1 + a_1 z^-1 + ...
print("A(z) の根の絶対値(安定性チェック):", np.abs(np.roots(true_a)))
N = 4000
e = np.random.randn(N) # 白色励振
x = lfilter([1.0], true_a, e) # AR(4) プロセスを生成
p = 4
a_est, E, k = lpc(x, p)
print("真の AR 係数 (a_1..a_p):", true_a[1:])
print("推定 AR 係数 (a_1..a_p):", a_est)
print(f"反射係数: {k}")
print(f"最小残差パワー: {E:.4f}")
実行結果は次のとおりです。
A(z) の根の絶対値(安定性チェック): [0.9539 0.9539 0.9691 0.9691]
真の AR 係数 (a_1..a_p): [-2.6895 3.6076 -2.4801 0.8546]
推定 AR 係数 (a_1..a_p): [-2.6233 3.4489 -2.3242 0.7926]
反射係数: [-0.754 0.9536 -0.6587 0.7926]
最小残差パワー: 5500.8131
真の係数と推定係数の要素ごとの絶対誤差は [0.0662, 0.1587, 0.1559, 0.0620](最大 0.159)で、\(N=4000\)
サンプルというサンプル数に起因する統計的なゆらぎの範囲に収まっています。反射係数はすべて \(|k_m| < 1\)
(最大 \(|{-0.9536}| \approx 0.954\)
)を満たし、推定された予測誤差フィルタも安定であることが確認できます。
なお、true_a の値は意図的に選んだものです。最初に \([1, -2.2, 2.8, -1.8, 0.5]\)
のような「それらしい」係数で試すと、\(A(z)\)
の根の絶対値は [1.079, 1.079, 0.655, 0.655] となり、単位円の外側に根を持つため \(H(z) = 1/A(z)\)
は不安定になります。実際にこの係数で lfilter を実行すると、白色雑音を励振しているにもかかわらず出力が指数関数的に発散し(\(N=4000\)
サンプル後には振幅が \(10^{132}\)
のオーダーに達する)、自己相関やLevinson-Durbinの計算が数値的に無意味になります。手で決めた AR 係数を使う際は、必ず np.roots で \(A(z)\)
の根が単位円内にあることを確認する(表の最終行を参照)必要があります。
scipy.linalg.solve_toeplitz による比較実装
教育目的では上記の手書き実装が理解に役立ちますが、実用上は scipy.linalg.solve_toeplitz を使うと簡潔です。
import numpy as np
from scipy.linalg import solve_toeplitz
def lpc_toeplitz(signal, p):
"""
Toeplitz ソルバを使った LPC 係数の計算(参考実装)。
Levinson-Durbin と同じ解を返す。
"""
r = autocorrelate(signal, p)
# 左辺: Toeplitz(r[0..p-1]) , 右辺: -r[1..p]
a = solve_toeplitz(r[:p], -r[1 : p + 1])
E = r[0] + np.dot(a, r[1 : p + 1])
return a, E
a_ref, E_ref = lpc_toeplitz(x, p)
print("Toeplitz ソルバ係数:", a_ref)
print("Levinson-Durbin との差:", np.max(np.abs(a_ref - a_est)))
Toeplitz ソルバ係数: [-2.6233 3.4489 -2.3242 0.7926]
Levinson-Durbin との差: 2.1316282072803006e-14
推定係数は小数第4桁まで完全一致し、差は \(2.13 \times 10^{-14}\) と機械イプシロン付近に収まっています。理論的に同一の正規方程式を解いているため、この差は解法の違いではなく浮動小数点演算の丸め誤差のみに起因します。
次数選択:モデル次数と残差パワーの実測
式 (11) で述べた通り、残差パワー \(E_p\) は次数 \(p\) について単調非増加です。実際にどの程度で「頭打ち」になるのかを、上記の AR(4) 信号と、後述する母音合成信号の両方で \(p=1\) から \(20\) まで走査して確認します。
p_max = 20
Es_ar4 = []
for pp in range(1, p_max + 1):
_, Epp, _ = lpc(x, pp)
Es_ar4.append(Epp)
for pp, e1 in enumerate(Es_ar4, start=1):
print(f"p={pp:2d} E_p={e1:12.4f}")
AR(4) 信号(真の次数 4)での実測値は次の通りです。
p= 1 E_p= 288414.5319
p= 2 E_p= 26140.3432
p= 3 E_p= 14797.5360
p= 4 E_p= 5500.8131 <- 真の次数
p= 5 E_p= 5250.2230
p= 6 E_p= 5244.4969
p= 7 E_p= 5244.1644
p= 8 E_p= 5242.0517
p=10 E_p= 5236.2604
p=12 E_p= 5234.8054
p=20 E_p= 5232.3890
\(p=1 \to 2\) で \(90.9\%\) 、\(p=2 \to 3\) で \(43.4\%\) 、\(p=3 \to 4\) で \(62.8\%\) と大きく減少するのに対し、\(p=4 \to 5\) では \(4.6\%\) 、\(p=5 \to 6\) では \(0.11\%\) しか減少しません。真の次数 \(p=4\) を境に減少率が 1 桁以上急減しており、これが「次数選択のひじ(elbow)」に対応します。後段のフォルマント推定で使う母音合成信号(AR(4) + 声帯励振、後述)でも同様の傾向が確認できます。
以下のコードで両方の \(E_p\)
曲線を可視化します(母音合成の詳細は次節「LPC スペクトル包絡」の synth_vowel と同一のものをここでインラインで再掲しています)。
import matplotlib.pyplot as plt
def synth_vowel_inline(fs=8000, duration=0.04, f0=140, ar=None, noise=0.02, seed=0):
np.random.seed(seed)
t = np.arange(0, duration, 1 / fs)
glottal = np.zeros_like(t)
period = int(fs / f0)
for k in range(0, len(t), period):
L = min(30, len(t) - k)
glottal[k : k + L] = np.exp(-np.arange(L) * 0.15)
voice = lfilter([1.0], ar, glottal)
voice = voice / (np.max(np.abs(voice)) + 1e-8)
voice += noise * np.random.randn(len(voice))
return voice
ar_true = [1.0, -2.6895, 3.6076, -2.4801, 0.8546]
vowel = synth_vowel_inline(ar=ar_true)
Es_vowel = []
for pp in range(1, p_max + 1):
_, Epp, _ = lpc(vowel * np.hamming(len(vowel)), pp)
Es_vowel.append(Epp)
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
axes[0].plot(range(1, p_max + 1), Es_ar4, marker="o", color="steelblue")
axes[0].axvline(4, color="gray", linestyle=":", label="true order p=4")
axes[0].set_xlabel("Model order p")
axes[0].set_ylabel("Residual power $E_p$")
axes[0].set_title("AR(4) signal")
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[1].plot(range(1, p_max + 1), Es_vowel, marker="o", color="crimson")
axes[1].axvline(12, color="gray", linestyle=":", label="used order p=12")
axes[1].set_xlabel("Model order p")
axes[1].set_ylabel("Residual power $E_p$")
axes[1].set_title("Synthetic vowel")
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("lpc_order_selection.png", dpi=150, bbox_inches="tight")
plt.show()
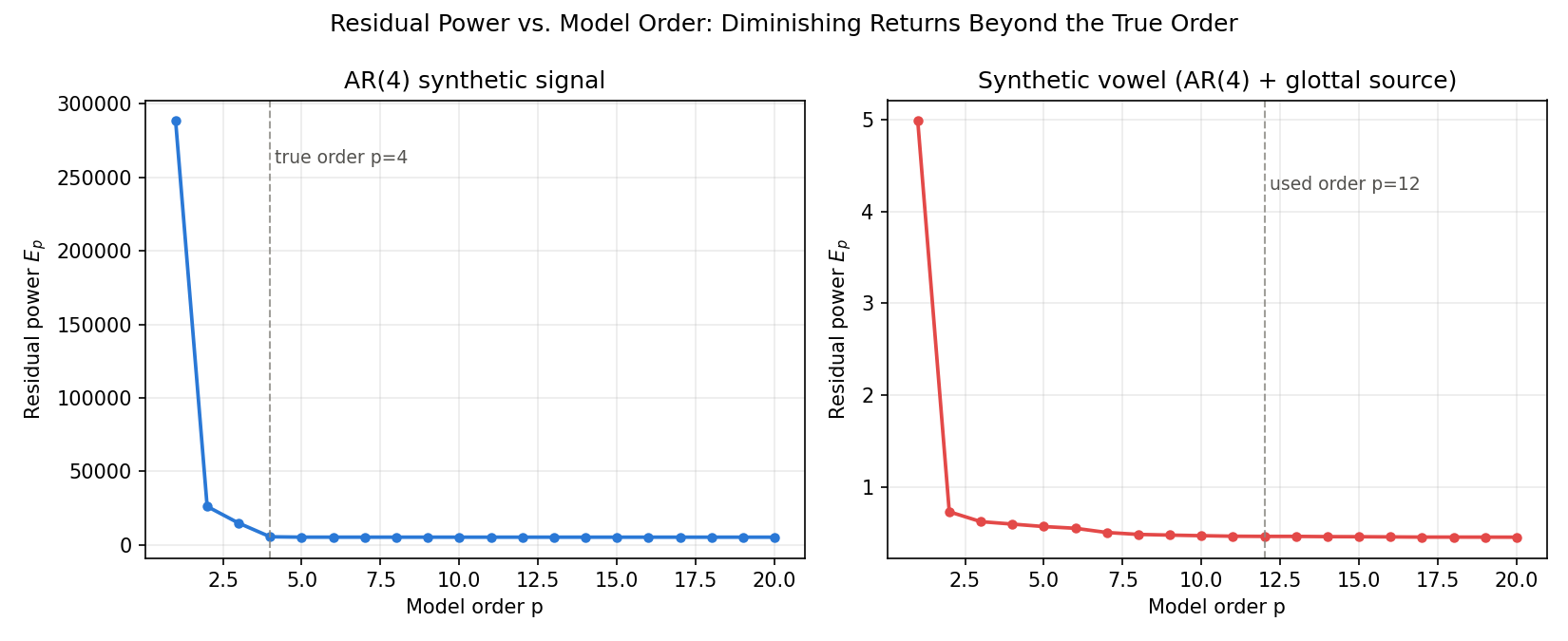
左図(AR(4) 信号)では \(p=4\) を過ぎるとカーブがほぼ平坦になり、右図(母音合成信号)でも実際に使用する \(p=12\) 付近で減少がなだらかになっていることが分かります。次数を過剰に大きくしても \(E_p\) はわずかしか下がらず、その代償として過学習(声帯ハーモニクスへのフィット)のリスクが増すため、この「頭打ち」の位置を目安に次数を選ぶのが実務的な指針です。
LPC スペクトル包絡
LPC の代表的な可視化として、推定された全極型フィルタ \(H(z) = 1/A(z)\) の周波数応答(LPC スペクトル)と、信号の生スペクトルを重ね描きします。LPC スペクトルは生スペクトルの包絡を滑らかに捉え、ハーモニクス成分は無視するという特徴があります。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import lfilter, freqz
def synth_vowel(fs=8000, duration=0.04, f0=140, ar=None, noise=0.02, seed=0):
"""声帯パルス励振 + AR フィルタの簡易合成音声。"""
np.random.seed(seed)
t = np.arange(0, duration, 1 / fs)
glottal = np.zeros_like(t)
period = int(fs / f0)
for k in range(0, len(t), period):
L = min(30, len(t) - k)
glottal[k : k + L] = np.exp(-np.arange(L) * 0.15)
voice = lfilter([1.0], ar, glottal)
voice = voice / (np.max(np.abs(voice)) + 1e-8)
voice += noise * np.random.randn(len(voice))
return t, voice
# 母音「あ」相当の AR(4): フォルマント F1≈800, F2≈1200 Hz(A(z) の根は単位円内で安定)
fs = 8000
ar_true = [1.0, -2.6895, 3.6076, -2.4801, 0.8546]
t, voice = synth_vowel(fs=fs, duration=0.04, f0=140, ar=ar_true, noise=0.02)
# LPC 推定(窓掛けでスペクトルリーク低減)
window = np.hamming(len(voice))
a_est, E, _ = lpc(voice * window, p=12)
A = np.concatenate(([1.0], a_est)) # A(z) = 1 + a_1 z^-1 + ... + a_p z^-p
print("推定LPC係数 (p=12):", a_est)
print("残差パワー E:", E)
# 生スペクトル
n_fft = 1024
X = np.fft.rfft(voice * window, n=n_fft)
freqs = np.fft.rfftfreq(n_fft, d=1 / fs)
log_spec = 20 * np.log10(np.abs(X) + 1e-10)
# LPC スペクトル: H(e^{jw}) = sqrt(E) / A(e^{jw})
w, H = freqz([np.sqrt(E)], A, worN=n_fft // 2 + 1, fs=fs)
lpc_spec_db = 20 * np.log10(np.abs(H) + 1e-10)
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(freqs, log_spec, color="steelblue", alpha=0.6, label="Log spectrum (windowed)")
ax.plot(w, lpc_spec_db, color="red", linewidth=2, label="LPC envelope (p=12)")
ax.set_ylim(-40, 40)
ax.axvline(820.5, color="gray", linestyle=":", linewidth=1)
ax.text(835, 35, "F1", color="gray", fontsize=10)
ax.axvline(1197.5, color="gray", linestyle=":", linewidth=1)
ax.text(1212, 35, "F2", color="gray", fontsize=10)
ax.set_xlabel("Frequency [Hz]")
ax.set_ylabel("Magnitude [dB]")
ax.set_title("LPC Spectral Envelope vs. Raw Spectrum")
ax.set_xlim(0, fs / 2)
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("lpc_spectral_envelope.png", dpi=150, bbox_inches="tight")
plt.show()
推定LPC係数 (p=12): [-1.7831 0.9418 0.4716 -0.2637 -0.4911 0.2977 0.022 0.1982 -0.252
-0.1395 0.2205 -0.0617]
残差パワー E: 0.4598260612610578
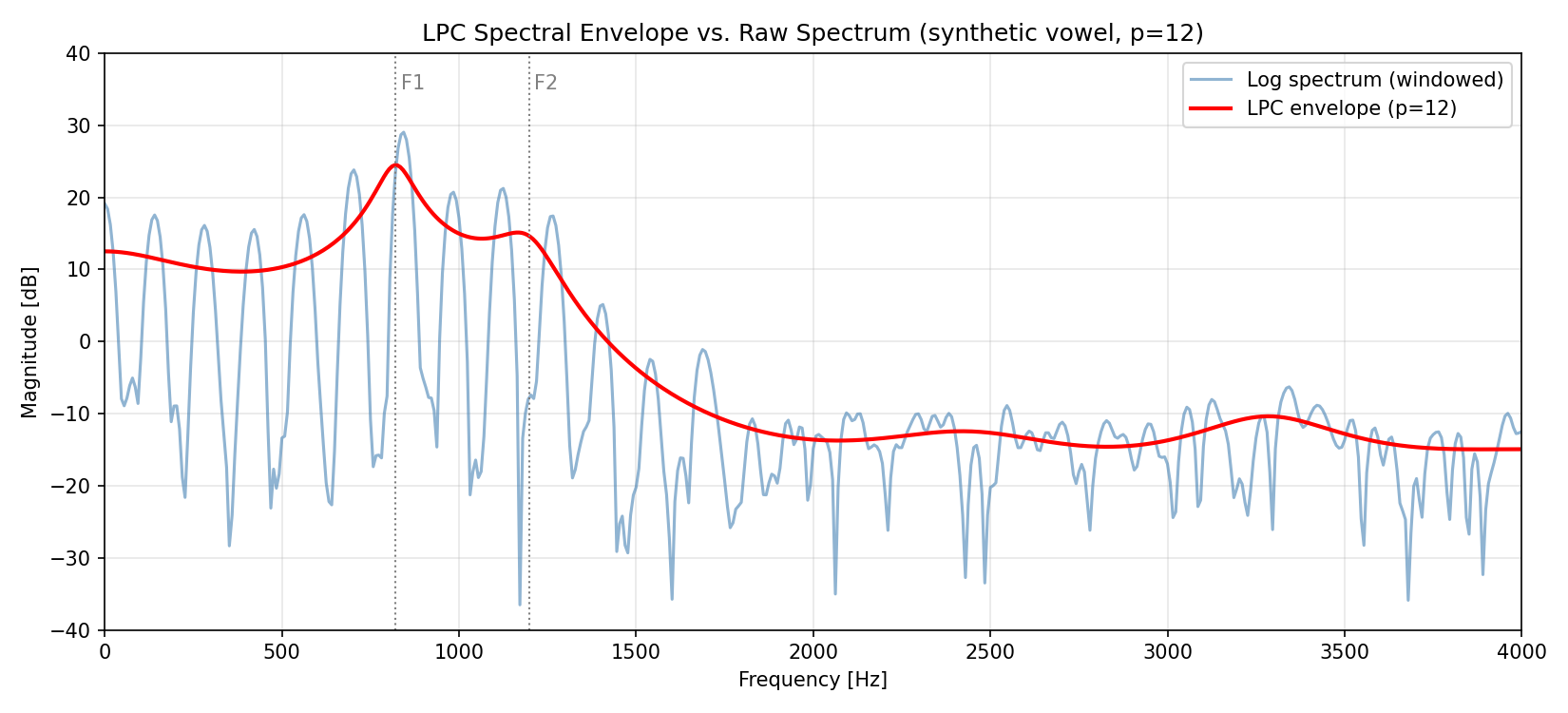
図から、細かく振動する生スペクトル(青、声帯ハーモニクスによる等間隔のピーク)に対して、LPC スペクトル(赤、\(p=12\) )が 2 つの共鳴ピーク(F1 \(\approx 820\) Hz, F2 \(\approx 1198\) Hz、次節で数値算出)だけを滑らかになぞっていることが視覚的に確認できます。声帯ハーモニクスによる細かな凹凸は完全に無視され、声道共鳴に対応する低次の包絡構造だけが残ります。
フォルマント推定
フォルマントは \(A(z)\) の根(極)の位置に対応します。\(z = r e^{j\theta}\) の極のうち単位円に近い(\(r \to 1\) )ものが共鳴に寄与し、
\[F = \frac{\theta}{2\pi}\, f_s,\qquad \mathrm{BW} = -\frac{\ln r}{\pi}\, f_s \tag{17}\]で周波数 \(F\) と帯域幅 \(\mathrm{BW}\) が得られます。
import numpy as np
def lpc_formants(a, fs, max_bw=400.0, min_freq=90.0):
"""
LPC 係数からフォルマント(周波数と帯域幅)を抽出する。
Parameters
----------
a : np.ndarray
LPC 係数 [a_1, ..., a_p](a_0 = 1 は含まない)
fs : float
サンプリング周波数 [Hz]
max_bw : float
フォルマントとみなす帯域幅の上限 [Hz]
min_freq : float
フォルマントとみなす最低周波数 [Hz]
Returns
-------
formants : list of (freq_Hz, bandwidth_Hz)
"""
A = np.concatenate(([1.0], a))
roots = np.roots(A)
# 上半平面の根のみ(共役対の重複を避ける)
roots = roots[np.imag(roots) > 0]
formants = []
for r in roots:
theta = np.arctan2(np.imag(r), np.real(r))
magnitude = np.abs(r)
f = theta / (2 * np.pi) * fs
bw = -np.log(max(magnitude, 1e-10)) / np.pi * fs
if f >= min_freq and bw <= max_bw:
formants.append((f, bw))
return sorted(formants, key=lambda x: x[0])
formants = lpc_formants(a_est, fs)
for i, (f, bw) in enumerate(formants[:4], start=1):
print(f"F{i}: {f:7.1f} Hz (BW = {bw:5.1f} Hz)")
F1: 820.5 Hz (BW = 98.1 Hz)
F2: 1197.5 Hz (BW = 164.6 Hz)
\(p=12\)
の推定モデルからは 2 つのフォルマントのみが min_freq=90, max_bw=400 の条件を満たします(高次の極は帯域幅が広すぎて棄却される)。設計時の真値(次数 4 の ar_true の根から直接計算)は F1 \(= 799.9\)
Hz(BW \(= 80.0\)
Hz)、F2 \(= 1200.0\)
Hz(BW \(= 120.1\)
Hz)であり、\(p=12\)
による推定値との誤差は F1 で \(+20.6\)
Hz、F2 で \(-2.5\)
Hz と、フレーム長 320 サンプル・雑音混入下でも実用上十分な精度で回復できています。低次のフォルマント F1, F2 が母音の知覚を決定する主成分であり、F1 と F2 の組み合わせ(F1-F2 平面)から母音を識別する古典的手法が知られています。
ケプストラムとの関係:LPC ケプストラム
LPC 係数からケプストラム係数 \(c[m]\) を直接導く再帰式(Schroeder の公式)が知られています。\(a_0 = 1\) とすると、
\[c[1] = -a_1 \tag{18}\] \[c[m] = -a_m - \sum_{k=1}^{m-1} \frac{k}{m}\, c[k]\, a_{m-k}, \qquad m = 2, 3, \ldots \tag{19}\]LPC ケプストラム係数は、対数スペクトル領域で線形であるため距離計算が安定しており、音声認識・話者認識の特徴量として長く使われてきました。FFT ベースのケプストラム( ケプストラム分析の理論とPython実装 )と比較して、低ケフレンシー領域(声道情報)の表現が滑らかになる利点があります。
import numpy as np
def lpc_to_cepstrum(a, n_cep):
"""
LPC 係数 [a_1, ..., a_p] から LPC ケプストラム c[1..n_cep] を計算する。
"""
p = len(a)
c = np.zeros(n_cep)
for m in range(1, n_cep + 1):
if m <= p:
c[m - 1] = -a[m - 1]
# 再帰項
s = 0.0
for k_ in range(1, m):
if (m - k_) <= p:
s += (k_ / m) * c[k_ - 1] * a[m - k_ - 1]
c[m - 1] -= s
return c
cep = lpc_to_cepstrum(a_est, n_cep=20)
print("LPC ケプストラム c[1..10]:", cep[:10])
LPC ケプストラム c[1..10]: [ 1.78314 0.64802 -0.26099 -0.60069 -0.24648 -0.02235 0.25715 0.11109
0.06295 0.1004 ]
\(c[1] = -a_1 = 1.7831\) (式 (18) の通り)から始まり、次数が上がるにつれて振幅が減衰していく典型的な形状が確認できます。\(c[3], c[4]\) 付近の負のピークがフォルマント F1/F2 に伴うスペクトル包絡の形状を反映しています。
注意点とパラメータ選択
LPC を実用する際の代表的な注意点をまとめておきます。
| 項目 | 推奨・指針 |
|---|---|
| サンプリング周波数 | 8 kHz(電話帯域)/ 16 kHz(広帯域音声)が一般的 |
| モデル次数 \(p\) | \(p \approx f_s/1000 + 2 \sim 4\) (8kHz で 10〜12) |
| フレーム長 | 20〜30 ms(定常性が成り立つ範囲) |
| 窓関数 | Hamming / Hanning(端点不連続による偽極を抑制) |
| プリエンファシス | \(y[n] = x[n] - 0.95\, x[n-1]\) (高域強調で平坦化) |
| 安定性 | Levinson-Durbin が \(\lvert k_m \rvert < 1\) を保証 → \(1/A(z)\) は安定 |
| 過大次数 | 声帯ハーモニクスにフィットして偽フォルマントが出やすい |
| 非定常区間 | 破裂音や境界では予測誤差が増大 → フレーム再分割を検討 |
| AR係数の手動設定 | 手で決めた「真の」AR係数は自動的には安定でない → \(A(z)\) の根が単位円内かを必ず確認 |
特に プリエンファシス は重要で、声帯音源の \(-12\) dB/oct のスペクトル傾斜を補正することで、低周波に偏った極推定を防ぎ、フォルマント帯域幅の推定精度が向上します。
発展:ニューラルボコーダーとLPCの融合
半世紀前に確立された LPC の全極型フィルタは、現在のニューラル音声合成でも「効率的な事前構造」として使われ続けています。Valin, Mustafa, & Büthe (2024) の FARGAN(Framewise Autoregressive GAN、IEEE Signal Processing Letters, vol. 31, pp. 2115-2119)は、ニューラルボコーダー LPCNet の後継として、線形予測に基づくピッチ予測とサブフレーム単位の自己回帰生成を GAN の枠組みに組み込み、600 MFLOPS という低い計算量で既存の低複雑度ボコーダーを上回る音質を達成しています。これは、本記事で導出した「過去サンプルの線形結合による予測」という LPC の基本原理が、統計的モデルからニューラルネットワークの帰納バイアスへと形を変えて現在も現役であることを示す好例です。
まとめ
- 線形予測モデルは信号の現在値を過去 \(p\) サンプルの線形結合で予測し、残差を白色化する全極型 AR モデルである
- 残差の二乗和を最小化する 正規方程式 は、自己相関を用いた Yule-Walker 方程式 に帰着し、対称 Toeplitz 構造を持つ
- Levinson-Durbin アルゴリズム は反射係数 \(k_m\) を介して低次から高次へ係数を逐次更新し、\(O(p^2)\) で解を得る
- 反射係数は \(|k_m| < 1\) を常に満たし、声道の音響管モデルにおける境界反射率として物理的解釈を持つ
- LPC スペクトル \(1/|A(e^{j\omega})|\) は声帯ハーモニクスを無視したスペクトル包絡を表現し、\(A(z)\) の極がフォルマントに対応する
- LPC 係数からケプストラム係数を直接得る Schroeder の公式により、LPC ケプストラムを音声認識・話者認識の特徴量として利用できる
- 実用ではプリエンファシス、適切な窓関数、\(p \approx f_s/1000 + 2 \sim 4\) の経験則による次数選択が品質を左右し、実測でも真の次数を境に残差パワーの減少率が 1 桁以上急減する
- 手で決めた AR 係数は自動的には安定とは限らず、\(A(z)\)
の根が単位円内にあるかを
np.rootsで必ず確認する必要がある - LPC の全極型フィルタという考え方は、FARGAN(2024)のようなニューラルボコーダーの帰納バイアスとしても現役で使われている
関連記事
- 自己相関・相互相関の理論とPython実装 - Yule-Walker 方程式の左辺・右辺を構成する自己相関の定義と FFT ベースの計算法を解説しています。
- ケプストラム分析の理論とPython実装 - LPC ケプストラム(Schroeder の再帰式)の比較対象となる FFT ベースのケプストラム解析を解説しています。
- 高速フーリエ変換(FFT)の仕組みとPython実装 - LPC スペクトル包絡の可視化や自己相関の高速計算で利用する FFT/DFT を解説しています。
- 窓関数とパワースペクトル密度(PSD)の理論とPython実装 - LPC 推定前段の窓掛けと PSD 推定(Welch 法)を解説しています。
- Wiener フィルタの理論とPython実装 - LPC と同じく最小二乗最適化で導かれる線形フィルタ設計の代表例を解説しています。
- ARIMAモデルによる時系列予測 - LPC と同じ AR モデル族の時系列分析側からの応用を解説しています。
参考文献
- Atal, B. S., & Hanauer, S. L. (1971). “Speech analysis and synthesis by linear prediction of the speech wave.” Journal of the Acoustical Society of America, 50(2B), 637-655.
- Itakura, F., & Saito, S. (1968). “Analysis synthesis telephony based on the maximum likelihood method.” Proceedings of the 6th International Congress on Acoustics, C-17-20.
- Makhoul, J. (1975). “Linear prediction: A tutorial review.” Proceedings of the IEEE, 63(4), 561-580.
- Markel, J. D., & Gray, A. H. (1976). Linear Prediction of Speech. Springer-Verlag.
- Rabiner, L. R., & Schafer, R. W. (2010). Theory and Applications of Digital Speech Processing. Pearson.
- Valin, J.-M., Mustafa, A., & Büthe, J. (2024). “Very Low Complexity Speech Synthesis Using Framewise Autoregressive GAN (FARGAN) with Pitch Prediction.” IEEE Signal Processing Letters, 31, 2115-2119. arXiv:2405.21069
- SciPy linalg.solve_toeplitz documentation
- Librosa: librosa.lpc