はじめに
モンテカルロ最適化(Monte Carlo optimization) とは、勾配 \(\nabla f\) に頼らず 無作為サンプル を使って目的関数 \(f(x)\) の最小値(あるいは最大値)を探索する手法群の総称です。微分不可能な目的関数、ブラックボックスシミュレータ、多峰性のある探索空間など、勾配法が破綻する状況でこそ威力を発揮します。
クロスエントロピー法(CEM) 、 焼きなまし法(SA) 、 遺伝的アルゴリズム(GA) 、 MPPI 、 粒子群最適化(PSO) は、いずれもこの「サンプリング→評価→更新」を骨格とするモンテカルロ最適化の代表例です。本記事はそれぞれの手法を 横断的に位置づけ、共通フレームワーク・使い分け指針・Python 実装をハブ的に整理することを目的とします。
モンテカルロ最適化の共通骨格
すべての手法は、以下の 3 ステップを反復しているとみなせます。
- サンプリング: 現在の確率分布 \(p_t(x)\) または現解 \(x_t\) の近傍から \(N\) 個のサンプル \(\{x^{(i)}\}_{i=1}^{N}\) を生成
- 評価: 各サンプルに対し目的関数値 \(f(x^{(i)})\) を計算
- 更新: 評価結果から「次の分布 \(p_{t+1}\) あるいは次解 \(x_{t+1}\) 」を構成
数式で書けば、共通の更新は次のように表せます。
\[ p_{t+1}(x) = \mathcal{U}\big(p_t,\, \{(x^{(i)}, f(x^{(i)}))\}_{i=1}^{N}\big) \tag{1} \]ここで \(\mathcal{U}\) が 手法ごとに異なる更新オペレータ です。CEM ならエリート分位点の経験分布へのフィット、SA なら Boltzmann 比による確率的受理、GA なら選択・交叉・突然変異、MPPI ならコスト指数重み付け平均、PSO なら速度ベクトルの慣性 + 認知 + 社会更新——これらはすべて同じ枠組みの 異なる \(\mathcal{U}\) にすぎません。
ベイズ最適化 もサンプリング型最適化の一種ですが、サロゲートモデル(ガウス過程)と獲得関数を介する点で「分布更新」よりも「サンプリング点選択」を重視する位置づけになります。また パーティクルフィルタ はモンテカルロサンプリングを 状態推定 に用いる兄弟手法であり、リサンプリング機構が CEM のエリート選択や MPPI の重み付けと数学的に等価です。
各手法の位置づけ表
| 手法 | 探索戦略 | 解の表現 | 主な用途 | 計算コスト | 微分 |
|---|---|---|---|---|---|
| CEM | 分布更新(エリート分位点) | パラメトリック分布 | 連続最適化、強化学習方策最適化 | 中(並列化容易) | 不要 |
| SA | 確率的受理(温度スケジュール) | 単一解 | 組合せ最適化、TSP、ハイパーパラメータ | 低(逐次) | 不要 |
| GA | 個体集団の進化(交叉・突然変異) | 集団 | 大域最適化、構造設計 | 高(評価回数大) | 不要 |
| MPPI | 重点サンプリング(指数重み) | 軌道列の分布 | モデル予測制御、ロボティクス | 中〜高(並列化必須) | 不要 |
| PSO | 慣性 + 認知 + 社会更新 | 粒子群 | 連続最適化、群知能タスク | 中 | 不要 |
| ベイズ最適化 | サロゲート + 獲得関数 | GP 後分布 | 評価コストが高い問題 | 高(サロゲート更新) | 不要(GP 内部で勾配) |
「微分不要」「並列評価可能」「多峰性に強い」という 3 つの性質はすべての手法に共通します。違いは どの確率モデルを使い、どんな更新で集中させるか にあります。
共通フレームワークの Python 実装
実際にどの手法も次のように、同じスケルトンに sample と update だけを差し替える だけで書けます。
import numpy as np
def monte_carlo_optimize(
f, sampler, updater, init_state, n_iter=50, n_samples=100, seed=0
):
"""
汎用モンテカルロ最適化ループ。
Parameters
----------
f : callable 目的関数 f(x) を最小化
sampler : callable state -> shape (n_samples, dim) のサンプル配列
updater : callable (state, samples, scores) -> 新しい state
init_state : 初期状態(手法ごとに分布パラメータ・個体集団など)
n_iter : 反復回数
n_samples : 1反復あたりのサンプル数
"""
rng = np.random.default_rng(seed)
state = init_state
history = []
for t in range(n_iter):
samples = sampler(state, n_samples, rng)
scores = np.array([f(x) for x in samples])
state = updater(state, samples, scores)
best = scores.min()
history.append(best)
return state, np.array(history)
# === 例1: CEMライクな更新(エリート分位点で正規分布をフィット) ===
def cem_sampler(state, n, rng):
mu, sigma = state
return rng.normal(mu, sigma, size=(n, mu.shape[0]))
def cem_updater(state, samples, scores, elite_frac=0.2):
mu, sigma = state
k = max(1, int(len(scores) * elite_frac))
elite_idx = np.argsort(scores)[:k]
elite = samples[elite_idx]
return elite.mean(axis=0), elite.std(axis=0) + 1e-6
# === 例2: PSOライクな更新(速度更新) ===
def make_pso(dim, n_particles, w=0.7, c1=1.5, c2=1.5):
def sampler(state, n, rng):
x, v, pbest, pbest_val, gbest = state
return x # PSO は state そのものを評価する
def updater(state, samples, scores):
x, v, pbest, pbest_val, gbest = state
# 個体ベスト更新
improved = scores < pbest_val
pbest = np.where(improved[:, None], x, pbest)
pbest_val = np.where(improved, scores, pbest_val)
# 大域ベスト更新
g_idx = pbest_val.argmin()
gbest = pbest[g_idx]
# 速度・位置更新
rng = np.random.default_rng()
r1, r2 = rng.random(x.shape), rng.random(x.shape)
v = w * v + c1 * r1 * (pbest - x) + c2 * r2 * (gbest - x)
x = x + v
return x, v, pbest, pbest_val, gbest
return sampler, updater
# === 目的関数: Rastrigin (多峰性ベンチマーク) ===
def rastrigin(x, A=10.0):
n = x.shape[0]
return A * n + np.sum(x ** 2 - A * np.cos(2 * np.pi * x))
# === CEM で最適化 ===
dim = 5
init_state = (np.zeros(dim), np.ones(dim) * 2.0)
state, hist = monte_carlo_optimize(
rastrigin, cem_sampler, cem_updater, init_state,
n_iter=40, n_samples=200
)
print(f"CEM best: {hist.min():.4f}")
上記のスケルトンは CEM・SA・GA・MPPI・PSO すべてに流用 できます。SA なら sampler が「現解の近傍ランダムウォーク」、updater が「Metropolis 受理判定」になります。GA なら sampler が「現世代そのもの」、updater が「選択 + 交叉 + 突然変異」になります。MPPI なら sampler が「制御列ノイズ付き軌道生成」、updater が「コスト指数重み付き平均で名目制御列を更新」になります。
この一般化は理論的にも重要で、CEM と MPPI が 重点サンプリングの最適提案分布 という同じ起源を共有することは MPPI 解説記事 で詳しく述べています。
5手法の収束曲線比較:実行検証
「同じ骨格の異なる \(\mathcal{U}\) 」という主張を実際に検証するため、CEM・SA・GA・MPPI・PSO の5手法を 同一のベンチマーク関数・同一の開始点・同一の評価回数バジェット で走らせ、収束曲線を比較します。
- ベンチマーク: シフト付き Rastrigin 関数(5次元)。大域最小値は \(z = x - x^\ast = 0\) で 0 になるよう、大域解を原点からずらしています(\(x^\ast\) に原点を選ぶと初期化バイアスで手法間の差が見えにくくなるため)
- 開始点: 全手法で
x0 = [-4, 4, -4, 4, -4](大域解から離れた共通の初期値) - 評価回数バジェット: 反復数 40 × 1反復あたり200サンプル = 延べ8,000回の関数評価で統一
- 乱数:
np.random.default_rng(seed=0)で最適化ループ自体を、np.random.default_rng(seed=1)で初期集団生成をそれぞれ固定し、再現可能にしています
updater にも乱数生成器 rng を渡せるよう拡張しています(SA の Metropolis 受理判定や GA の交叉・突然変異には乱数が必要なため、先ほどの updater(state, samples, scores) から updater(state, samples, scores, rng) へシグネチャを一般化します)。
import numpy as np
# --- 共通ベンチマーク: シフト付き Rastrigin (dim=5, 大域最小 x*=shift で 0) ---
dim = 5
shift = np.array([3.0, -2.0, 1.0, -2.5, 4.0])
def rastrigin(x, A=10.0):
z = x - shift
n = z.shape[0]
return A * n + np.sum(z**2 - A * np.cos(2 * np.pi * z))
x0 = np.array([-4.0, 4.0, -4.0, 4.0, -4.0]) # 全手法共通の開始点
# --- 汎用ループ(updater にも rng を渡す拡張版) ---
def monte_carlo_optimize(f, sampler, updater, init_state, n_iter=40, n_samples=200, seed=0):
rng = np.random.default_rng(seed)
state = init_state
history = []
best_so_far = np.inf
for t in range(n_iter):
samples = sampler(state, n_samples, rng)
scores = np.array([f(x) for x in samples])
state = updater(state, samples, scores, rng)
best_so_far = min(best_so_far, scores.min())
history.append(best_so_far)
return state, np.array(history)
# --- CEM: エリート分位点で正規分布をフィット ---
def cem_sampler(state, n, rng):
mu, sigma = state
return rng.normal(mu, sigma, size=(n, mu.shape[0]))
def cem_updater(state, samples, scores, rng, elite_frac=0.2):
mu, sigma = state
k = max(1, int(len(scores) * elite_frac))
elite = samples[np.argsort(scores)[:k]]
return elite.mean(axis=0), elite.std(axis=0) + 1e-6
# --- SA: 近傍から n_samples 個の提案を作り、逐次 Metropolis 受理 ---
def sa_sampler(state, n, rng, step=0.6):
x, fx, T = state
return x + rng.normal(0, step, size=(n, x.shape[0]))
def sa_updater(state, samples, scores, rng, cooling=0.93):
x, fx, T = state
for x_prop, f_prop in zip(samples, scores):
if f_prop < fx or rng.random() < np.exp(-(f_prop - fx) / T):
x, fx = x_prop, f_prop
return x, fx, T * cooling
# --- GA: トーナメント選択 + 一様交叉 + 突然変異、エリート保存1個体 ---
def ga_sampler(state, n, rng):
return state # 現世代そのものを評価対象にする
def ga_updater(state, samples, scores, rng, mutation_rate=0.2, mutation_scale=0.5, k=3):
pop = samples
n, d = pop.shape
new_pop = np.empty_like(pop)
for i in range(n):
idx1 = rng.integers(0, n, size=k)
p1 = pop[idx1[np.argmin(scores[idx1])]]
idx2 = rng.integers(0, n, size=k)
p2 = pop[idx2[np.argmin(scores[idx2])]]
# 一様交叉(遺伝子ごとにどちらかの親をコピー。blend交叉は分散が縮小し
# 多峰性関数で早期収束しやすいため、離散的な遺伝継承を採用)
cross_mask = rng.random(d) < 0.5
child = np.where(cross_mask, p1, p2)
mask = rng.random(d) < mutation_rate
child = np.where(mask, child + rng.normal(0, mutation_scale, d), child)
new_pop[i] = child
new_pop[0] = pop[scores.argmin()] # エリート保存
return new_pop
# --- MPPI: 静的最適化への単純化版(軌道=パラメータそのもの) ---
def mppi_sampler(state, n, rng):
u, sigma, lam = state
return u + rng.normal(0, sigma, size=(n, u.shape[0]))
def mppi_updater(state, samples, scores, rng, lam=1.0):
u, sigma, _ = state
w = np.exp(-(scores - scores.min()) / lam)
w /= w.sum()
return (w[:, None] * samples).sum(axis=0), sigma, lam
# --- PSO: 慣性 + 認知 + 社会項による速度更新 ---
def pso_sampler(state, n, rng):
x, v, pbest, pbest_val, gbest = state
return x
def pso_updater(state, samples, scores, rng, w=0.7, c1=1.5, c2=1.5):
x, v, pbest, pbest_val, gbest = state
improved = scores < pbest_val
pbest = np.where(improved[:, None], x, pbest)
pbest_val = np.where(improved, scores, pbest_val)
gbest = pbest[pbest_val.argmin()]
r1, r2 = rng.random(x.shape), rng.random(x.shape)
v = w * v + c1 * r1 * (pbest - x) + c2 * r2 * (gbest - x)
return x + v, v, pbest, pbest_val, gbest
# --- 初期状態を共通の予算・開始点でそろえる ---
n_iter, n_samples = 40, 200
init_rng = np.random.default_rng(1) # 初期集団生成専用
cem_init = (x0.copy(), np.ones(dim) * 2.0)
sa_init = (x0.copy(), rastrigin(x0), 10.0)
ga_init = x0 + init_rng.normal(0, 2.0, size=(n_samples, dim))
mppi_init = (x0.copy(), np.ones(dim) * 1.5, 1.0)
pso_x0 = x0 + init_rng.normal(0, 2.0, size=(n_samples, dim))
pso_v0 = np.zeros((n_samples, dim))
pso_pbest_val0 = np.array([rastrigin(xx) for xx in pso_x0])
pso_init = (pso_x0, pso_v0, pso_x0.copy(), pso_pbest_val0, pso_x0[pso_pbest_val0.argmin()])
methods = {
"CEM": (cem_sampler, cem_updater, cem_init),
"SA": (sa_sampler, sa_updater, sa_init),
"GA": (ga_sampler, ga_updater, ga_init),
"MPPI": (mppi_sampler, mppi_updater, mppi_init),
"PSO": (pso_sampler, pso_updater, pso_init),
}
results = {}
for name, (sampler, updater, init_state) in methods.items():
_, hist = monte_carlo_optimize(rastrigin, sampler, updater, init_state, n_iter, n_samples, seed=0)
results[name] = hist
print(f"{name:5s}: best@iter40 = {hist[-1]:.4f}")
実行結果(延べ8,000回評価後の最良値):
CEM : best@iter40 = 6.9648
SA : best@iter40 = 10.1668
GA : best@iter40 = 0.5372
MPPI : best@iter40 = 9.9631
PSO : best@iter40 = 3.0682
反復ごとの推移(best-so-far, 一部抜粋)は次の通りでした。
| 反復 | CEM | SA | GA | MPPI | PSO |
|---|---|---|---|---|---|
| 1 | 152.349 | 209.001 | 154.611 | 179.681 | 112.106 |
| 10 | 22.288 | 64.987 | 31.839 | 20.705 | 16.200 |
| 20 | 8.956 | 20.850 | 7.636 | 9.963 | 6.351 |
| 30 | 7.030 | 10.167 | 3.042 | 9.963 | 4.654 |
| 40 | 6.965 | 10.167 | 0.537 | 9.963 | 3.068 |
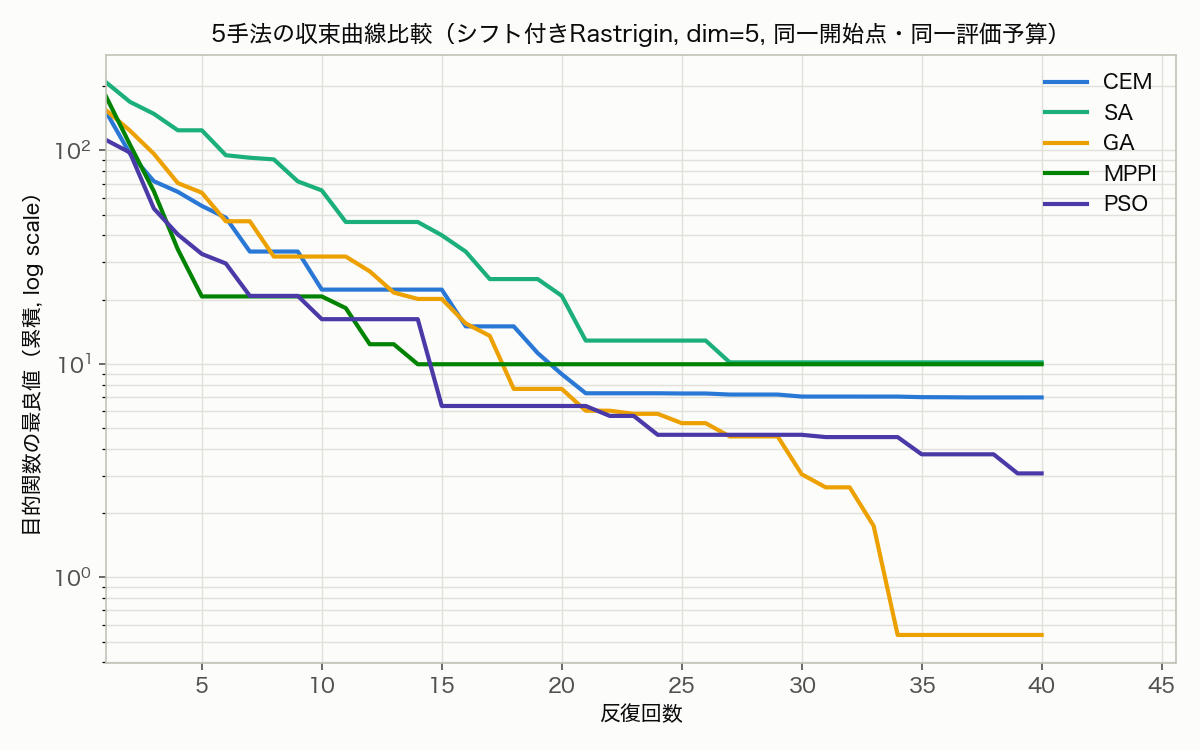
図から読み取れる特徴は以下の通りです。
- GA が最終的に最も低い値(0.537)に到達: 一様交叉によって集団の多様性が保たれ、34反復目に大きく値を下げる「跳躍」が発生しています。これは変異によって別の谷(cosineの周期構造上の別の極小)へ脱出できたことを示唆します
- MPPI と SA は序盤で停滞: MPPI は反復15付近で重み付き平均が一つの谷に収束すると、固定の探索幅
sigma=1.5のままではそこから抜け出せず 9.96 で頭打ちになっています。SA も同様に、温度スケジュールがcooling=0.93と比較的急なため反復20を過ぎると探索的な悪化遷移をほぼ受理しなくなり、停滞しています - CEM と PSO は着実に減少するが最終値では GA に劣後: 両手法とも分布/粒子群が一つの谷に収束していく過程で、局所的な精緻化は進むものの多峰性の脱出には至っていません
注意(このベンチマークの限界): これは各手法の「デフォルト的なハイパーパラメータ」での挙動を比較したものであり、厳密な性能ベンチマークではありません。CEM の elite_frac、SA の冷却スケジュール、MPPI の sigma、PSO の w, c1, c2 はいずれも個別にチューニングすれば大きく改善します(各手法の詳細なハイパーパラメータ感度は、下記の深堀り記事でそれぞれ検証済みです)。ここで実際に確認できたのは、「サンプリング→評価→更新」という共通ループが5手法すべてに対して過不足なく機能するという、本記事の主張そのものです。
各手法の深堀り誘導
CEM(クロスエントロピー法)
KL ダイバージェンス最小化に基づき、エリートサンプルから次の分布を最尤推定します。実装が非常にシンプルで、強化学習の方策パラメータ探索でも使われます。
詳細: クロスエントロピー法:モンテカルロ最適化の実践的手法
SA(焼きなまし法)
温度 \(T\) を徐々に下げながら、悪化方向への遷移を Boltzmann 確率 \(\exp(-\Delta f / T)\) で確率的に受理します。組合せ問題や TSP で長年標準的に使われてきた手法です。
詳細: 焼きなまし法(Simulated Annealing)の仕組みとPython実装
GA(遺伝的アルゴリズム)
個体集団を選択・交叉・突然変異で進化させます。離散・連続のいずれにも対応し、構造設計やパス計画など多様な分野で使われます。
MPPI(Model Predictive Path Integral)
制御入力列を確率分布として表し、コストの指数重み付け平均で名目軌道を更新します。CEM の連続時間・連続制御版とみなせ、ロボティクスのリアルタイム MPC で標準化が進んでいます。
詳細: MPPI(Model Predictive Path Integral)の数理
PSO(粒子群最適化)
粒子群の速度を「慣性 + 個体ベスト方向 + 大域ベスト方向」で更新します。実装が直感的で、ハイパーパラメータが少ないため広く使われます。
ベイズ最適化
評価コストが高い目的関数に対し、ガウス過程でサロゲートを構築し、獲得関数で次の評価点を選択します。サンプル数が少ない局面で他のモンテカルロ系を凌駕します。
パーティクルフィルタ(兄弟手法)
最適化ではなく状態推定の手法ですが、リサンプリング機構は CEM のエリート選択や MPPI の重み付けと数学的に等価で、モンテカルロ系の 元祖 にあたります。
詳細: 粒子フィルタのPython実装
使い分けの指針
実問題でどの手法を選ぶかは、以下の観点で判断するのが実用的です。
| 状況 | 推奨手法 | 理由 |
|---|---|---|
| 目的関数評価が 超高コスト(数分以上) | ベイズ最適化 | サンプル効率が桁違いに良い |
| 連続最適化、低〜中次元(〜数十次元) | CEM, PSO | 実装シンプル、収束が速い |
| 連続最適化、高次元(数百次元以上) | CEM, MPPI | 分布パラメトリック化で次元の呪いを緩和 |
| 組合せ最適化、TSP、スケジューリング | SA, GA | 離散近傍/個体表現が自然 |
| リアルタイム制御、ロボティクス | MPPI | GPU で全サンプル並列、毎時刻 100Hz 以上で更新可能 |
| 多峰性が強い、大域解が必須 | GA, CEM(多モード化) | 集団による多様性維持 |
| 微分情報が一部使える | 勾配法とのハイブリッド | モンテカルロで初期化 → 勾配法で精緻化 |
簡易フローチャート
目的関数の評価コストは?
├─ 超高コスト ──> ベイズ最適化
└─ 中〜低コスト
│
解は連続 or 離散?
├─ 離散 ──> SA / GA
└─ 連続
│
リアルタイム性が必要?
├─ Yes ──> MPPI
└─ No
│
個体ベストの履歴情報を活かしたい?
├─ Yes ──> PSO
└─ No ──> CEM
このチャートはあくまで第一近似で、実問題ではハイブリッド化(例: CEM で粗く探索した後 GA で多様性を担保)が有効なケースも多くあります。
最新の研究動向
「共通骨格として統一的に理解する」というアプローチ自体が近年の研究テーマになっています。
- Zhao, Q., Duan, Q., Yan, B., Cheng, S., & Shi, Y. (2023). Automated Design of Metaheuristic Algorithms: A Survey . arXiv:2303.06532(2024年2月改訂版あり)。GA・SA・PSO などのメタヒューリスティクスを個別技法としてではなく、共通の「設計空間(design space)」の中のインスタンスとして捉え、そのハイパーパラメータやオペレータ選択を自動探索する手法群を整理したサーベイです。本記事の「更新オペレータ \(\mathcal{U}\) が手法ごとに異なるだけ」という立場を、アルゴリズム設計論の観点から裏付けています。前節の実行検証で見た「各手法のデフォルト設定では性能差が大きい」という結果は、まさにこの自動設計・自動チューニングが解決を試みている問題そのものです
- Poyrazoglu, O. G., Cao, Y., Moorthy, R., & Isler, V. (2026). Uncertainty Guided Exploratory Trajectory Optimization for Sampling-Based Model Predictive Control. arXiv:2604.12149。MPPI 系のサンプリングベース MPC が抱える「初期化・探索範囲への感度」の問題に対し、軌道を不確実性楕円体を持つ確率分布として表現し、Hellinger距離でサンプル間の分離を保証することでサンプルの被覆性を高める手法(UGE-MPC)を提案しています。障害物のない環境で従来手法比72.1%の収束高速化を報告しており、前節で観測した「MPPI が反復15付近で単一の谷に収束し停滞する」という挙動(固定分散のサンプリングによる探索の早期崩壊)に対する具体的な改善策になっています
信号処理との接点
モンテカルロ最適化は信号処理にも応用が広がっています。
- 適応フィルタの非凸目的関数: 通常の LMS/RLS が極小に陥る状況で、CEM や GA を初期化に使う
- フィルタ係数の構造最適化: 整数係数の FIR フィルタ設計(量子化制約あり)に SA / GA
- モデル予測制御の制御列最適化: 信号系制御では MPPI が標準化しつつある
- 状態推定: 非線形・非ガウス系では パーティクルフィルタ が線形フィルタ(カルマン)を凌駕
特に MPPI は、伝統的な LQR / MPC では扱えない 微分不可能なコスト(衝突回避、二値制約など)を素直に扱える点で、信号処理 + 制御の融合領域で急速に普及しています。
まとめ
- モンテカルロ最適化は サンプリング → 評価 → 更新 の共通骨格を持つ
- CEM / SA / GA / MPPI / PSO は「更新オペレータ \(\mathcal{U}\) 」の違いとして統一的に理解できる
- Python では
samplerとupdaterを差し替えるだけのスケルトンで実装できる - 手法選択は 評価コスト → 連続/離散 → リアルタイム性 → 履歴活用度 の順で絞ると実用的
- ベイズ最適化やパーティクルフィルタも同じモンテカルロ系の枠組みに位置づけられる
各手法の詳細な数理と実装例は、以下の関連記事で深堀りしてください。
関連記事
- クロスエントロピー法:モンテカルロ最適化の実践的手法 - 重点サンプリングとエリート分位点に基づく分布更新を解説。
- 焼きなまし法(Simulated Annealing)の仕組みとPython実装 - 温度スケジュールと Boltzmann 受理確率の数理。
- 遺伝的アルゴリズム(GA)の基礎とPython実装 - 選択・交叉・突然変異による集団進化の仕組み。
- MPPI(Model Predictive Path Integral)の数理 - CEM との統一的理解と制御への適用。
- 粒子群最適化(PSO)の数理とPython実装 - 慣性重み・認知/社会係数による速度更新則。
- ベイズ最適化の基礎とPython実装 - ガウス過程サロゲートと獲得関数による評価点選択。
- 粒子フィルタのPython実装 - リサンプリングを通じてモンテカルロ系の元祖を学ぶ。
参考文献
- Rubinstein, R. Y., & Kroese, D. P. (2004). The Cross-Entropy Method. Springer.
- Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by Simulated Annealing. Science, 220(4598), 671–680.
- Holland, J. H. (1992). Adaptation in Natural and Artificial Systems. MIT Press.
- Williams, G., et al. (2017). Model Predictive Path Integral Control: From Theory to Parallel Computation. Journal of Guidance, Control, and Dynamics, 40(2).
- Kennedy, J., & Eberhart, R. (1995). Particle Swarm Optimization. Proc. IEEE ICNN.
- Shahriari, B., et al. (2016). Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE, 104(1).
- Zhao, Q., Duan, Q., Yan, B., Cheng, S., & Shi, Y. (2023). Automated Design of Metaheuristic Algorithms: A Survey. arXiv:2303.06532.
- Poyrazoglu, O. G., Cao, Y., Moorthy, R., & Isler, V. (2026). Uncertainty Guided Exploratory Trajectory Optimization for Sampling-Based Model Predictive Control. arXiv:2604.12149.
関連ツール
- DevToolBox - 開発者向け無料ツール集 - JSON整形、正規表現テスターなど85種類以上の開発者向けツール
- CalcBox - 暮らしの計算ツール - 統計計算、周波数変換など61種類以上の計算ツール