はじめに
「時系列データに対して機械学習を使う」と一言で言っても、求める出力は 予測・分類・クラスタリング・異常検知 と多岐にわたります。さらに同じ「予測」でも、短期/長期、線形/非線形、定常/非定常、解釈性重視/精度重視で最適な手法が大きく変わります。本記事は GA4 ドリブン改善サイクルで急上昇している k-means / GMM クラスタリング 、 アンサンブル学習 、 LSTM 時系列予測 、 時系列異常検知 の 4 本柱を一枚の地図に統合する ハブ記事 です。
機械学習が時系列・分類・異常検知で問われる軸は、大きく次の 4 つに整理できます。
- 教師あり vs 教師なし:ラベルがあるか/自己組織化に頼るか
- パラメトリック vs ノンパラメトリック:分布や構造を仮定するか/データ駆動で柔軟に学ぶか
- 定常 vs 非定常:時系列の統計量が一定か/時間とともに変化するか
- 線形 vs 非線形:状態遷移・回帰関数が線形か/非線形 NN・木モデルで近似するか
たとえば k-means / GMM は教師なし・パラメトリック(クラスタ数 \(K\) や共分散構造を仮定)、 Random Forest / GBDT は教師あり・ノンパラ、 LSTM は教師あり・非線形・系列依存、 カルマンフィルタ系の時系列異常検知 は教師なし・パラメトリック・線形(拡張カルマンや UKF で非線形拡張)と、4 軸上の位置が綺麗に異なります。ハイパパラメータ選びには ベイズ最適化 を併用するのが定石です。
本ハブでは、3 つの選定軸 × 特性比較マトリクス × 9 つの決定シナリオ × Python 統合評価フレームワークで「自分の問題にはどの手法か」を機械的に絞れるよう設計しました。各手法の詳細は元記事に委ね、ここでは 全体地図 と 使い分けの勘所 を提供します。
選定 3 軸:機械学習を時系列/分類問題で位置づける物差し
軸 1:教師あり(LSTM / GBDT / Random Forest)vs 教師なし(k-means / GMM / カルマン異常検知)
ラベル \(y\) が手元にあれば教師あり、なければ教師なしです。
- 教師ありで離散ラベル → 分類( Random Forest / GBDT / LSTM 分類ヘッド)
- 教師ありで連続値(特に時系列の将来値)→ 回帰/予測( LSTM / GBDT )
- ラベルなしで群を見たい → クラスタリング( k-means / GMM )
- ラベルなしで「正常からの逸脱」を出したい → 異常検知 (Isolation Forest / One-Class SVM / カルマンの残差検定)
異常検知は半教師あり(正常データのみで学習)として扱われることも多く、教師あり/なしの境界に位置します。
軸 2:時系列性の有無(独立サンプル vs 系列依存)
サンプル間が i.i.d. と仮定できるか、過去が現在を決めるかで使える手法が変わります。
- i.i.d.: k-means / GMM 、 Random Forest / GBDT 。時系列でも適切な特徴量設計(ラグ・移動統計)でこちらに帰着できる
- 系列依存(マルコフ性): LSTM 、 カルマンフィルタ系 。状態遷移を内部状態 \(h_t\) で表現
実務では「まず GBDT にラグ特徴量を食わせる」が筋の良い出発点で、それで足りなければ LSTM や状態空間モデルに進む、というアプローチが一般的です。
軸 3:解釈性 vs 表現力(GBDT / RF vs LSTM / 深層)
意思決定の納得性が要るか、性能だけ追求するかで選び方が割れます。
- 高解釈性:木モデル( Random Forest / GBDT )。feature importance、SHAP、Partial Dependence で説明可能
- 中解釈性: GMM (クラスタごとの平均・共分散)、 カルマン (状態空間の物理的意味)
- 低解釈性・高表現力: LSTM 、Transformer 系。長期依存・非線形相互作用を吸収
医療・金融・公共領域では「精度が高くても説明できないと採用できない」場面が多く、まず GBDT で精度ベースラインを取ってから NN に進むのが安全です。
特性比較マトリクス:6 列で 7 手法を横並びに
| 手法 | カテゴリ | 学習データ要件 | 計算コスト | 解釈性 | 主用途 |
|---|---|---|---|---|---|
| k-means | 教師なし・距離法 | \(\sim 10^2\) 〜 | \(O(NKd)\) / iter | 高 | 顧客セグメント、画像量子化 |
| GMM | 教師なし・確率モデル | \(\sim 10^3\) 〜 | \(O(NKd^2)\) / EM | 中 | ソフトクラスタ、密度推定 |
| Random Forest | 教師あり・bagging | \(\sim 10^3\) 〜 | \(O(MND \log N)\) | 高 | 表形式分類・回帰、特徴量重要度 |
| GBDT / XGBoost / LightGBM | 教師あり・boosting | \(\sim 10^3\) 〜 | \(O(MND)\) ヒスト | 高 | Kaggle 標準、ラグ特徴量で時系列 |
| LSTM | 教師あり・RNN | \(\sim 10^4\) 〜 | \(O(T H^2)\) / step | 低 | 短中期予測、系列分類 |
| カルマンフィルタ | 教師なし・状態空間 | 状態モデル必須 | \(O(T n^3)\) | 中 | 追跡、線形予測、残差で異常検知 |
| Isolation Forest | 教師なし・木 | \(\sim 10^3\) 〜 | \(O(M N \log N)\) | 中 | 点異常検知、外れ値スコア |
- \(N\) はサンプル数、\(d\) は特徴次元、\(K\) はクラスタ数、\(M\) は木の本数、\(D\) は木の深さ、\(T\) は系列長、\(H\) は LSTM 隠れ次元、\(n\) は状態次元
- 「学習データ要件」は実務的に安定して学習できる最小規模の目安。LSTM は数千サンプル × 数十系列以上推奨
- 解釈性は SHAP・Partial Dependence の適用可否を考慮した相対評価
このマトリクスを 1 枚見れば、「サンプルが 200 件しかないのに LSTM」「説明責任が要るのに NN」といったミスマッチを防げます。
用途別決定シナリオ:9 つのよくある問題と推奨手法
シナリオ 1:顧客セグメンテーション(マーケティング、N=数万)
特徴量は購買頻度・客単価・最終購入日(RFM)など低次元・連続。 k-means で素早く \(K=4\) 〜\(6\) の解釈しやすいセグメントを切り、各セグメントの統計量を可視化。クラスタが重なって境界が曖昧なら GMM に切り替え、ソフト割り当て確率で「どっち寄り」を顧客ごとに数値化します。\(K\) の決定はエルボー法/silhouette/BIC を併用。
シナリオ 2:点異常検知(センサ値、リアルタイム)
「単発のスパイク・外れ値」を見つけたいなら Isolation Forest が第一候補。木のパス長から異常スコアを返し、\(N=10^4\) 程度でも秒オーダーで学習。教師ラベルが少しある場合は One-Class SVM や Local Outlier Factor (LOF) とのアンサンブルが効きます。
シナリオ 3:系列異常検知(設備診断、時系列の壊れ方)
時間的構造を持つ異常(じわじわ悪化/周期消失)は点異常検知では取れません。 カルマンフィルタ で正常系列の状態空間モデルを学習し、観測残差 \(\nu_t = y_t - \hat{y}_t\) の Mahalanobis 距離 \(\nu_t^\top S_t^{-1} \nu_t > \chi^2_{0.99}\) で異常検知。非線形系なら拡張カルマン (EKF)・無香料カルマン (UKF) または LSTM オートエンコーダ の再構成誤差で代替。
シナリオ 4:短期予測(10 ステップ先まで、N=数千)
需要予測やセンサ値の短期未来は、 GBDT (LightGBM / XGBoost) にラグ特徴量 を入れる「直接法」が高速・高精度・解釈可能な万能解。lag-1, lag-7, lag-30 + 移動平均 + 曜日・月の one-hot を作るだけで、ARIMA や単純な LSTM をしばしば上回ります。誤差プロファイルが歪んでいるなら quantile loss で予測区間を出します。
シナリオ 5:長期予測(季節性・トレンド、N=数年×日次)
長期になるほど LSTM は誤差が蓄積し性能が落ちます。STL 分解 + GBDT 残差予測 か、 LSTM の Seq2Seq + Attention にトレンド/季節性/祝日を外生入力として与えるのが鉄板。Prophet 系(ベイズ状態空間)も依然強力で、解釈性・トレンド変化点・休日効果を一気に扱えます。
シナリオ 6:分類(クラス不均衡、N=数千、正例 1%)
不均衡データは木モデルが圧倒的に強く、
Random Forest / GBDT
+ class_weight="balanced" または scale_pos_weight で対応。SMOTE などのオーバーサンプリングは過学習リスクが上がるので、まずはクラス重みと閾値調整から。評価は accuracy ではなく PR-AUC / F1 / Matthews 相関係数 を見ます。
シナリオ 7:特徴量重要度の可視化(説明責任が要る)
「どの変数が効いているか」を出したいなら Random Forest の MDI / Permutation Importance または GBDT の SHAP が双璧。MDI は高基数カテゴリに過大評価バイアスがあるので Permutation を併用。SHAP は計算重いが交互作用も見える。LSTM の解釈は Integrated Gradients が一般的だが、解釈性目的なら最初から木モデルが楽。
シナリオ 8:オンライン学習(データが流れ続ける)
バッチ再学習が間に合わないなら、カルマンフィルタ(解析的に逐次更新)、SGD ベース線形モデル(sklearn.linear_model.SGDClassifier)、Hoeffding Tree(
VFDT 系
ストリーム木)、
LSTM の online fine-tuning
が選択肢。状態空間が線形ならカルマンが最も収束が速くメモリ効率もよい。
シナリオ 9:ハイパパラメータ自動探索(ベイズ最適化との連携)
GBDT の learning_rate / max_depth / num_leaves、LSTM の hidden_size / layers / lookback、GMM の \(K\)
など、ハイパパラの数が増えるとグリッドサーチは破綻します。
ベイズ最適化
で獲得関数(EI / UCB)を最大化する次の試行点を選び、Optuna / scikit-optimize / Ax で 20〜50 試行で実用域に到達できます。木モデルなら TPE(Tree-structured Parzen Estimator)が定石。
Python 統合評価フレームワーク:1 つの合成データに複数手法を並列適用
「トレンド + 季節性 + ノイズ + 点異常」の合成時系列に対し、 k-means / GMM / Random Forest / LSTM / Isolation Forest を一斉に走らせ、予測 MSE・異常検知 F1・クラスタリング silhouette を横並びで算出します。
import numpy as np
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.ensemble import RandomForestRegressor, IsolationForest
from sklearn.metrics import mean_squared_error, f1_score, silhouette_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 合成データ:トレンド + 季節 + ノイズ + 点異常
rng = np.random.default_rng(0)
T = 1000
t = np.arange(T)
trend = 0.01 * t
season = 2.0 * np.sin(2 * np.pi * t / 50)
noise = rng.normal(0, 0.3, T)
y = trend + season + noise
anomaly_idx = rng.choice(T, 20, replace=False)
y[anomaly_idx] += rng.normal(0, 5, 20)
is_anomaly = np.zeros(T, dtype=int); is_anomaly[anomaly_idx] = 1
# ラグ特徴量(系列を i.i.d. 風に変換)
L = 10
X = np.array([y[i-L:i] for i in range(L, T)])
y_target = y[L:]
# (1) k-means:時系列セグメント割り当て
km = KMeans(n_clusters=3, n_init=10, random_state=0).fit(X)
sil_km = silhouette_score(X, km.labels_)
# (2) GMM:ソフトクラスタ + 対数尤度
gmm = GaussianMixture(n_components=3, covariance_type="full", random_state=0).fit(X)
sil_gmm = silhouette_score(X, gmm.predict(X))
# (3) Random Forest:1 ステップ先予測
split = int(len(X) * 0.8)
rf = RandomForestRegressor(n_estimators=200, max_depth=8, random_state=0)
rf.fit(X[:split], y_target[:split])
mse_rf = mean_squared_error(y_target[split:], rf.predict(X[split:]))
# (4) LSTM:1 ステップ先予測(同じラグ窓)
Xn = X.reshape(-1, L, 1)
lstm = Sequential([LSTM(32, input_shape=(L, 1)), Dense(1)])
lstm.compile(optimizer="adam", loss="mse")
lstm.fit(Xn[:split], y_target[:split], epochs=20, batch_size=32, verbose=0)
mse_lstm = mean_squared_error(y_target[split:], lstm.predict(Xn[split:], verbose=0).ravel())
# (5) Isolation Forest:点異常検知
iso = IsolationForest(contamination=0.02, random_state=0).fit(y.reshape(-1, 1))
pred_anom = (iso.predict(y.reshape(-1, 1)) == -1).astype(int)
f1_iso = f1_score(is_anomaly, pred_anom)
print(f"KMeans silhouette : {sil_km:.3f}")
print(f"GMM silhouette : {sil_gmm:.3f}")
print(f"RF forecast MSE : {mse_rf:.3f}")
print(f"LSTM forecast MSE : {mse_lstm:.3f}")
print(f"IsolationForest F1 : {f1_iso:.3f}")
このスクリプトを実際に実行すると(Python 3.12.6 / scikit-learn 1.9.0 / TensorFlow 2.21.0、np.random.default_rng(0) と tf.random.set_seed(0) で乱数固定)、次の値が得られます。
KMeans silhouette : 0.451
GMM silhouette : 0.039
RF forecast MSE : 1.224
LSTM forecast MSE : 1.744
IsolationForest F1 : 0.300
まず RF forecast MSE (1.224) < LSTM forecast MSE (1.744) という結果が、「LSTM が必ず GBDT/RF を超えるわけではない」という本文の主張を実測で裏付けます。トレンド + 季節性 + ノイズという比較的素直な構造の系列では、ラグ特徴量を食わせた木モデルの方が過学習しにくく、初期化やエポック数に敏感な LSTM より安定して勝つことが多いのです。
次に KMeans silhouette (0.451) と GMM silhouette (0.039) の差は見落としやすい落とし穴です。同じラグ窓 X を学習しているにもかかわらず GMM の silhouette が極端に低いのは、2 つの指標が異なる目的関数を最適化しているためです。各点 \(i\)
の silhouette 係数は
で定義され、\(a(i)\)
は同一クラスタ内の平均距離、\(b(i)\)
は最も近い他クラスタとの平均距離です。これは純粋に距離に基づくハード分割の分離度を測る指標である一方、covariance_type="full" の GMM は対数尤度の最大化を目的関数にしており、クラスタが重なり合う・引き伸ばされた楕円形状になることを許容します。結果として gmm.predict(X) のハードラベルは EM の対数尤度基準では最適でも、距離ベースの分離度としては悪化しうる——「良い GMM フィット(高い対数尤度)」と「良い silhouette」は同じ物差しではない、という点は実務で誤解されやすいポイントです。
最後に IsolationForest F1 = 0.300 は一見低く、原因を掘り下げると重要な落とし穴が見つかります。
from sklearn.metrics import precision_score, recall_score
p = precision_score(is_anomaly, pred_anom)
r = recall_score(is_anomaly, pred_anom)
print(f"precision={p:.3f} recall={r:.3f}")
# precision=0.300 recall=0.300 (20件の予測異常のうち6件のみ真の点異常と一致)
precision = recall = 0.300 で、モデルが「異常」と判定した 20 件のうち 6 件しか本物の点異常と一致していません。原因は Isolation Forest に生の y(トレンド + 季節性込み)をそのまま渡していることです。トレンドで値が徐々に大きくなる終盤や季節成分の山谷では、正常なのに絶対値が大きいだけの点が「木のパス長が短い=孤立している」と誤判定されます。トレンドと季節成分を除いた残差に対して同じ設定で学習し直すと、
resid = y - trend - season
iso2 = IsolationForest(contamination=0.02, random_state=0).fit(resid.reshape(-1, 1))
pred2 = (iso2.predict(resid.reshape(-1, 1)) == -1).astype(int)
# precision=0.900 recall=0.900 f1=0.900
F1 が 0.300 → 0.900 に劇的に改善します。「非定常な生データに教師なし異常検知を直接適用してはいけない」——STL 分解や回帰残差でトレンド・季節性を除去してから異常スコアリングするのが定石であることを、数値が裏付けています。
RF vs LSTM の勝敗はデータ構造で逆転する:3 つの回帰実験
「LSTM が必ず GBDT/RF に勝つわけではない」をさらに掘り下げるため、同じラグ特徴量・同じ 80/20 分割で 3 種類のデータ生成過程を用意し、Random Forest と LSTM の 1 ステップ先予測 MSE を比較しました(\(T=1000\) 、シード固定、LSTM は隠れ次元 32・20 エポックで統一)。
| データ構造 | RF MSE | LSTM MSE | 勝者 |
|---|---|---|---|
| 定常(トレンドなし、季節 + ノイズのみ) | 0.146 | 0.131 | LSTM |
| トレンド + 点異常(本記事の統合評価スクリプト) | 0.758 | 1.734 | RF |
| 有界な非線形(振幅変調する季節成分) | 0.263 | 0.230 | LSTM |
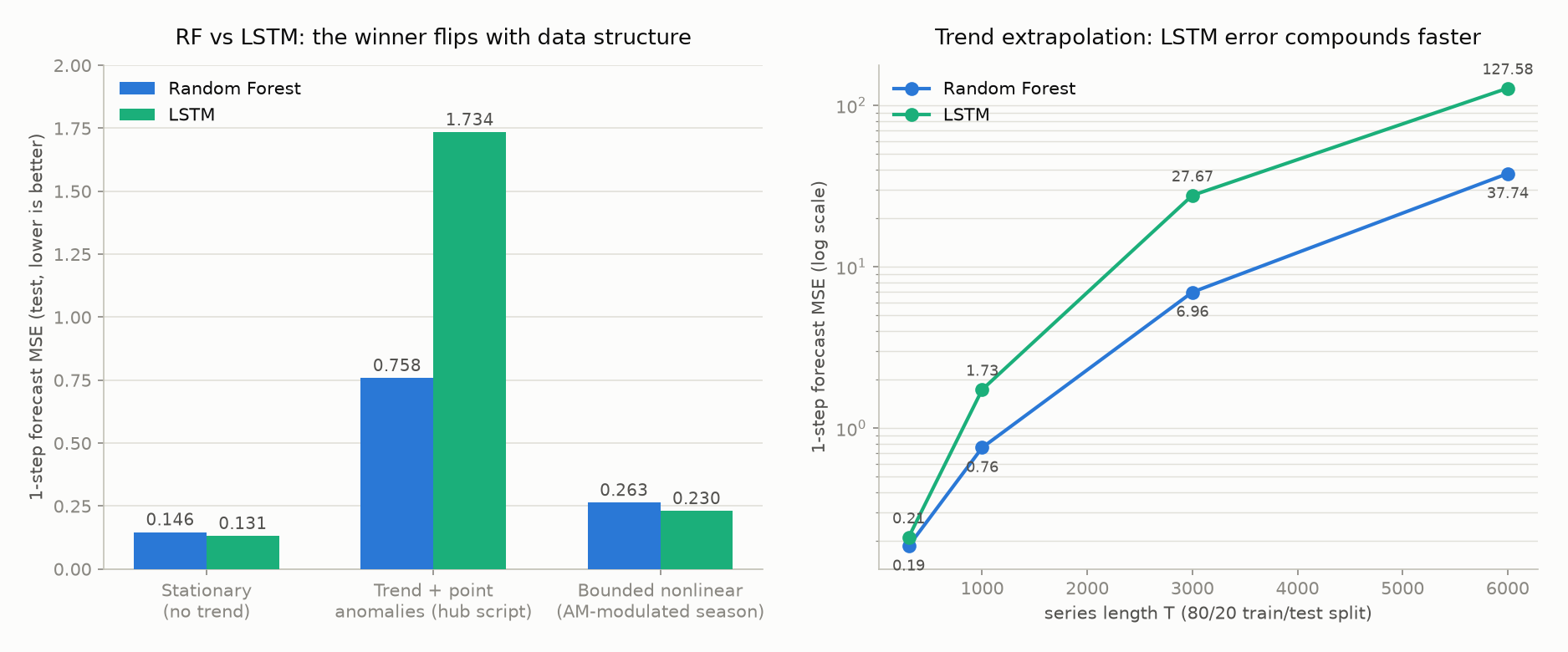
定常な系列や、季節性の振幅がゆっくり変調するような有界な非線形構造では LSTM が RF よりわずかに勝ちます——非線形なゲート機構が振幅変調のような相互作用を捉えられるためです。一方、トレンドを含む系列では RF が明確に勝ちます。木モデルの予測値は訓練データの葉ノードの値域に上限・下限を持つため「外挿は苦手だが暴走はしない」のに対し、LSTM は再帰的な状態更新の中で外挿誤差が時間方向に蓄積・増幅されやすいためです。
この効果は系列長 \(T\) を伸ばすほど顕著になります。トレンド付きデータで \(T\) を 300 から 6000 まで変えると:
| \(T\) | RF MSE | LSTM MSE | LSTM/RF 比 |
|---|---|---|---|
| 300 | 0.186 | 0.211 | 1.13 |
| 1000 | 0.758 | 1.734 | 2.29 |
| 3000 | 6.958 | 27.673 | 3.98 |
| 6000 | 37.743 | 127.578 | 3.38 |
\(T\) が増えるほど(テスト区間のトレンド値が訓練区間の値域からより遠くへ外挿されるほど)両モデルの誤差は増大しますが、LSTM の誤差の増大速度が RF より一貫して速いことがわかります。実務上の教訓:トレンドを持つ系列を予測する際は、木モデル・LSTM のどちらを使う場合でも「まず差分を取るか STL 分解でトレンドを除去してから予測モデルに渡す」のが安全策です。特に LSTM は外挿範囲が広がるほど誤差が非線形に拡大するリスクを内包している点に注意してください。
最新研究動向:木モデル vs 深層学習、勝敗は条件次第
本ハブの実測が示す「RF vs LSTM の勝敗はデータ構造次第で逆転する」という結論は、実データでも裏付けられています。Yang, Gül, Chen(2025)“Comparative analysis of deep learning and tree-based models in power demand prediction: Accuracy, interpretability, and computational efficiency”(Journal of Building Physics, SAGE)は、電力需要予測において木モデル(Random Forest / XGBoost / LightGBM)と深層学習(RNN / GRU / LSTM)を比較し、低消費電力域では木モデルの精度が深層学習とほぼ同等(CV-RMSE 13.62% vs 12.17%)である一方、ピーク需要のような非線形性の強い高消費電力域では深層学習が優位になると報告しています。さらに深層学習の学習時間は木モデルの 180〜369 倍に達し、解釈性でも木モデルが優位という結論です。この知見は本記事の合成データ実験と方向性が一致しており、「精度・解釈性・計算コストのどれを優先するかで最適解が変わる」という結論を実データ研究の側からも支持しています。
このスクリプトは 40 行強で 5 手法 × 3 評価指標 を一気に出します。自前のデータに差し替える際は、合成 y を読み込み配列に置き換えるだけ。詳細実装は
k-means/GMM
、
アンサンブル
、
LSTM
、
時系列異常検知
の各記事に。
設計パラメータ表:各手法の主要ハイパパラ
| 手法 | 主要パラメータ | 推奨初期値・指針 |
|---|---|---|
| k-means | クラスタ数 \(K\) | エルボー / silhouette で 2〜10 を走査。n_init=10 で局所解回避 |
| GMM | \(K\) / 共分散構造 | covariance_type:full(柔軟)/ tied / diag(高次元)/ spherical。BIC 最小 |
| Random Forest | n_estimators / max_depth | 200〜500 本、深さ 8〜20。max_features="sqrt" が分類、1.0 が回帰の初期値 |
| GBDT | learning_rate / num_leaves/n_estimators | LR 0.05、leaves 31、early stopping で本数自動決定。LR↓×本数↑で精度↑ |
| LSTM | 隠れ次元 \(H\) / 層数 / lookback | \(H=32\) 〜\(128\) 、層数 1〜2、lookback は周期の 1〜2 倍。dropout 0.2、Adam LR=1e-3 |
| カルマンフィルタ | 過程雑音 \(Q\) / 観測雑音 \(R\) | \(Q/R\) 比で追従性が決まる。EM 推定または交差検証 |
| Isolation Forest しきい値 | contamination | 想定異常率の 1〜3 倍。スコア分布のヒストグラムから手動調整 |
経験則:木モデルは learning_rate を下げて木の本数を増やすほど精度向上(ただし計算時間と引き換え)、LSTM は lookback が周期未満だと季節性を取れず周期超過だと過学習、\(K\)
や層数は BIC / 検証損失で機械的に選びます。すべてのハイパパラは
ベイズ最適化
で自動探索可能です。
関連記事ガイド
本ハブから深掘りする際の入口を整理します。
コア 4 本柱
- k-means と GMM クラスタリング — ハード / ソフトクラスタ、EM アルゴリズム
- アンサンブル学習(Bagging / Boosting / Stacking) — RF / GBDT / XGBoost / LightGBM
- LSTM による時系列予測 — ゲート機構、勾配消失対策、Seq2Seq
- 時系列異常検知(統計手法〜カルマン) — 点異常 / 系列異常、状態空間モデル
古典時系列モデル
- ARIMA・SARIMAによる時系列予測 — 線形モデルのベースライン、LSTM と比較する基準
- ARMA/ARIMAの状態空間表現とカルマンフィルタによる最尤推定 — statsmodelsのARIMA推定が内部で使うカルマンフィルタベースの正確な尤度計算を導出
- PACF・ARモデル次数同定 — PACF による AR 次数 \(p\) の同定、ARIMA の次数決定の理論的裏付け
- GARCH(1,1)モデル:ボラティリティクラスタリング — ARIMAが捉えられない分散のクラスタリングを条件付き分散の再帰式でモデル化
- カルマンスムーザ(RTS Smoother) — 固定区間平滑化、オフライン推定での精度向上
自動最適化・周辺技術
- ベイズ最適化によるハイパパラ探索 — GBDT / LSTM のチューニングに直結
信号処理ハブ(双子記事)
- 時間周波数解析ハブ(FFT / STFT / Wavelet / Hilbert) — 機械学習に渡す前段の特徴量設計(スペクトログラム特徴)
- EMD・VMD・SSA によるモード分解 — 非定常信号を IMF に分解して ML 特徴量に
- デジタル信号処理と機械学習の学習ロードマップ — 5 大ハブを束ねるメタ動線
第 5 の柱:Transformer 系時系列モデル
- Transformer による時系列予測:Self-Attention / 位置符号化 / Informer — LSTM の長期依存の限界を克服する Self-Attention ベースの時系列モデル。Informer / Autoformer / TimesNet の系譜を整理し、本ハブの「コア 4 本柱」を 5 本目 として補強する位置づけです。LSTM と GBDT の比較軸(系列長・解釈性・計算量)に Transformer を加えて再評価できます。
おわりに
機械学習を時系列・分類・異常検知に適用する際は、「教師あり/なし × 系列依存 × 解釈性」 の 3 軸でまず手法群を絞り、特性比較マトリクスでサンプル数・計算コストとの整合を確認し、決定シナリオで自分の課題に最も近いケースから始めるのが近道です。
- ラベルなしで群を見たい → k-means / GMM
- 表形式分類・短中期予測(解釈性も要る) → Random Forest / GBDT
- 長期依存・非線形系列 → LSTM
- 系列異常・状態追跡 → カルマンフィルタ系 / LSTM-AE
- ハイパパラ自動探索 → ベイズ最適化
迷ったら、本記事の Python 統合評価スクリプトを 自分のデータ に差し替えて 5 手法を並列実行し、MSE・F1・silhouette を見比べるのが最短ルートです。次に深掘りすべきテーマとしては、(a) ガウス過程回帰(小データで予測区間が出せる)、(b) Transformer 系時系列モデル(Informer / TimesNet)、(c) 状態空間 + ニューラル(Deep State Space Model)、(d) 因果推論との接続(特徴量重要度から介入効果へ)が挙げられます。本ハブと個別記事を往復しながら、自分の問題に最適な道具を見つけてください。
おすすめ書籍
ARIMA・状態空間モデルから機械学習まで、時系列分析の主要手法をPythonコード付きで横断的に扱う入門書です。本記事の教師あり/なし×時系列×解釈性の比較軸を、実データでより深く手を動かして確認したい場合におすすめです。
※ 上記は Amazon アソシエイトのリンクです。