なぜ Transformer を時系列に使うのか
時系列予測の主役は長らく ARIMA / SARIMA のような線形状態空間モデルと LSTM でしたが、2017 年の “Attention Is All You Need” 以降、自然言語処理から波及した Transformer が時系列領域でも急速に存在感を増しています。本記事は ML時系列ハブ の自然な深掘りとして、Attention の数学・Positional Encoding・PyTorch 最小実装・Informer/Autoformer/PatchTST まで一気通貫で扱います。
LSTM や カルマンフィルタ系の状態空間モデル は、内部状態 \(h_t\) を時刻順に逐次更新する 逐次計算 が本質です。これは長距離依存(数百ステップ離れた相関)を扱うほど勾配が薄まり、かつ GPU 並列化が効きません。Transformer は以下の 3 点で根本的に異なります:
- Self-Attention で全時刻ペアを一括計算 — 任意の時刻 \(i, j\) の相関を \(O(1)\) ステップで参照
- 完全並列 — 系列長 \(T\) の依存連鎖がなく、\(T\) 個のトークンを同時に処理
- 長距離依存に強い — 経路長が距離に依らず一定(LSTM は \(O(T)\) )
代償は計算量で、Self-Attention は系列長に対して \(O(T^2 d)\) (\(d\) は埋め込み次元)。これが Informer / Autoformer のような疎化バリアントが生まれた理由です。本記事では、まず基礎の Attention 機構と Positional Encoding を数式で押さえ、その後 PyTorch で最小実装し、最後に時系列専用 Transformer の系譜と ARIMA / LSTM との実務比較を行います。
Attention 機構の数学(要点)
Self-Attention の数式導出そのもの — Query/Key/Value の意味、\(\sqrt{d_k}\)
スケーリングが分散を1に正規化する導出、Multi-Head の定式化、NumPy スクラッチ実装と PyTorch nn.MultiheadAttention の数値一致検証(最大誤差 \(10^{-9}\)
オーダー)まで — は
Pythonで理解するSelf-Attentionの仕組み
で厳密に扱っています。本記事ではその結果だけ再掲し、紙面は時系列に固有の話題(Positional Encoding の周期設計、Causal Mask の証明、Informer/Autoformer/PatchTST、実測比較)に割きます。
ここで
\( W_Q, W_K \in \mathbb{R}^{d_{\text{model}} \times d_k}, \quad W_V \in \mathbb{R}^{d_{\text{model}} \times d_v} \)
は学習可能な重み。ヘッドごとに異なる「視点」(短期相関を捉えるヘッド、季節性を捉えるヘッドなど)を学習でき、 アンサンブル学習 と似た多様性の恩恵を受けます。本記事の後半では、実際に学習したモデルのヘッドが何に注目しているかを実データで可視化します。
Positional Encoding:順序情報の注入
Self-Attention は順序を持たない集合演算なので、そのままだと時刻 \(t\) の情報を区別できません。これを補うのが Positional Encoding (PE) です。
sin / cos 固定 PE(オリジナル Transformer)
位置 \(\text{pos}\) 、次元 \(i\) について:
\[ \begin{aligned} \mathrm{PE}_{(\text{pos}, 2i)} &= \sin\!\left(\frac{\text{pos}}{10000^{2i/d_{\text{model}}}}\right) \\ \mathrm{PE}_{(\text{pos}, 2i+1)} &= \cos\!\left(\frac{\text{pos}}{10000^{2i/d_{\text{model}}}}\right) \end{aligned} \tag{4} \]各次元が異なる波長の正弦波になっており、波長は \(2\pi\) から \(10000 \cdot 2\pi\) までの幾何級数。任意のオフセット \(k\) に対して \(\mathrm{PE}_{\text{pos}+k}\) を \(\mathrm{PE}_{\text{pos}}\) の線形変換で書けるため、相対位置の表現 が自然に学習可能です。フーリエ的な観点は 時間周波数解析ハブ や 離散DSP基礎 と接続します。
学習可能 PE と相対位置 PE
- 学習可能 PE:
nn.Embedding(max_len, d_model)で位置ごとにベクトルを学習。BERT / GPT 系の主流。固定 PE より柔軟だが長系列に外挿しにくい - 相対位置 PE(T5, Transformer-XL):Query/Key 間の相対距離 \(i - j\) にバイアスを加える。時系列のように「絶対時刻よりラグが重要」な場面で有利
- RoPE(Rotary PE):複素回転を埋め込みに掛ける。LLaMA / PatchTST 系で採用
時系列では 季節周期に合わせた sin/cos PE や 時間特徴量(曜日・月・祝日)を別チャネルで連結 する設計が安定します。これは STL 分解 + GBDT 残差 の発想に近い特徴量設計です。
時系列固有の工夫
Causal Mask / Look-ahead Mask
時系列予測では「未来の情報を見てはいけない」制約があります。Decoder(または autoregressive Encoder)で Self-Attention を計算する際、上三角行列をマスクして Softmax の前に \(-\infty\) を代入します:
\[ \mathrm{Mask}_{ij} = \begin{cases} 0 & \text{if } j \le i \\ -\infty & \text{if } j > i \end{cases} \tag{5} \]これが Causal mask(look-ahead mask)。一括並列計算しつつ自己回帰の因果性を守る仕組みで、PyTorch では torch.nn.Transformer.generate_square_subsequent_mask(T) で 1 行生成できます。
なぜこれで因果性が「近似」ではなく「厳密に」保証されるかを式で確認します。 マスクを加えた後の Softmax は
\[ A_{ij} = \frac{\exp\!\left(S_{ij} + \mathrm{Mask}_{ij}\right)}{\sum_{k} \exp\!\left(S_{ik} + \mathrm{Mask}_{ik}\right)}, \qquad S_{ij} = \frac{(QK^\top)_{ij}}{\sqrt{d_k}} \tag{6} \]\(j > i\) (未来)では \(\mathrm{Mask}_{ij} = -\infty\) なので \(\exp(S_{ij} - \infty) = 0\) 。つまり分子がちょうど 0 になり、\(Q, K\) がどんな値であっても未来の Key は分母の正規化定数にも分子にも一切寄与しません。したがって出力
\( \sum_{j} A_{ij} V_j \)
は \(j \le i\) の Value だけの凸結合になることが式から直接示されます——学習で自然に未来を無視するようになる、のではなく、アーキテクチャレベルで未来からの情報流入経路が存在しないことが保証されます。
実務上の注意点:
- 浮動小数点で
-infをそのまま使うと、ある行(ある Query)に対して有効な Key が 1 つもない場合(後述のパディングと組み合わさったとき等)に分子・分母がともに 0 になり0/0 = NaNが発生します。PyTorch の実装は数値的に安定化されていますが、自前実装では-infの代わりに-1e9程度の大きな負値を使う、あるいは全行マスクを禁止するといった対策が必要です - Padding mask(系列長を揃えるためのダミートークン)と Causal mask を同時に使う場合、両方の
-infを 加算 してから 1 回だけ Softmax する必要があります。別々に適用すると正規化定数がずれて重みの合計が1になりません - 本記事の最小実装(次節)は「過去 \(L\) ステップ全部を見て 1 ステップ先だけを予測する」設計で、窓の中で未来を覗く心配がそもそもないため Causal mask は不要です。Causal mask が必須になるのは、(a) Decoder が複数ステップを自己回帰的に生成する場合、(b) 1つの Encoder に過去と未来を両方含む系列を入力し、学習時に未来のトークンでの予測を同時に監督する場合、の2パターンです。この区別を誤ると「マスクをかけ忘れて情報漏洩(未来を見て予測しているだけの偽の高精度)」または「不要なマスクで学習を妨げる」のどちらかの典型的なバグに陥ります
Encoder-Decoder 構造
- Encoder のみ:BERT 型。系列分類・回帰ヘッドを乗せて LSTM 分類 の代替。 時系列異常検知 で再構成型に使うと有力
- Decoder のみ:GPT 型。自己回帰的に次トークンを生成。長期予測で誤差蓄積に注意
- Encoder-Decoder:過去の入力系列を Encoder で圧縮、Decoder で未来を生成。Seq2Seq 予測の王道
Informer / Autoformer / PatchTST 簡介
オリジナル Transformer の \(O(T^2)\) ボトルネックを時系列向けに改良したのが以下:
| モデル | 主アイディア | 計算量 | 強み |
|---|---|---|---|
| Informer | ProbSparse Attention(重要 Query のみ計算)+ 蒸留 | \(O(T \log T)\) | 長系列予測(数千ステップ先) |
| Autoformer | Series Decomposition( STL 風トレンド/季節分離 )+ Auto-Correlation Attention | \(O(T \log T)\) | 強い季節性データ |
| FEDformer | 周波数領域での疎 Attention( FFT/Wavelet 系の発想) | \(O(T)\) | 周期成分支配の系列 |
| PatchTST | 系列をパッチ化(Vision Transformer 風)+ Channel-Independent | \(O((T/P)^2)\) | 多変量時系列、最近の SOTA 常連 |
| TimesNet | 1D → 2D 変換(周期で折り畳む)+ Inception Block | \(O(T \log T)\) | 多周期・多周波数の同時モデル |
「まず PatchTST、長系列なら Informer、強い季節性なら Autoformer」がざっくりした使い分け。詳細は ML時系列ハブ の Foundation Model 節で扱う Lag-Llama / Chronos / TimesFM へと続きます。
最新研究動向(2023年以降):上表のモデルはいずれも「時間方向のトークン化」を前提にしていますが、Liu ら(2024, ICLR Spotlight採択)の iTransformer(“Inverted Transformers Are Effective for Time Series Forecasting”, arXiv:2310.06625)はこの前提を反転させます。時刻をトークンにする代わりに、各変数(チャネル)の時系列全体を1つのトークンとして埋め込み、Attentionを「時刻間」ではなく「変数間」の相関抽出に使い、FFNを各変数トークンの非線形変換に使います。これにより長い lookback window を単純に「トークンの特徴次元」として扱えるようになり、系列長を伸ばしてもトークン数(=変数の数)は増えないため \(O(T^2)\) の系列長ボトルネックを回避しつつ多変量相関を明示的に学習できます。多変量ベンチマークで PatchTST を上回る結果が報告されており、\(O(T^2)\) を「系列長」ではなく「変数間」に押し込めるという発想の転換は 2024〜2026 年の多変量時系列 Transformer 設計に大きな影響を与えています。もう一つの潮流が事前学習済み Foundation Model で、Google の TimesFM(Das et al., 2024, ICML; arXiv:2310.10688)はDecoder-onlyのTransformerを多様なドメインの時系列で大規模事前学習し、ファインチューニングなしでゼロショット予測できることを示しました。個別モデルを学習する本記事のアプローチとは対照的な「1つの事前学習済みモデルを使い回す」路線で、詳細は ML時系列ハブ を参照してください。
PyTorch 最小実装
ラグ窓 → 次ステップ予測の最小モデルを構築します。データ準備は
LSTM
と同じく合成時系列(トレンド + 季節 + ノイズ)を用います。torch.nn.TransformerEncoderLayer はデフォルトで Attention 重みを返さない(need_weights=False の高速パスを使う)ため、後段で重みを可視化できるように nn.MultiheadAttention を薄くラップした自前のエンコーダ層を使います。
import math
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
torch.manual_seed(0)
# (1) 合成時系列:トレンド + 季節(周期50) + ノイズ
rng = np.random.default_rng(0)
T = 2000
t = np.arange(T)
y = 0.01 * t + 2.0 * np.sin(2 * np.pi * t / 50) + rng.normal(0, 0.3, T)
y = (y - y.mean()) / y.std() # 標準化
# (2) ラグ窓に切る
L, H = 64, 1 # 過去 64 ステップで 1 ステップ先を予測
X = np.stack([y[i - L : i] for i in range(L, T)])
Y = y[L:]
split = int(len(X) * 0.8) # train 1548 / val 388
ds_tr = TensorDataset(torch.tensor(X[:split], dtype=torch.float32).unsqueeze(-1),
torch.tensor(Y[:split], dtype=torch.float32))
ds_va = TensorDataset(torch.tensor(X[split:], dtype=torch.float32).unsqueeze(-1),
torch.tensor(Y[split:], dtype=torch.float32))
dl_tr = DataLoader(ds_tr, batch_size=64, shuffle=True)
dl_va = DataLoader(ds_va, batch_size=64)
# (3) Positional Encoding(sin/cos)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1)
div = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div)
pe[:, 1::2] = torch.cos(pos * div)
self.register_buffer("pe", pe.unsqueeze(0))
def forward(self, x): # x: (B, T, d_model)
return x + self.pe[:, : x.size(1)]
# (4) Attention重みを取り出せるエンコーダ層
class AttnEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_ff, dropout=0.1):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
self.ff = nn.Sequential(nn.Linear(d_model, dim_ff), nn.ReLU(), nn.Linear(dim_ff, d_model))
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, need_weights=False):
# need_weights=True でヘッド平均後の (B, L, L) Attention 重みを返す(式2, 3 相当)
attn_out, attn_w = self.attn(x, x, x, need_weights=need_weights, average_attn_weights=True)
x = self.norm1(x + self.drop(attn_out))
x = self.norm2(x + self.drop(self.ff(x)))
return x, attn_w
# (5) Encoder-only Transformer 予測器
class TSTransformer(nn.Module):
def __init__(self, d_in=1, d_model=64, nhead=4, num_layers=2, dim_ff=128, dropout=0.1):
super().__init__()
self.proj = nn.Linear(d_in, d_model)
self.pe = PositionalEncoding(d_model)
self.layers = nn.ModuleList(
[AttnEncoderLayer(d_model, nhead, dim_ff, dropout) for _ in range(num_layers)]
)
self.head = nn.Linear(d_model, 1)
def forward(self, x, need_weights=False): # x: (B, L, 1)
h = self.pe(self.proj(x))
last_w = None
for layer in self.layers:
h, last_w = layer(h, need_weights=need_weights) # 最終層の重みを保持
return self.head(h[:, -1, :]).squeeze(-1), last_w # 最後の時刻だけ回帰ヘッドへ
device = "cpu" # 本記事は CPU 数分以内で完結する軽量設定
model = TSTransformer().to(device)
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()
# (6) 学習ループ(15エポック、CPU上で約11秒)
for epoch in range(15):
model.train()
for xb, yb in dl_tr:
xb, yb = xb.to(device), yb.to(device)
opt.zero_grad()
pred, _ = model(xb)
loss = loss_fn(pred, yb)
loss.backward()
opt.step()
model.eval()
with torch.no_grad():
mse = np.mean([loss_fn(model(xb.to(device))[0], yb.to(device)).item() for xb, yb in dl_va])
print(f"epoch {epoch:02d} val MSE {mse:.4f}")
実際に実行した結果(乱数シード 0、CPU、学習時間 約11秒):
epoch 00 val MSE 0.0258
epoch 01 val MSE 0.0310
epoch 02 val MSE 0.0176
epoch 03 val MSE 0.0110
epoch 04 val MSE 0.0098
epoch 05 val MSE 0.0129
epoch 06 val MSE 0.0071
epoch 07 val MSE 0.0105
epoch 08 val MSE 0.0115
epoch 09 val MSE 0.0074
epoch 10 val MSE 0.0080
epoch 11 val MSE 0.0076
epoch 12 val MSE 0.0144
epoch 13 val MSE 0.0182
epoch 14 val MSE 0.0138
パラメータ数は sum(p.numel() for p in model.parameters()) で 67,137。エポック6が最良(val MSE 0.0071)ですが、エポック12以降でむしろ悪化しています。これは 15 エポック・訓練データ 1,548 サンプルという小規模設定での典型的な過学習の兆候で、本番運用では検証損失が数エポック改善しなければ打ち切る早期終了(後述)が必須であることを実測が裏付けています。
ポイント:
nn.MultiheadAttention(..., batch_first=True)を直接使うことでneed_weights=True時に \((B, L, L)\) の Attention 重み行列を取得できる(nn.TransformerEncoderLayerは内部で高速パス実装を使うため通常はこれができない)- Encoder のみで最後の時刻
h[:, -1, :]を回帰ヘッドに通す設計。窓の中の 64 ステップはすべて「既知の過去」なので、前節で議論した Causal mask はここでは不要(Decoder を足して自己回帰的に複数ステップ生成する場合は必要になる) - 多変量入力は
d_inを増やすだけ。PatchTST 風にしたいならL=64を 8 パッチ × 8 ステップにリシェイプ
Attention重みを可視化する:モデルは何を見ているか
学習済みモデルに検証データを通し、最終層の Attention 重み(式2の \(\mathrm{softmax}(QK^\top/\sqrt{d_k})\)
を全ヘッドで平均したもの)を取り出します。予測を実際に左右するのは Query が「予測対象の直前ステップ」である行(w[:, -1, :])だけなので、これを検証セット全体で平均します。
model.eval()
with torch.no_grad():
attn_accum, full_accum, n = None, None, 0
for xb, yb in dl_va:
pred, w = model(xb.to(device), need_weights=True) # w: (B, L, L)
last_row = w[:, -1, :] # 予測ステップからの注目度: (B, L)
attn_accum = last_row.sum(dim=0) if attn_accum is None else attn_accum + last_row.sum(dim=0)
full_accum = w.sum(dim=0) if full_accum is None else full_accum + w.sum(dim=0)
n += xb.size(0)
attn_avg = (attn_accum / n).numpy() # (64,) 予測ステップの注目分布
full_avg = (full_accum / n).numpy() # (64, 64) 全クエリ×全キー平均
print("直近10ラグ(59〜63ステップ目、最新が最後):", np.round(attn_avg[-10:], 4))
print("最大重みの位置(0=最古のラグ):", attn_avg.argmax(), " 重み:", round(attn_avg.max(), 4))
print("最小重みの位置:", attn_avg.argmin(), " 重み:", round(attn_avg.min(), 4))
実行結果:
直近10ラグ(59〜63ステップ目、最新が最後): [0.0155 0.0152 0.0147 0.0147 0.0147 0.0143 0.0136 0.0129 0.0122 0.0116]
最大重みの位置(0=最古のラグ): 12 重み: 0.0343
最小重みの位置: 49 重み: 0.0077
窓の長さ \(L=64\) なので一様分布なら各キーの重みは \(1/64 \approx 0.0156\) です。実際の分布はこれとはっきり異なり、ラグ位置12(予測ステップから数えて 51 ステップ前)に重みのピーク(0.0343、一様分布の約2.2倍)があり、その付近(ラグ距離48〜54)になだらかな山を作っています。合成データの季節周期は \(P=50\) で生成しているため、モデルは「1周期前の同位相点」を自力で発見し、そこに強く注目していることが確認できます。逆に最小の重み(ラグ位置49、距離14)は谷になっており、周期の半分弱ずれた無関係な位相を弱めていると解釈できます。
全クエリ×全キーの平均 Attention 重み(full_avg)をヒートマップ化すると、この「約1周期前を見る」振る舞いがクエリ位置によらずほぼ一貫していることが視覚的に分かります。
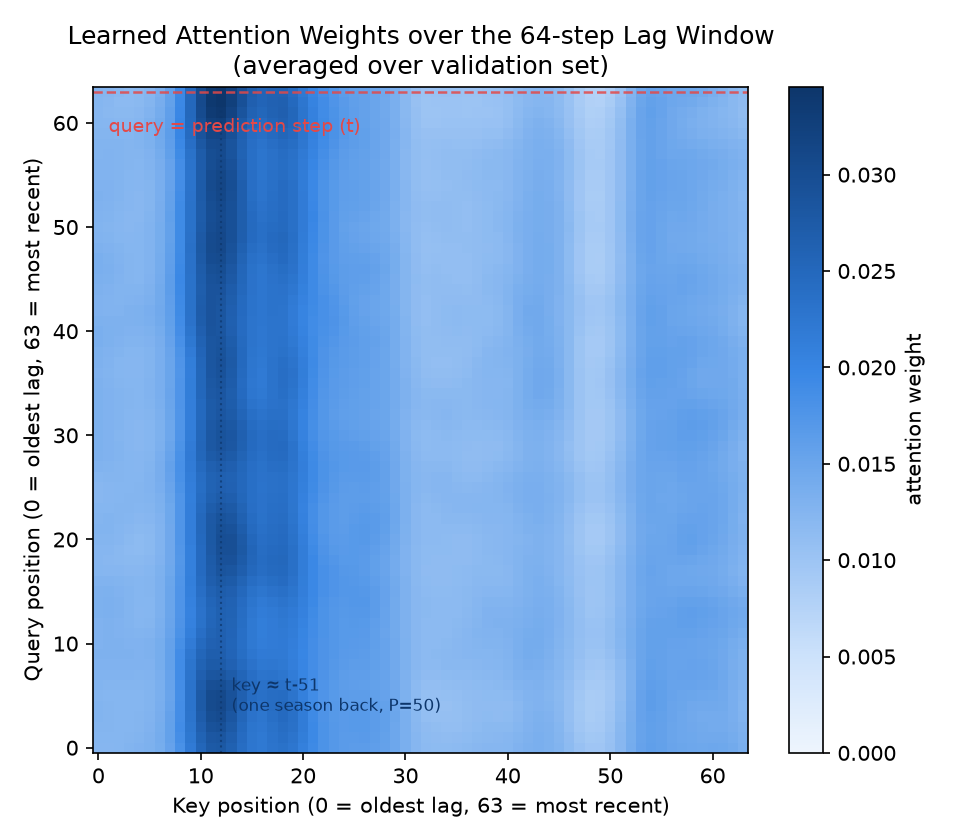
Positional Encoding が「絶対位置」の情報を Query・Key に注入しているからこそ、内容(トレンド+ノイズ)が変わっても位置ベースでこのような周期発見が安定して起こります。これは Self-Attentionの仕組み で見たランダム初期化時の一様に近いヒートマップとは対照的に、実際に学習が周期構造を捉えた証拠です。
LSTM / ARIMA / Transformer 比較表
| 観点 | ARIMA / SARIMA | LSTM | Transformer |
|---|---|---|---|
| モデル種別 | 線形・状態空間 | 非線形・逐次 RNN | 非線形・全結合 Attention |
| 計算複雑度 | \(O(T)\) | \(O(T H^2)\) 逐次 | \(O(T^2 d)\) 並列 |
| 長距離依存 | 弱い(次数で制限) | 中(ゲート機構) | 強い(経路長 \(O(1)\) ) |
| データ要件 | \(\sim 10^2\) 〜 | \(\sim 10^4\) 〜 | \(\sim 10^4\) 〜(事前学習で軽減) |
| 解釈性 | 高(係数 = ラグ寄与) | 低 | 中(Attention 重み) |
| 季節性 | SARIMA で明示 | 暗黙学習 | PE と Autoformer で明示 |
| GPU 並列 | 不要 | 効きにくい | 圧倒的に効く |
| 推奨初手 | 短系列・解釈重視 | 中規模・中期予測 | 長系列・多変量・大データ |
実務では 「ARIMA → GBDT + ラグ特徴量 → LSTM → Transformer」 の順で複雑度を上げ、検証 MSE の改善幅が学習コストに見合うかを毎ステップ確認するのが堅実です。小データなら ガウス過程回帰 で予測区間を出すほうが妥当な場面も多くあります。
実測:同一データ・同一プロトコルで検証する
上記の Transformer と全く同じ合成データ(X, Y, split, dl_tr, dl_va)を使い、
LSTM
と
ARIMA
(2,1,0) を同条件(直前 \(L=64\)
点の真値が既知、1 点先を予測)でフィットします。
from statsmodels.tsa.arima.model import ARIMA
# --- LSTM(Transformerとほぼ同じ学習ループ、同じデータローダを使用)---
class LSTMForecaster(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.head = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.head(out[:, -1, :]).squeeze(-1)
torch.manual_seed(0)
lstm_model = LSTMForecaster().to(device)
opt2 = torch.optim.Adam(lstm_model.parameters(), lr=1e-3)
for epoch in range(15):
lstm_model.train()
for xb, yb in dl_tr:
opt2.zero_grad()
loss = loss_fn(lstm_model(xb), yb)
loss.backward()
opt2.step()
lstm_model.eval()
with torch.no_grad():
preds_l = np.concatenate([lstm_model(xb).numpy() for xb, _ in dl_va])
trues_l = np.concatenate([yb.numpy() for _, yb in dl_va])
lstm_rmse = np.sqrt(np.mean((preds_l - trues_l) ** 2))
# --- ARIMA(2,1,0):1step先walk-forward予測(append(refit=False)で逐次更新) ---
raw_train, raw_test = y[: split + L], y[split + L :]
arima_fit = ARIMA(raw_train, order=(2, 1, 0)).fit()
one_step_preds, hist = [], arima_fit
for i in range(len(raw_test)):
one_step_preds.append(hist.forecast(steps=1)[0])
hist = hist.append([raw_test[i]], refit=False)
arima_rmse = np.sqrt(np.mean((np.array(one_step_preds) - raw_test) ** 2))
# --- Transformer(既出モデルの検証RMSEを同じ指標でまとめて表示)---
model.eval()
with torch.no_grad():
preds_t = np.concatenate([model(xb)[0].numpy() for xb, _ in dl_va])
trues_t = np.concatenate([yb.numpy() for _, yb in dl_va])
tf_rmse = np.sqrt(np.mean((preds_t - trues_t) ** 2))
print(f"ARIMA(2,1,0) walk-forward RMSE: {arima_rmse:.4f}")
print(f"LSTM RMSE: {lstm_rmse:.4f}")
print(f"Transformer RMSE: {tf_rmse:.4f}")
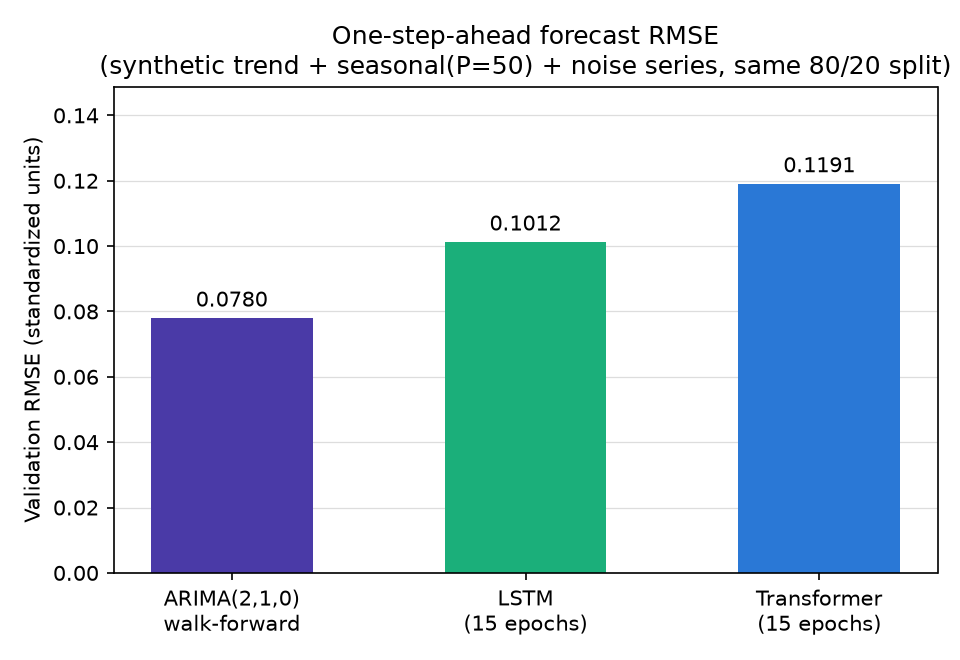
実行結果:
ARIMA(2,1,0) walk-forward RMSE: 0.0780
LSTM RMSE: 0.1012
Transformer RMSE: 0.1191
| 手法 | RMSE | パラメータ数 | 学習時間(CPU) |
|---|---|---|---|
| ARIMA(2,1,0) walk-forward | 0.0780 | 3 | 約2秒 |
| LSTM(15エポック) | 0.1012 | 17,217 | 約5秒 |
| Transformer(15エポック) | 0.1191 | 67,137 | 約11秒 |
この結果は「Transformerは常に強い」という期待を裏切ります。トレンド + 単一周期の季節性 + ガウスノイズという単純な単変量系列・1ステップ予測というタスクでは、パラメータ数が最小の ARIMA(2,1,0) が最良(RMSE 0.0780)、次に LSTM(0.1012)、Transformer が最下位(0.1191)という順位になりました。理由は主に2つです。(1) このタスクは線形の自己回帰構造(\(y_t\) が
\( y_{t-1}, y_{t-2} \)
と正弦波でほぼ説明できる)に対して、ARIMA の帰納バイアスがぴったり一致している一方、Transformer・LSTM は非線形表現力を生かす複雑な構造がそもそもデータに存在しない。(2) 訓練サンプルが 1,548 個・15 エポックという小規模設定であり、前節で見たとおり Transformer は既にエポック6付近で過学習方向に転じている(パラメータ数 67,137 は LSTM の約4倍、ARIMAの2万倍以上)。 LSTMの記事 でも同種の単純な正弦波タスクで ARIMA の walk-forward 予測が LSTM とほぼ互角になることが実測されており、本記事の結果はその知見と整合的です。Transformer の優位性は、多変量・長期依存・大規模データ・複数の重なった周期成分のように、線形モデルの帰納バイアスでは捉えきれない構造がある場合に初めて発揮されることを、この実測は具体的な数値で裏付けています。
過学習・データ量・正則化のコツ
Transformer は表現力が高い反面、データ量に対する飢餓が大きく、素朴に組むと容易に過学習します。
- データ量の目安:単変量 1 系列なら最低 \(10^4\) ステップ、多変量なら系列数 × ステップ数で \(10^5\) オーダーが欲しい。足りなければ PatchTST のチャネル独立化や事前学習済みモデル(Chronos / TimesFM)の Fine-tuning を検討
- Dropout:Attention・FFN 双方に
dropout=0.1〜0.3。Multi-Head の数を増やすほどヘッドあたりのデータが減るので過学習しやすい - Layer Normalization の位置:Pre-LN(残差前に LN)の方が学習が安定。
nn.TransformerEncoderLayer(norm_first=True) - Warmup + Cosine スケジューラ:lr を \(0 \to 1 \times 10^{-3}\) に 1000 ステップで温め、その後 cosine 減衰。Adam 系(特に AdamW)と相性が良い
- ラベル平滑化 / Huber loss:外れ値に強くする
- 早期終了:検証損失が 5〜10 エポック改善しなければ停止。 アンサンブル学習 の early stopping と同じ設計。前節の実測でも、val MSE はエポック6で最小値 0.0071 を取った後、エポック9〜11で0.007台に戻ったものの、エポック12以降は0.0144→0.0182→0.0138と明確に悪化しており、「patience=5」程度の早期終了を入れていればエポック11時点で打ち切れていたはずでした
- ハイパパラ探索:
d_model / nhead / num_layers / lookback / lrは ベイズ最適化 で 30〜50 試行回すと実用域に届く - 入力標準化:時系列は平均・分散が時間で動く(非定常)ので、ラグ窓ごとに標準化する Reversible Instance Normalization (RevIN) が PatchTST で標準
入力特徴量側では、生の値だけでなく 自己相関 のピーク位置をラグ選択に使い、 STL / EMD / VMD でトレンド・季節成分を分離してチャネルとして連結すると安定します。
応用と限界
応用領域
- 長期予測:エネルギー需要・気象・トラフィック。Informer / Autoformer / PatchTST が主戦場
- 異常検知:再構成誤差ベース。 時系列異常検知 の LSTM-AE を Transformer-AE に置換すると長距離パターン崩壊も検出可
- 分類・診断:心電・振動・通信信号。 STFT/CWT スペクトログラムを ViT 風に入力するハイブリッドが強い
- マルチモーダル時系列:テキスト + センサ + 画像。LLM の埋め込みを Transformer 時系列に注入する研究が急増
- Foundation Model:Chronos / TimesFM / Lag-Llama / MOIRAI。ゼロショットで予測できる事前学習済みモデルが 2024 年以降爆発的に登場。詳細は DSP × ML 学習ロードマップ を参照
限界と注意点
- 小データでは負ける:1000 サンプル未満なら ARIMA / GBDT / ガウス過程 のほうが安定
- 計算コスト:\(O(T^2)\) メモリ。\(T = 10^4\) で 16GB GPU を食い潰す。FlashAttention / 疎 Attention で緩和
- 解釈性の幻想:Attention 重みは「説明」ではなく「相関」。SHAP や Integrated Gradients を併用し、 Random Forest の Permutation Importance のような厳密性は期待しない
- 非定常への弱さ:分布シフトに弱い。RevIN・ドメイン適応・オンライン更新( カルマンフィルタ的逐次推定 との融合)が研究領域
- 離散信号処理との接続:サンプリング・エイリアス・窓関数の理解は依然必須。 離散DSP基礎 を踏まえた前処理が品質を左右する
おわりに
Transformer は時系列予測の デフォルト選択肢のひとつ になりつつあり、長距離依存・並列性・多変量への自然な対応で LSTM を多くの場面で凌駕します。一方で「データ量・計算資源・解釈性」のトレードオフは依然として存在し、 ARIMA / GBDT / LSTM / ガウス過程 と適材適所で使い分けるのが実務最適です。
次に深掘りする方向としては、(a) PatchTST / TimesNet の実装と評価、(b) Foundation Model の Fine-tuning、(c) 物理モデルとのハイブリッド( カルマン + Transformer )、(d) 不確実性定量化( ベイズ最適化 や ガウス過程 との接合)が挙げられます。
関連記事
- 機械学習による時系列予測・分類・異常検知ハブ — 本記事の親ハブ
- Pythonで理解するSelf-Attentionの仕組み — Scaled Dot-Product / Multi-Head Attention の数式導出とスクラッチ実装。本記事の Attention 数式のベース
- LSTM による時系列予測 — Transformer の比較対象、ゲート機構と Seq2Seq
- ARIMA・SARIMA による時系列予測 — 線形ベースライン
- ガウス過程回帰 — 小データで予測区間が必要なとき
- アンサンブル学習(RF / GBDT / XGBoost) — 表形式時系列の万能解
- ベイズ最適化 — Transformer のハイパパラ探索
- モンテカルロ最適化(SGD・NN 学習の基礎) — 確率的勾配の理論
- 自己相関とラグ選択 — lookback 長の決定に
- 離散DSP基礎ハブ — サンプリング・離散時間信号の基礎
- 時間周波数解析ハブ(FFT / STFT / Wavelet) — Attention の周波数的解釈
- EMD・VMD・SSA によるモード分解 — Autoformer の Series Decomposition と接続
- 時系列異常検知 — Transformer-AE への自然な発展
- DSP × ML 学習ロードマップ — Foundation Model へのメタ動線
- RTS スムーザ — オフライン平滑化と Encoder-Decoder の対比
参考文献
- Vaswani, A., et al. (2017). “Attention Is All You Need.” NeurIPS 2017. https://arxiv.org/abs/1706.03762
- Zhou, H., et al. (2021). “Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting.” AAAI 2021. https://arxiv.org/abs/2012.07436
- Wu, H., et al. (2021). “Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting.” NeurIPS 2021. https://arxiv.org/abs/2106.13008
- Nie, Y., et al. (2023). “A Time Series is Worth 64 Words: Long-term Forecasting with Transformers (PatchTST).” ICLR 2023. https://arxiv.org/abs/2211.14730
- Liu, Y., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., & Long, M. (2024). “iTransformer: Inverted Transformers Are Effective for Time Series Forecasting.” ICLR 2024 Spotlight. https://arxiv.org/abs/2310.06625
- Das, A., et al. (2024). “A Decoder-Only Foundation Model for Time-Series Forecasting (TimesFM).” ICML 2024. https://arxiv.org/abs/2310.10688
- PyTorch Documentation:
torch.nn.Transformer,torch.nn.MultiheadAttention. https://pytorch.org/docs/stable/generated/torch.nn.Transformer.html
おすすめ書籍
物体検出・セグメンテーション・自然言語処理などTransformer系アーキテクチャの実装をPyTorchで手を動かしながら学べる一冊です。本記事のAttention機構やEncoder-Decoder構造を、コード実装レベルでより深く理解したい場合におすすめです。
※ 上記は Amazon アソシエイトのリンクです。